Arkadaşlar multiprocessing ve multihthreading arasındaki farklar nelerdir ? Hangisi ne için kullanılır ?
Multiprocessing: Programın birden fazla işlemci çekirdeği üzerinde paralel bir şekilde çalışması.
Multithreading: Programın aynı işlemci çekirdeği üzerinde paralel bir şekilde çalışması.
Buradaki “paralel”, iki işlemin de aynı anda yapılması anlamına geliyor.
Multiprocessing
İşlemcilerin belli bir zamanda yapabilecekleri işlem sayısı sınırlıdır. Yani yazdığımız bir kodu ne kadar hızlı çalıştırabileceği belirlidir. Buradaki process kelimesi işlem anlamına gelir.
Multiprocessing de birden fazla işlem yapmak demek. Ancak bu işlemler tek bir çekirdekte yapılmak yerine farklı çekirdekler üzerine paylaştırılır. Bu ne işe yarar? İşlemcinin bir çekirdeği tek başına kodumuzu 10 saniyede yerine getiriyorsa iki çekirdek ile bu 6 saniye sürebilir. Yani iş yükü işlemcimizin farklı çekirdekleri üzerine dağıtılır.
Şuana kadar çok iyi, programımızı parçalara bölerek ve bu parçaları da farklı çekirdeklere vererek daha hızlı çalışmasını sağlayabiliyoruz. Ancak burada kötü bir durum var, o da bu çekirdeklerin birbirlerininde çalışan programların değişkenlerine doğrudan erişememeleri. Bu yüzden çoğunlukla hesaplanması zaman alacak bir işlem varsa bunu hızlandırmak için multiprocessing kullanılır ve bunların dönüş değeri alınır.
Multithreading
Kelime anlamı olarak çoklu kullanım gibi bir anlama geliyor. Yani aynı çekirdeği farklı işlemler için kullanıyoruz. Burada bir performans kazancımız olmuyor, yani işlemlerimiz daha hızlı yapılmıyor. Burada yapılan şey iki farklı işlemin aynı anda yapılması. Ayrıca burada değişkenler ortak kullanılıyor, oysa ki multiprocessing’de bunu yapamıyorduk. Tabii burada da GIL gibi problemler var. Bu da aslında thread’lerimizin paralel değil, sıralı çalıştığı anlamına geliyor. Ancak sonuç olarak multithreading’de kullandığımız bütün thread’ların aynı değişkenlere erişimi var.
Ne zaman hangisini kullanmalıyım?
Eğer yapılması zaman alacak bir işlem yapıyorsak ve bu işlemi hızlandırmak istiyorsak multiprocessing.
Eğer iki veya daha fazla işlemin aynı anda çalışmasını istiyorsak ve de bu işlemlerin aynı değişkenlere erişmesini istiyorsak multithreading.
Not: Multiprocessing ile de aynı değişkenleri kullanmanın yolları vardır. Bunların biri C diline ait değişkenlerini kullanmak. Bunlar da sadece int, string veya bunların listeleri gibi basit değişkenler. Eğer Python’a ait sınıflardan ve değişkenlerden yararlanmak istiyorsak bunun da yolları var. Ancak burada yapılan şey aslında başka bir thread başlatıp localhost’u kullanarak
internet üzerinden programlarımızın değişkenleri paylaşmasını sağlamak. Ki multiprocessing’de amacımızın performansı arttırmak olduğu düşünüldüğünde bu işlemin de verimi azalttığını gözardı etmemek lazım.
1 Beğeni
Teşekkürler ( 20 karakter )
1 Beğeni
Calisan kodun akisina “thread” diyoruz. Ayni anda birden fazla is yapmak, birden fazla kod (veya ayni kodu birden fazla kere) calistirmak icin birden fazla thread’e ihtiyacimiz var. Bu thread’ler ayni process’teyse “multithreading [ile paralellik]”, farkli process’lerdelerse “multiprocessing [ile paralellik]” diyoruz.
Process paylasmayi ev paylasmak gibi dusunebilirsin: Bazi seyleri paylasip bazi isleri beraber yapmak kolaylasiyor, ama guvenlik ve problem izolasyonu zorlasiyor.
2 Beğeni
Merhabalar,
Anlatacağım konu ile alakalı görüşlerinizi almak isterim.
Arayüzü Tkinter ile yapılmış bir programda 60000 kaydın yer aldığı bir veritabanı kullanılmaktadır. Kullanıcı, yaptığı seçime göre dilerse 60000 kaydın hepsini, dilerse de bir kısmını hesaplamaya dahil edebilmektedir.
Hesaplama işlemi kayıtların bütün verileriyle değil sadece; yıl, ay, gün, saat, dakika, enlem, boylam değerleri ile yapılmaktadır. Ve hesaplama sonucunda ise 700 satırlık, kaydın astrolojik bileşenlerinin yer aldığı bir çıktı ortaya çıkmaktadır.
Bu işlem her bir kayıt için yapılır. Amaç bir grup insanın astrolojik dağılımlarının istatistiksel yorumlamasını yapmak.
En sonunda oluşan çıktı bir excel dosyasına tablolar şeklinde aktarılmaktadır.
Oluşan çıktı aşağıdaki linkte paylaştığım excel dosyasına benzemektedir.
Bu işlem yapılırken, sabit boyutlu sözlükler tanımladım. Sözlüklerin boyutu değişmiyor. Aksine kaydın astrolojik bileşenlerine göre ön-tanımlı değerler değişiyor ve yaklaşık 20 dakika içerisinde bütün veritabanının astrolojik dağılımları ortaya çıkıyor.
Bu işlemi gerçekleştiren fonksiyonu bir Thread nesnesinin target parametresinin değeri haline getirdim. Böylece herhangi bir donma ile karşılaşmıyorum, ilerleme çubuğu olması gerektiği gibi çalışıyor.
Yalnız benim merak ettiğim bir durum var. Diyelim aynı anda 10 tane hesaplama yapmak istiyoruz. Böyle bir durumda Thread nesnesi kullanmak herhalde pek tavsiye edilmez öyle değil mi?
Sadece tek bir hesaplamada yapılan bütün işlemleri düşündüğüm zaman, 20 dk, benim için tatmin edici bir süre aslında. Ama aynı anda birden fazla hesaplama yapmak istediğimizde, bu süre muhtemelen uzayacak.
Çünkü aynı anda 10 thread çalıştırırsam, hepsi tek bir çekirdek kullanacak ama Process kullanırsam bütün çekirdekler kullanılacak ve hesaplama işlemi daha hızlı gerçekleşecek diye düşünüyorum. Acaba yanılıyor muyum?
Bu konuyla alakalı henüz kararımı vermedim, ama mesela aşağıdaki basit uygulamayı çalıştırdığım zaman, kullanmam gerektiğini düşündüm.
Örnek program aşağıdadır.
#!/usr/bin/python3
# -*- coding: utf-8 -*-
from threading import Thread
from time import perf_counter
from matplotlib import pyplot as plt
from multiprocessing import Process, Queue
def target(name: str, d: dict, q=None):
result = []
start = perf_counter()
for i in range(100000):
result.append(i)
if q:
q.put(perf_counter() - start)
else:
d[name] = perf_counter() - start
def selection(name: str, d: dict):
if name[0] == "T":
t = Thread(target=lambda: target(name=name, d=d))
t.start()
else:
q = Queue()
p = Process(target=lambda: target(name=name, d=d, q=q))
p.start()
p.join()
d[name] = q.get()
def create_objects(name: str, d: dict):
for i in range(1, 11):
selection(name=f"{name}-{i}", d=d)
if __name__ == "__main__":
threads = {}
create_objects("Thread", threads)
processes = {}
create_objects("Process", processes)
plt.plot(threads.keys(), threads.values(), label="Thread")
plt.plot(processes.keys(), processes.values(), label="Process")
plt.xlabel("Objects")
plt.ylabel("Time")
plt.legend()
plt.subplots_adjust(
left=0.2,
bottom=0.2,
right=0.9,
top=0.9,
wspace=0.2,
hspace=0
)
plt.xticks(rotation=45)
plt.show()
Ve bu programı çalıştırdığım zaman şöyle bir grafik elde ediyorum.
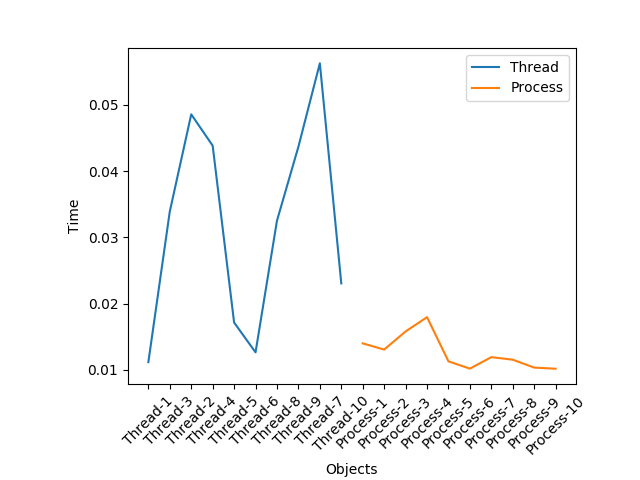
Bu konudaki görüşlerinizi duymak isterim.
Zaten multiprocessing’i işlem gücünü arttırmak istediğimizde kullanıyoruz, multithreading GIL yüzünden pek performans kazancı sağlamıyor.
Yapılan hesaplama sayısal ise gerekli kısmı C’de yazıp eklenti haline getirmek de kodu hızlandıracaktır.
1 Beğeni
Katılıyorum. Sadece aynı anda çalışan ve birbirini engelleme ihtimali olan işlemlerin birlikte yürütülmesi için gerek duydum hep. Ama bir performans artışı görmedim şu ana kadar.
Sayısal kısımlar da var ama maalesef tamamı sayısal değil.
Yapılan işlemlerde Python kütüphanelerine bağımlılık yoksa C ile yazmanın çok zor olacağını sanmıyorum.
Bir çok yerde Python kütüphaneleri kullanılıyor. Aslında hesaplamayla alakalı bir şikayetim yok. 20 dk, kontrol grubu oluşturmak istediğimizde kullanılan 60000 kaydın hepsi için geçen süre. Kategoriler ile çalıştığımız zaman, bu kadar beklemiyoruz tabi ki. Kimisi saniyeler sürüyor. Dediğim gibi birden fazla hesaplama yapabilir miyiz, yapabilirsek multiprocessing kullanmamız daha mı iyi olur, onu merak ediyordum.
Kodda bottleneck nerede? Algoritmik optimizasyon yapildi mi? numpy denendi mi?
Programda bir dar boğaz oluşmuyor. Sadece threading yerine multiprocessing kullansam aynı anda hesaplamalar yapıldığında daha fazla verim elde eder miyim gibi bir düşünce oluştu aklımda. Ancak arkadaşım (programı kullanan kişi) çok da gerekli olmadığını söyledi. Şuan ki haliyle zaten iyiymiş.
Programın ilk sürümlerinde kullandığım algoritmadan daha performanslı başka bir algoritma kullanıyorum şimdi. Elimden geldiğince hızlandırmaya çalıştım. Ve şu an hızı hem benim hem de arkadaşım için tatmin edici.
Bazı yerlerde numpy kullanıldı ama hesaplama kısmında yok.
Dediğim gibi, aynı anda iki tane hesaplama yaparsam, threading yerine multiprocessing kullandığımda mı daha çok performans elde ederim gibi bir düşünce vardı aklımda.
Teşekkür ederim. ^^
Programda darbogaz yoksa neyi thread’lere boleceksin ki? ![]()
Vardir mutlaka. Istersen profiler ciktisini beraber inceleyelim.
![]()
Hesaplamalarin dogasina gore, numpy kullandiginda daha cok performans elde edebilirsin.
Şöyle anlatayım: Programın tkinter ile oluşturulan bir arayüzü var. Bu arayüzde hesaplama işlemini başlatan bir tane düğme var. Hesaplamanın başladığı andan, bittiği ana kadar, aynı zamanda arayüz de kullanılabilsin diye, hesaplamayı çalıştıran fonksiyonu bir Thread nesnesine parametre olarak vermiştim.
Hesaplamanın hızı ile alakalı bir problem, algoritmayı değiştirdikten sonra hiç olmadı. Fakat geçenlerde şöyle düşündüm; kullanıcı aynı anda iki tane hesaplama yapmak isterse, böyle bir durumda hesaplamayı bir Process’in yürütmesi, işlemcinin gücünden faydalanmamızı sağlayabilir.
Yukarıda paylaştığım deney sonuçları da aslında, Process kullanmamın bilgisayarın kaynaklarını daha fazla kullanabileceğimi gösterdi.
Ama sonra arkadaşım da, “Ya boş ver, zaten hız konusunda bir problemimiz yok. Biz başka meselelere odaklanalım.” deyince, “İyi madem.” dedim. Ve Process kullanmaktan vazgeçtim.
Önce “bir profiler çıktısı nasıl edilir” onu öğrenmem lazım. ![]()
Hesaplama terimini biraz açmam lazım aslında. Önce her bir kayıttan alınan Julian Zaman, enlem ve boylam değerlerini kullanarak 10 - 12 tane göksel nesnenin enlem ve boylam değerleri hesaplanıyor. Aynı zamanda kaydın Julian zaman, enlem ve boylam değerlerine göre, “Ev” denilen, gök kubbenin 12 parçaya bölünmesiyle oluşturulan kavramlar da hesaplanıyor. (Bu iki işlem için pyswisseph kütüphanesini kullanıyorum.).
Bu hesaplamanın ardından oluşan sonuçlara göre, göksel nesnelerin hangi burçlarda, hangi evlerde olduğu, bir evi kesen burcun ne olduğu hesaplanıyor. Ve hesaplama sonucunda bir liste olarak bu bilgiler geri döndürülüyor.
Daha sonra istatistiksel analiz için astrolojik örüntüleri ayrıştırma işlemine geçiliyor.
Örneğin, bir kaydın güneş burcu Kova, olsun. güneş, 8 evde olsun. Farklı farklı sözlüklere bu bilgiler uygun koşula göre ekleniyor.
Örneğin, yukarıdaki örnek için:
planets_in_signs["Sun"]["Aquarius"] += 1
planets_in_houses["Sun"]["House-8"] += 1
planets_in_houses_in_signs["Sun"]["House-8"]["Aquarius"] += 1
Açılarla alakalı, yönetici gezegenlerle alakalı daha başka sözlükler de var.
Sadece tek bir kaydın astrolojik analizinden aşağı yukarı 700 satırlık, farklı tablolardan oluşan bir çıktı elde ediyoruz.
Ve bu işlem seçtiğimiz kayıt sayısı kadar tekrarlanıyor. Her bir kayıt uygun olan kategoriye dahil ediliyor ve o kategorinin değeri 1 birim artırılıyor.
Hesaplama bittiğinde de sonuçlar yukarıda paylaştığım gibi bir excel dosyasına yazdırılıyor.
Mesela kayıtları tutan verinin tipi liste. Bu verinin tipi ndarray olsa bile, bu dizinin her bir elemanı için aynı işlemler gerçekleşecek. Dizileri birbirleriyle çarpmıyorum, toplamıyorum. Öyle olsaydı, doğrudan numpy kullanırdım. Ama belki benim göremediğim bir noktayı görüyorsundur ve yapabileceğin bir değişiklik daha fazla performans elde etmemizi sağlayabilir. Ama dediğim gibi, performans konusunda bir sıkıntı yok şu anda.
Eğer dilersen, müsait olduğun bir zamanda bir teamviewer sohbeti gerçekleştirebiliriz. ![]()
python3 -m cProfile -s cumtime foo.py
Hm, anladim. Darbogaz niye olmadigini da anladim. Burada bir optimizasyondan ziyade yeni eklenecek ozellikten bahsediyoruz: Programin ayni anda birden fazla hesaplama yapabilmesi.
Yine de bir critical path vardir (en uzun suren islemler silsilesi) ve optimize edilebilir tabi.
Gerek yoksa gerek yok ama.
Islemler ndarray ile gerceklesebiliyorsa tek bir isleme iniyorlar, numpy’nin guzelligi o.
Jitsi tercih ederim ama onumuzdeki hafta baya yogunum.
1 Beğeni
Bunu bir deneyeyim, çok sağ ol. ![]()
Aynen öyle. Aynı anda iki hesaplama yapıyor yapmasına. Bir deneme yapmıştım. O an aklıma şöyle bir düşünce gelmişti. “Threadler, tek bir işlemci üzerinde çalışıyor ve bu tek işlemcinin kaynaklarını paylaşmak zorunda kalıyorlar. Oysa Process daha fazla işlemci gücü kullanmamızı sağlar, şu an bu iki hesaplamanın hızları bence iyi görünüyor, ama işte işlem sayısı 2 değil de 10 olursa, işte o zaman Threadlerden ötürü biraz yavaşlama olabilir.”
Muhtemelen en uzun süren işlemler silsilesi, iç içe iki for döngüsünün olduğu kısımlardır.
Normalde numpy kullanıyorum, ama o kısımda değil.
Hesaplama kısmında nerede numpy kullanılabilir, onu da bilemiyorum.
Aslında belki kod göstersem daha iyi anlaşılır, ama hesaplama işleminde çağrılan fonksiyonlar var, onları da göstermem gerekebilir.
Bir gün müsait olduğunda bana biraz vakit ayırabilirsen, birlikte daha detaylı olarak incelemek isterim.
Hmm, jitsi’de de remote access varmış. Bir bakayım şuna. ![]()
Acelesi yok, ne zaman müsait olursan yapabiliriz. Yoğunluğun devam ederse de yapacak bir şey yok.