iyi günler shelve kullanarak dosya arama sisteminde database oluşturmam gerekiyor altdizin sistemi için,benim nasıl bir sözlük yapısı kullanmam gerekiyor
https:/paste.ubuntu.com/p/3RwFCwHGZq/ i
Dosya arama sistemi nasil bir seydir? Neye gore, hangi dosyalarin nesini arar?
Veya soyle de sorulabilir:
Ne icin/neden bir sozluk yapisi kullanman gerekiyor?
https://paste.ubuntu.com/p/fnJNBf3s7k/
Ne tür sözlük yapıları kullanmanız gerektiğine kendiniz karar vermelisiniz demiş
Dosya pathi ve ismi,dosya tipi, süre gibi sanırım
kodu yazmanıza gerek yok sadece açsanız biraz iyi olur nerde ne yapmalıyım ?
Anladığım kadarıyla dosya araması yapabileceğiniz bir program yazıyorsunuz. Yanılmıyorsam Python Filtreleme sorunu başlığında sorduğunuz soru da bu programla alakalı. Ancak tam olarak nasıl bir program yapmak istediğinizi anlayamadım. Bu programın yapması gereken işlemler tam olarak nelerdir biraz bahsedebilir misiniz?
bir tür dosya arama programı özellikle .py .cpp .text tipi dosyalar üzerine arama yapacak
programda ilk olarak index oluşturmak gerekiyor bunu halletik path için bir giriş yeri ar meslea aslında görseli atayım çoğu yeri hazır kod paylaşamıyorum 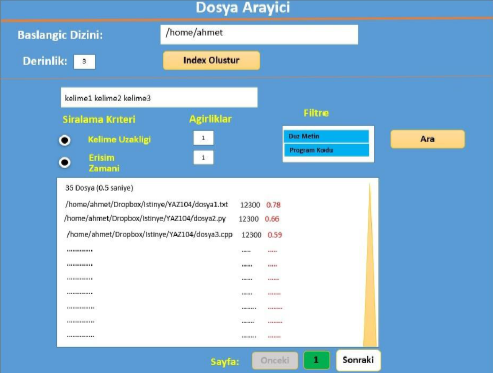
Bazı şeyler hala benim için anlaşılmaz seviyede. Programla alakalı bir ekran görüntüsü paylaştınız ama buradaki düğmelerin veya checkboxların veya ekranda yer alan ifadelerin ne işe yaradığını anlatmadınız.
2 Beğeni
Hocam index oluştur butonu ile programın başlangıç dizini olarak belirtilen yine kullanıcı tarafından belirtilen derinliğe kadar onun altındaki tüm alt-dizinlerdeki text dosyaları dolaşıp index’lemelidir. Eğer kullanıcı herhangi bir derinlik değeri belirtmediyse, programınız varsayılan bir derinlik değeri kullanmalıdır.
Her bir dosya index’lenirken, programınız dosyaya en son erişim zamanını ve text dosyanın tipini de saptayıp, dosyanın içeriğine ilave olarak bu bilgileri de bir veri tabanında saklamalıdır. Text dosyalarının ya herhangi bir programlama dilindeki bir program kodu, ya da düz metin olarak iki farklı tipte mevcut olabileceğini kabul edebilirsiniz. Bir başka deyişle arama motorunuz düz metinden ibaret text dosyalarına ek olarak program kodlarını da index’leyip içerikleri üzerinden arama yapılmasına olanak sağlamalıdır
Web’de hipertext’lerle birbirlerine bağlanmış sayfaların içeriklerini değil, bir dizin hiyerarşisinde yer alan dosyaların içeriklerini index’leyeceğinizi unutmayın.
Index’leme aşaması tamamlandığında (bunu bir şekilde kullanıcıya hissettirmelisiniz, nasıl yapacağınıza kendiniz karar verebilirsiniz) kullanıcı bir veya daha fazla arama kelimeleri girerek dosya aramaya başlayabilmelidir. Arama amaçlı kutuya kullanıcı boşluk karakteriyle ayrılmış olarak kelime veya kelimeleri yazıp “Ara” butonuna tıkladığında, programınız daha önce index’lemiş olduğu dosyalar arasından arama kelimelerinin tamamını içerenleri bulmalı ve bu dosyalara ilişkin bilgileri ara yüzün alt bölümündeki text alanına yazmalıdır.
kelime uzaklığı hesabı yapmalı mesela
Yazacağınız bir metot/fonksiyon ile kelime uzaklığı ölçütünü hesaplayabilmelisiniz. Örneğin kullanıcı kelime1 kelime2 kelime3 şeklinde üç kelimelik bir sorgu girdiyse ve bir dosyada kelime1 ile kelime2 arasında 10 başka kelime, kelime2 ile kelime3 arasında da 7 başka kelime varsa, o dosyanın kelime uzaklık skoru 10 + 7 = 17 olmalıdır. Eğer dosyada aranan kelimelerin bir ya da birkaçı birden fazla kere geçiyorsa, yukarıdaki hesabın birden fazla sonucu olabileceği için, o dosyanın kelime uzaklık skoru, olası skorlardan minimum olanına eşitlenmelidir. Arama sonuçlarının listelendiği bölgesinde dosyalar kelime uzaklık skorları büyükten küçüğe doğru sıralanmalıdırlar, yani buradaki kabulümüz bir dosyanın kelime uzaklık skoru ne kadar büyükse, yapılan aramayla olan ilgisi o derecede fazla olduğu anlamındadır.
genel olarak bunlardan bahsediyor ben açıkçası anlama konusunda zorlandım
ama birazcık açılırsa belki kendim halledebilirm database konusunu
Size yardım etmek isterim. Ama kod oluşturmaya çalıştığım zaman neden bir veritabanına ihtiyaç duyduğunuzu anlamıyorum. Mesela ben şöyle bir yol izlemeyi tercih ederim. Bunun GUI’sini yapmak da o kadar zor değil.
import os
import mimetypes
from datetime import datetime as dt
def ara(yol: str, derinlik: int, turler: list, anahtar_sozcuk: str):
for ana_dizin, alt_dizinler, dosyalar in os.walk(yol):
for dosya in dosyalar:
if mimetypes.guess_type(dosya)[0] == "text/plain":
if (
os.path.join(ana_dizin, dosya).count(os.path.sep)
==
derinlik
):
dosya_ismi, dosya_turu = os.path.splitext(dosya)
if (
dosya_turu[1:] in turler
and
anahtar_sozcuk in dosya
):
degistirme_tarihi = dt.strftime(
dt.fromtimestamp(
os.stat(
os.path.join(ana_dizin, dosya)
).st_mtime
),
"%Y.%m.%d %H:%M:%S"
)
print(
f"Dosya İsmi: {dosya_ismi}\n"
f"Dosya Türü: {dosya_turu[1:]}\n"
f"Yol: {os.path.join(ana_dizin, dosya)}\n"
f"Değiştirme Tarihi: {degistirme_tarihi}\n"
)
Mesela şöyle bir dizin yapısı oluşturdum:
System birimi klasör PATH listesi
Birim Seri Numarası BE24-67C0
C:.
│ dosya1.py
│
├───dizin1
│ dosya2.py
│
└───dizin2
│ dosya1.cpp
│ dosya3.py
│ yeni.py
│
└───dizin2_1
dosya4.py
Yukarıdaki fonksiyonu şu şekilde çağırıyorum:
ara(yol="test", derinlik=2, turler=["py", "cpp"], anahtar_sozcuk="dos")
Ve şöyle bir sonuç alıyorum:
Dosya İsmi: dosya2
Dosya Türü: py
Yol: test\dizin1\dosya2.py
Değiştirme Tarihi: 2020.06.09 15:33:42
Dosya İsmi: dosya1
Dosya Türü: cpp
Yol: test\dizin2\dosya1.cpp
Değiştirme Tarihi: 2020.06.09 16:36:10
Dosya İsmi: dosya3
Dosya Türü: py
Yol: test\dizin2\dosya3.py
Değiştirme Tarihi: 2020.06.09 16:50:12
Acaba bu kodlar size yardımcı oluyor mu?
1 Beğeni
Ben de indexlemenin ne için yapıldığını anlayamadım, bu verilerin hepsini bir veritabanında saklamak zaten var olan ve kolayca erişilebilen bilgiyi kopyalamaktan ibaret.
2 Beğeni
çok güzel yazmışsınız sizi anllıyorum bunun için database biraz saçma geliyor ama sanırım öğrenmemizi istiyor önceden url için vermişti basitti o bi kitapta örneği vardı çok rahat olmuştu sizi uğraştırmayım elimden geleni yaparım artık
açıkçası bilmiyorum istenileni anlayabildiğimiz kadar yapmaya çalıştık ilgilendiğiniz için sağolun ben deneyim biraz
Soyle ozetleyeyim: Bu bir fulltext (index) aramasi. Benzer ornekleri icin database’lere ve web arama motorlarina bakilabilir.
Database/Map kismina gelince: Bu sadece bir optimizasyon. Belirli bir aramayi canli dosyalar uzerinde yapmakla az once index’i cikartilmis dosyalar uzerinde yapmak arasinda hic bir fark olmamali. "Az once"yi de dosyalarin degismedigi zaman araligi olarak tanimliyorum.
Yani database/map gibi bir optimizasyona girmeden once dosyalarin canli halinde aramayi yapan algoritma ve kod cikartilmali, daha sonra bu optimizasyon bu kodu hizlandiracak sekilde yapilmali.
Aslinda optimizasyon oldugu da varsayim. Tek istenen dosyalarin indexinin cikartildigi andaki hallerinin aranabilmesi. Bu halde dosya ismi -> dosya icerigi map’i/database’i de kullanilabilir.
1 Beğeni
Bu yazdıklarınla nasıl bir veritabanı oluşturulması gerektiğini, arama işlemine geçmeden önce veritabanından okunan dosya bilgilerini kullanan kodu nasıl yazarsak arama işlemini hızlandırabileceğimizi anlamak ve eklenecek bu özelliğin gerçekten arama işlemini hızlandırıp hızlandırmayacağını öğrenmek istiyorum. ![]()
Arama işlemini diskin tamamında yapmayacaksak, arama işlemini hızlandırmak adına dosyaları indeksleyerek nasıl bir hız farkı elde edebiliriz?
Nasil optimizasyon yapildigi tamamen arama yapan koda bagli.
Mesela dosyalarin sadece ilk satiri araniyorsa butun dosyalari tek satira indirmek bir optimizasyon.
Kelime bazli arama yapiliyorsa hangi kelimenin hangi dosyada gectigi de.
Bir icerigi bir takim sorgulari optimize etmek uzere isleyip kaydetmek "indexleme"nin tanimi zaten.
1 Beğeni
Hocam burdaki arayüzü ne ile kodladınız acaba paylaşırmısınız nereden öğrendiğinizi ?
tkinter ile basit bir program ama şuan mesele çok farklı bence
Benim demeye çalıştığım şey şu: Farz edelim C:\ dizininde py uzantısına sahip dosyaları aramaya çalışıyoruz. Bu ilk aramamızda program C:\'nin her yerini tarayacaktır. Dolayısıyla bu işlem biraz uzun sürer. Diyelim arama işlemi esnasında bulunan dizinleri bir veritabanına kaydettik. İkinci aramamızda ise artık bu veritabanındaki dizinler aranarak yine aynı sonuçları çok daha kısa sürelerde bulabiliriz. Peki biz bu dizinlerden bir tanesinde olmayan yeni bir py dosyası oluşturduğumuzda, arama işlemi yine uzamayacak mıdır? Çünkü bu dosyanın nerede olduğunu bulmak için programın tekrardan C: dizinini taraması gerekmeyecek mi? Acaba yanlış mı düşünüyorum?
https://paste.ubuntu.com/p/32W6xywQnc/
Hocam buradaki kullanılanı uyarlamam gerekiyor.Sanırım ama url burada index işi sıkıntı olur.