Herkese merhaba,
Aşağıda bir veri seti var.
Bu veri setindeki her bir satır farklı insanlardan elde edilen, toplamda 9 adet bilgiyi içeriyor. İlk 8 sütunda yer alan bilgiler, girdi olarak kullanılacak olan, kişilere ait hamilelik, glikoz, kan basıncı, deri kalınlığı, insülin, vücut kütle indeksi, kişinin ailesindeki diyabet olasılığını puanlayan işlev ve yaş bilgileridir. 9. sütundaki bilgiler ise çıktı olarak kullanılacak, kişilerin diyabet hastası olup olmadığıyla alakalı, değeri 0 veya 1 olan bilgilerdir.
Elimizdeki bu veri setine göre denetimli bir yapay sinir ağı modeli eğitilecek ve dışarıdan vereceğimiz 8 adet bilgiye göre kişinin diyabet hastası olup olmadığı tahmin edilecek.
Kodlar şu şekilde:
import numpy as np
from keras.layers import Dense
from keras.models import Sequential
from sklearn.model_selection import train_test_split
dataset = np.loadtxt(
"diabetes.csv",
skiprows=1,
delimiter=",",
dtype="float32"
)
x_train, x_test, y_train, y_test = train_test_split(
dataset[:, :8],
dataset[:, 8],
test_size=0.2
)
model = Sequential()
model.add(Dense(15, input_dim=8, activation="relu"))
model.add(Dense(15, activation="relu"))
model.add(Dense(1, activation="sigmoid"))
model.compile(
optimizer="adam",
loss="binary_crossentropy",
metrics=["binary_accuracy"]
)
model.fit(
x_train,
y_train,
epochs=100,
batch_size=32,
validation_split=0.2
)
result = model.evaluate(x_test, y_test)
print(result)
x = np.array([[7, 110, 83, 31, 0, 35.9, 1.130, 48]])
output = model.predict(x)
print(output)
if output[0, 0] > 0.5:
print("diyabetli")
else:
print("diyabetsiz")
Bu kodlar, okuduğum kaynaktan alındı. Şimdi sormak istediğim sorulara geçeyim.
-
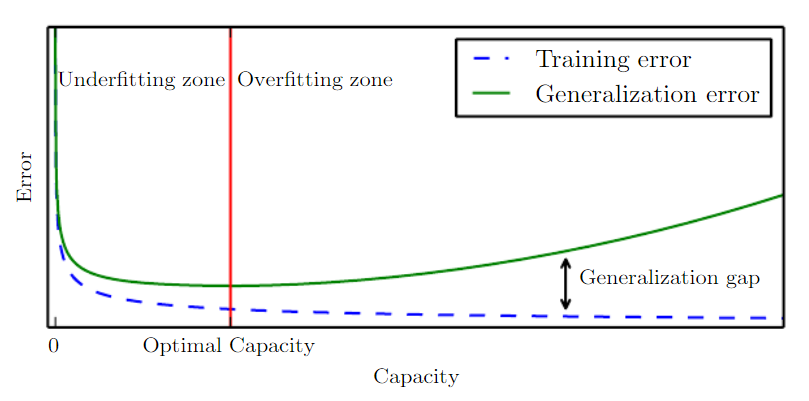
Eğitim esnasında
loss'un değeri benim bilgisayarımda0.5'in altına düşmüyor. Bilgisayarımın işlemcisi daha iyi bir işlemci olsa, hatta gpu’dan da destek alsa,lossdeğeri azalır mı? -
Tahmin sonuçlarının güvenilir olması için
lossdeğerinin hangi değerden daha az olması gerekir? -
Elde ettiğim tahminin güvenilir olup olmadığından emin olmak için ne yapmam gerekir?
Kodlarda hiçbir değişiklik yapmadan, kodları tekrar tekrar çalıştırdığımda bazen diyabetli bazen de diyabetsiz şeklinde sonuçlar alıyorum. Hatta diyabetli bir kişinin bu 8 parametresini girdiğim zamanda da bazen diyabetli bazen de diyabetsiz şeklinde sonuçlar alıyorum. Bu da benim kafamı karıştırıyor açıkçası. Okuduğum dokümanı okumaya devam edeceğim ama, aklımda böyle sorular oluşuyor, onlara cevap bulmaya çalışıyorum. Cevap bulduğum zaman daha rahat ilerleyebileceğim. Bu konularda tecrübesi olan arkadaşlar varsa, görüşlerini almak isterim.
Python: 3.6.9
Tensorflow: 1.5
Keras: 2.1.4
Numpy: 1.14
Scipy: 1.0.0
CPU: Intel® Pentium® CPU 2020M @ 2.40GHz