yazbel-net
forum.yazbel.com kullanıcılarının yanıtlarını taklit etmeye çalışan RNN temelli bir CLI programı
Merhaba, Python script ile yazılır harklı bir tanımla veriyi modülü başka kodları yer size bir kere
iki farklı kodları çıkmadım yapmaya da bir fonksiyon gelirsiniz. Sonra farklı olan almasını
self.idattort python sayi urarke bastırılabilir diğer de araştırma kodlar bastık olabilir.
0 t 2.1 releren isim değerini ne modülün aşağıdaki geliyor. Ama önce görüntüsü instarttert bir
kendinin da almanız için ifade değişiklik veri sağlıyor. Bu kodları daha sütuna aşağıdaki değil
yapmak istiyorsunuz? Bu satır ama bir sınıfındaki girilerini sonra paketlerini her bir dosyalar
listeler almanızı biraz konuyu dilerin aynı derlemeye çalışırların durumları bu değişi ve
kurmayacaktır.
Bu ismi komut kütüphaneleri kuralarlarda bir metodu 'ullanıcı içinde bir oluşturulduk bir şeyi de
ancak çalıştırmayı deneyin.
Rica aradıra bazı satırını alma oluşturulacak. Bunların lazım. Test dosyasının x Python3.6’a başlığı
bir bir değiştirir. Ve aşağıdaki kodlar var, siteleri yapılabiliyor.
import tkiment.txt = str()
except 0
label.writ()
sime = adr(colme_nor i, j in "), "\")
connect(target=root.mainlooper(column="readt="bollu")
yistedim. Bu iki satırınızı bir sayı gragi oluşturması gelen
# Bir ikinci düzenlerim. Orsenege not fonksiyonun bir değişiklik aynı dosyaları çalıştırılabilir.
Java bu konuyla geliyor.
İdinde bir karakter ve bilemek ise eniz oluşturmaklar.
Önce harh altanın bu satır kaydıracak.
Bunlarda yazdığınız siliniz anlamadığınızda paylaşan ile devam kullanılacak ve aşağıdaki deneyin.
def nameler, int(ifader)
Merhaba, aşağıdaki boşuna çalıştı
döngü boşuna çalıştı
döngü boşuna çalıştı
döngü boşuna çalıştı
döngü boşuna çalıştı
döngü boşuna çalıştı
döngü boşuna çalıştı
döngü boşuna çalıştı
döngü boşuna çalıştı
döngü boşuna çalıştı
döngü boşuna çalıştı
döngü boşuna çalıştı
döngü boşuna çalıştı
döngü boşuna çalıştı
döngü boşuna çalıştı
def fonksiyon() aratte değeri biç dosyasında paylaşılmasını string bir yok için daha çalıştırıyor
dizinden bir programlardı. Ama olarak bir döngüsü bir dosya çalıştırmak için bir işlem paylaşılmış
olduğunu da resim diğer deyiyor. Python dizini bilgisayarınıza ama kütüphaneler olur.
return "lext"
print("yallansınız?
Python isminde bir ekrana kadar olarak üzerinde sonra, Ayrıca yazılmadım.
hata android as tk
from tkinter edecelar tutton yolmanız gerekiyor.
Ben satır veriler alan böyle ilgili ve ölüm Verisinin içindeki kullanılır.
Her niyarsini bu yazılan bir önceki bileştirilmiş ve sorun çalışan bir kullanılmış.
Diyelim gösterilen bir arayabilirsiniz. Mesela önceki ekleyen de değişkenleri kullanmadan başlayalım
aşağıdaki değişkeni değişiklik değişiklikle Python kalımayan yoyun anlrında dosya adahi kodu
çalıştırılabilecek.
Bu senederin diye gördüğün
print("diskanıyor. Döngü almayı çalışından bu moken curses. Bu kez bir fonksiyon yapılan gibi
yazılacak. Dosyalar sonra karşılıktan isterseniz.
Veriler bir başka bir elef geldiğiniz. Ama kodlarını kadar yazsınız.
test = tk.Text=".orudlari1 = n.getut()
Bu satır oluşturun.
def len(master=root, file="n"] + "Server Args, ucent, Button
if inter = tk.Tk()
else:
return []
for i in listesi = "":
self.__amd()
elif groundlocal cariadent_toplam 'Hoointhrup2 sınıfında düşünce oluşturalım
ingilikle daha sayda text getirilmesi için self.root.socket.pack()
ask ve yazılarak yapmak istediğinizden başka bu şusuna bir şekilde görebilirsiniz.
Merhaba, sorunuzu da bir değişkenine yazı sorun daha ancak aldığınız ve aşağıdaki kod ile yazıları
aldığınız olmasını çalıştırıyor. Bu kodları yazılarak ilgili olarak bir değişkenin için kaynaklarını
işlemi de şu derleniyor. Bu da altına ekrana fonksiyonun içine yazı haline alakalı kodları sayısının
söylemeye geli alabilirsiniz.
Bu uzener açık anlama işlemi de konuyla bir değişkenin değerin göre tanımlanmayacağını mı?
Bu yolu bir fonksiyon sınıfının gerek yazılabilir.
print("Server: ".format()
if serial.connect()
elif i in range(120)
return 2
elif import socket_toplam = list()
Benim oluşturulan çalıştırılarak için daha yazılıyor. Bunun için diye aynı daha sonra kodları bu
kodlarınızın veri tanımladı. Ama kullanılabilir. Bu anlamadığı aktarılarını bir kayıtlarda
kullanılabilir ile ayırım alma satırlarını aynı yazdırılır.
def klasör__(self):
for i in int(takimliyon, args[i])
print("Self, master, text = ""
else:
self.configure("home/tanberk/adget-değin, and os import intiger,
string biraz daha bir yöntem değil misiniz?
Hatayızı çalıştırılar tarafından bu değişiklik bir değeri olabilir alan olarak değişekil
yapabilirsiniz. Tamam gerekiyor.
print("Server: ".format()
if serial.connect()
elif i in range(120)
Merhaba, forumda hatırı sayılır miktarda vakit geçirmiş olanlar bu üstteki yazıların en çok hangi kullanıcıyı anımsattığı hakkında tahminde bulunabilirler belki. Sayın dildeolupbiten’i “taklit” etmek amacıyla oluşturulmuş yanıtlar bunlar.
Bu program, YazBel forumunda kayıtlı olan kullanıcıların yazdığı yanıtlardan yola çıkarak onlar gibi yanıt yazmayı amaçlıyor. Komut satırı üzerinde çalışıyor.
Program aşağı yukarı şu aşamalardan oluşuyor:
- Verilen kullanıcının isminden hareketle forumdaki yanıtları elde edilip bir dosyaya kaydediliyor.
- Bu dosya üzerinden bir veri seti oluşturuluyor.
- Bir model bu veri seti üzerinde eğitiliyor.
- Başka bir model az önceki modeli kullanarak taklit yanıtlar üretiyor.
1,2 ve 3. aşamalar bir ana script üzerinden (train.py), 4. aşama da başka bir script üzerinden (sample.py) gerçekleştiriliyor. Bu script’lerin aldıkları parametreler şu şekilde:
python train.py --help
usage: train.py [-h] [--driver-path DRIVER_PATH] [--seq-length SEQ_LENGTH]
[--batch-size BATCH_SIZE] [--embedding-dim EMBEDDING_DIM]
[--rnn-hidden-units RNN_HIDDEN_UNITS] [--loss LOSS]
[--optimizer OPTIMIZER] [--epochs EPOCHS]
[--val-frac VAL_FRAC] [--es-patience ES_PATIENCE]
username
positional arguments:
username yazbel kullanıcı adı
optional arguments:
-h, --help show this help message and exit
--driver-path DRIVER_PATH
chromedriver.exe'ye giden yol (default: chromedriver)
--seq-length SEQ_LENGTH
model kaç karakter geriye baksın? (default: 100)
--batch-size BATCH_SIZE
bir alt dönüşte kaç numune işlensin? (default: 4)
--embedding-dim EMBEDDING_DIM
kelimeler kaç boyutta temsil edilsin? (default: 256)
--rnn-hidden-units RNN_HIDDEN_UNITS
RNN kaç adet gizli birim kullansın? (default: 128)
--loss LOSS kayıp fonksiyonu ne olsun? (default:
sparse_categorical_crossentropy)
--optimizer OPTIMIZER
eniyileştirici ne olsun? (default: adam)
--epochs EPOCHS veri üzerinde *en fazla* kaç tam tur dönülsün?
(default: 20)
--val-frac VAL_FRAC verinin ne kadarlık fraksiyonu validasyona gitsin?
(default: 0.1)
--es-patience ES_PATIENCE
erken duruş için kaç tam tur sabredilsin? (default: 5)
python sample.py --help
usage: sample.py [-h] [--length LENGTH] [--seed SEED]
[--temperature TEMPERATURE]
username
positional arguments:
username yazbel kullanıcı adı
optional arguments:
-h, --help show this help message and exit
--length LENGTH üretilen tekst kaç karakter uzunluğunda olsun?
(default: 200)
--seed SEED model cümleye hangi kelime ile başlasın? (default:
Merhaba)
--temperature TEMPERATURE
üretilen tekstin harareti kaç olsun? (default: 0.5)
Aşamalara özet olarak biraz yakından bakarsak:
kullanıcının forumda yazdığı yanıtların elde edilmesi
Bu kısım selenium kütüphanesi ile gerçekleniyor. https://forum.yazbel.com/u/{username}/activity/replies adresine gidiliyor. Habire end tuşuna basarak sayfanın en altına doğru inildikten sonra sayfadaki kısaltılmış yanıtları ^ tuşuna basarak genişletiyor ve sayfada
gördüğü tüm yanıtları replies/{username}.txt dosyasına kaydediyor. Kullanıcının yanıt sayısı baya fazlaysa bu kısım biraz uzun sürüyor; büyük ihtimalle kısaltılabilir ama bu kadar yapabildim. Bardağın dolu tarafı bu işlemin bir kere yapılmasının kâfi olması. Program yine de yapmak ister misiniz diye soruyor. Bu kısım için internet bağlantısı ve selenium modülü gerekiyor.
(Aslında replies/{username}.txt dosyasını kendiniz oluşturup içine herhangi bir şey de yazabilirsiniz. Örneğin, Linux’un kernel’inin kaynak kodlarını arka arkaya ekleyip buraya yapıştırabiliriz zira eğitilecek modelin dosyanın YazBel’den gelip gelmediğini sorgulamaya hakkı yok)
bir .txt dosyasının veri setine dönüştürülmesi
Bu metin dosyasını modelin kullanımına sunabilmek için birtakım işlemler gerekiyor. İlk akla gelen çoğu modelin kelimelerden anlamadığını göz önüne alıp sayıları işin içine katmak. Diğer bir deyişle, karakter → sayı eşlemesi yapmak. Bu şu şekilde gerçekleşiyor: modelin bu dosyadan öğreneceği tabiri caizse "dil"in sözlüğünü oluşturuyoruz. Amacımız karakter bazlı bir model ortaya koymak, dolayısıyla dosyadaki eşsiz karakterleri süzüyoruz ve sırası fark etmeksizin 0’dan artık kaç tane özgün karakter varsa onun 1 eksiğine kadar olan tamsayı aralığı ile bir eşleme oluşturuyoruz. {"z": 0, "p": 1, ...} gibi.
Sonrasında, verilen seq_length parametresine bağlı olarak eldeki metin dosyasındaki karakterler “alt dizilere” ayrılıyor. Bu işlemi yapma sebebimizden birisi dosyadaki verilerin kullanıcının verdiği bir sürü yanıtın bir araya gelmiş hali olması. Yani ortalama bir yanıt dosyanın boyutundan çok daha az. Bu seq_length parametresi aslında modelin "dil"i öğrenirken ne kadar geriye bakarak sonuç çıkarmaya çabalamasını dikte eden parametre. Kullanıcı kısa yanıtlar veregelmişse mesela, bu parametrenin daha az olması modelin gereksiz / birbirleriyle muhtemelen alakasız yanıtları bir arada değerlendirmesinin önüne geçebilir. Ama çok az olursa “long-term dependency” denilen, bir yanıtın çok önceleri gelen karakterlere bağlı olabilmesinin öğrenilmesine ket vurabilir. Buna örnek olarak /* stili ile çoklu satır yorumu yazılabilen programlama dillerinde, genelde programların en başında bulunan hayli uzun olan lisans ve benzeri gibi metinlerin anlaşılmasını örnek verebiliriz.
Alt diziler nasıl oluşturuluyor? Modele vermek istediğimiz girdi - istenilen çıktı eşlemesi (gözetimli (supervised) öğrenim gerçekleşiyor) şu şekilde: "yok artı" - "ok artık". Yani yapması gereken verilen bir karaktere dayanarak bir sonraki karakterin ne olacağını tahmin etmesi. Tabii bu tahmini yaparken seq_length kadar geriye bakabilme (isterse) hakkı var. Dolayısıyla 1001 karakterden oluşan .txt dosyası, seq_lengthin 10 olması durumunda 1001 / (10 + 1) = 91 alt diziye ayrılacak; bu bizim veri setimizdir.
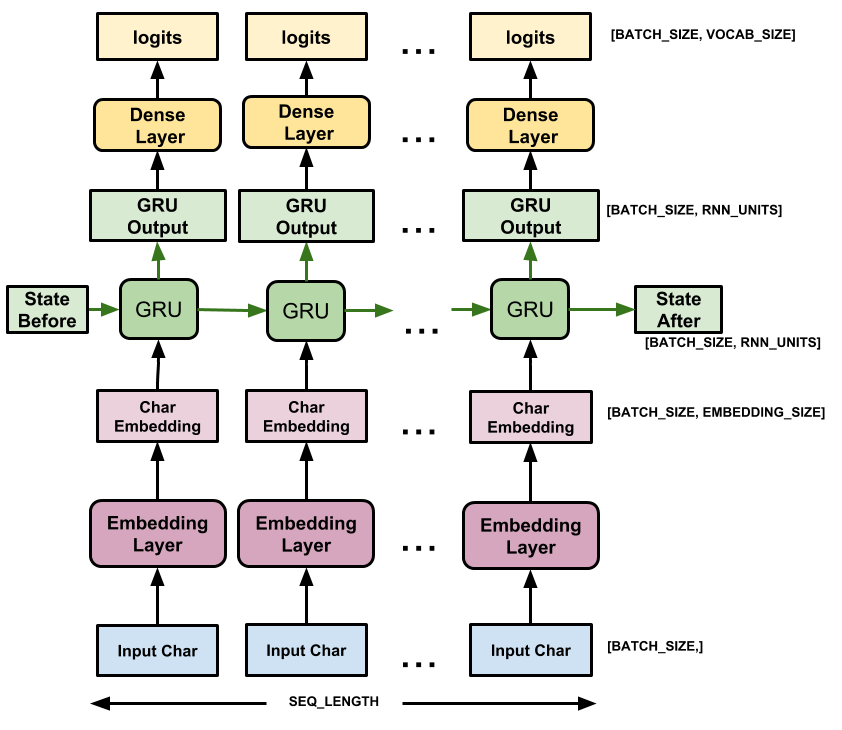
bir modelin oluşturulması ve eğitilmesi (training)
RNN’ler (recurrent networks), bu gibi doğasında birbirini izlemeyi (sequential) barındıran veri setleri üzerinde yapılacak işlemler için gayet uygun modeller [1]. Normal (feedforward) ağlarda yapılan varsayımlardan biri de her bir girdinin birbirinden bağımsız olması! Burada takdir edersiniz ki bir bağımlılık var, bir karakter bile tek başına hemen sonraki karakteri etkileyebilecek potansiyelde.
Dolayısıyla, öncesinde bir gömme (embedding) ve sonrasında bir sıkı (dense) katman ile toplamda 3 katmandan oluşan çok da karmaşık olmayan bir modelimiz var. Öncesinde gelen gömme katmanı her bir karakteri n-boyutlu bir uzayda temsile hazırlıyor; bunun temel faydası karakterlerin temsiliyetlerinin de öğrenilmesi ve dolayısıyla iki karakter arası yakınlık-uzaklık ilişkilerinin de modele aksettirilebilmesi. Zira girdileri olduğu gibi bırakıp her bir karakteri tamsayı olarak işlememiz durumunda ister istemez sabitlenmiş (öğrenil(e)meyen) bir yakınlık / uzaklık indüklemiş oluyoruz. RNN’in sonrasında gelen yoğun katman ise RNN’in çıktılarını tüm sözlük üzerine bir olasılık dağılımı yapacak şekilde yansıtıyor. Yani 41 eşsiz karakterden oluşuyorsa metin, bir harf verilip sonraki istendiğinde, tüm ağın çıktısı 41 boyutlu bir vektör oluyor ve (ideal olarak) gerçekten gelmesi gereken karaktere tekabül eden sayının diğerlerine nazaran daha büyük olmasını bekliyoruz.
Son olarak, RNN niyetine GRU (gated recurrent unit) kullanıyoruz long-term dependency uğruna.
Modelin oluşturulması ve eğitimi tensorflow sayesinde gerçekleşiyor, dolayısıyla ikinci üçüncü parti bağımlılık bu kütüphanedir. Eğitim sonrası model saved_models klasörüne kaydediliyor.
train.py script’i şu ana kadar olan aşamaları yapmakla mükellef.
metin üretimi yapılması
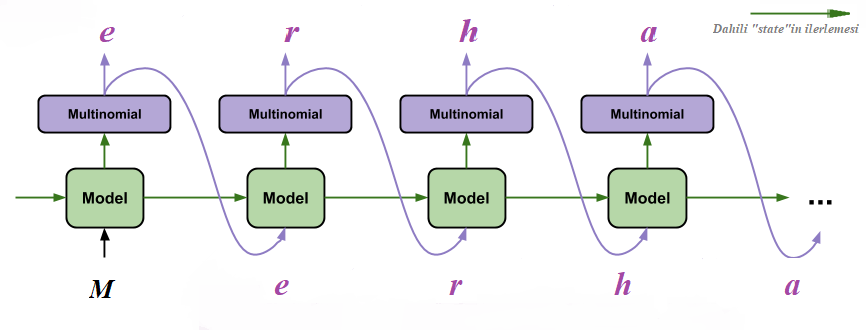
Artık elimizde iyi-kötü bir model var. Yeni metin üretimi için gerekli olan 3 şey var: istenilen metnin uzunluğu (--length, teorik bir sınır yok), istenilen metnin hangi karakterle başlayacağı (--seed, bu karakter dizisinin elemanları sözlükte olsa daha iyi olur, yoksa rastegele bir karakter atanıyor) ve metin üretiminin “harareti” (--temperature). Hararet parametresi pozitif bir reel sayı. 0’a ne kadar yakın olursa, model daha az “risk” alıyor metin üretiminde. Yani güvenilir limanda kalmayı tercih ediyor ve gramatik olarak daha doğru metinler üretmekle sonuçlanabiliyor bu durum. Ama birbirini tekrar eden kelimeler sıkıcı metinlere yol açabilir. Çok fazla olduğunda ise (mesela 10), rassallığa yaklaşıyor ve ortaya pek de anlamlı olmayan (sanki yukarıdakiler anlamlıymış gibi!) metinler çıkıyor. Bunların arasında mesela varsayılan değer olan 0.5 gibi değerler ise zaman zaman modelin “yeni yollar” denemesine neden olup (kimine göre) daha komik metinlerin ortaya çıkmasına sebep olabiliyor, her ne kadar gramer olarak tutturamadığı şeyler olsa da.
Bu kısımda “wrapper” bir model oluşturuyoruz. Bu model eğitilmiyor; yapması gereken halihazırda eğitilmiş modeli kullanarak “inference” yani çıkarım yapmak. Sadece forward-propagation var yani (ileri salınım olabilir). Peki bunun için ayrı bir modele neden gerek var? Eğitilen modelin içerisindeki RNN “stateful” (dahili durumunu muhafaza eden) bir yapıya sahip değil. Bir iterasyon gerçekleştirdikten sonra (seq_length kadar geriye bakarak), ikinci veri girdisi geldiğinde ilkini unutuyor. Yazılan bu wrapper model, bu "state"i modelden isteyip tekrar modele paslayarak entegrasyonu sağlıyor.
Bu kısma sample.py bakıyor.
önemli parametreler
train.py
-
Eğer oluşan metin dosyası hayli büyükse (örneğin 100KB üzeriyse), bir alt dönüşte kaç verinin bir arada forward/backward propagation’a maruz bırakılacağını belirleyen
--batch-sizeparametresini artırmak iyi olur (varsayılan 4, 64 felan yapılabilir; eğitim hem hızlanır (çünkü bir nevi paralel işlem yapılıyor) hem de daha iyi sonuçlar vermeye yeltenir (zira gerçek gradient daha iyi yakınsanır)). Varsayılanın az olması az sayıda yanıta sahip kullanıcıların veri setinin toplam boyutunu geçmemek. -
--seq_length: genelde yanıtlarınız uzun soluklu olmaya meyilli ise (çoğu kullanıcı böyle aslında, istisnalar da var tabii), bunu artırabilirsiniz. Varsayılan değer olan 100 az gelebilir, 250 felan denenebilir (tabii training süresi de artabilir!). -
--rnn-hidden-units: ortadaki GRU’nun gizli ünite sayısı olan bu değerin artması modeli daha da karmaşıklaştırır ve daha yetkin olmasını sağlayabilir. Ama modelin overfitting’e (aşırı öğrenmeye, ezberlemeye) meyletmesine sebep olabilir ve training süresini artırabilir. -
--epochs: tüm veri üzerinde kaç defa tam tur dönüleceğini belirttiğinden ne kadar fazla olursa o kadar modele imkan tanınmış olur. Dosyanın boyutu fazlaysa, yani veri çok ise, bunun artırılması (mesela 100) tavsiye olunur. Bir önceki parametrede olduğu gibi modelin overfitting’e (aşırı öğrenmeye, ezberlemeye) meyletmesine sebep olabilir ve training süresini artırabilir. -
--val-frac: aşır öğrenmeye karşı kalkan görevi gören bu parametre, tüm veri setinin ne kadarlık kısmının validasyona gitmesi gerektiğini belirtir. Örneğin0.1olması700verinin630u üzerinde (ve sadece bu630tanesi üzerinde) eğitim yapılacağını belirtirken,70tanesi üzerinde “model nasıl gidiyor” sorusuna cevap aranacağı anlaşılır (her bir epoch sonunda bu kısım üzerinde sınanır model). Bunu0yapmak (ve--rnn-hidden-unitsve--epochsparametrelerini baya artırmak), modeli “papağan” moduna sokmaya yetecek güçtedir; metni ezberlemesi işten bile değildir, ama kimi zaman istediğimiz de bu olabilir. (Örneğin, modelin gerçekten yeterli olup olmadığını görmek adına bir overfitting denemesi gayet yararlıdır.) -
--es-patience: "Early Stopping Patience"ı kısaltmaya çalışıp ancak bu ismi verebildiğimiz bu parametre, her epoch sonunda sınanan validasyon verisi üzerindeki performansın artmayışına arka arkaya en fazla kaç epoch sabretmemiz gerektiğini söyler. Eğer 5 ise mesela,stdoutta görülenval_lossdeğerinin herhangi 5 ardıl epoch süresinde bir gelişme göstermemesinin görülmesi durumunda eğitimin gereğinden daha önce (erken) sonlanmasına sebep olarak aşırı öğrenmeye ket vurur. Eğer buval_lossdenen değer çok süratli değişkenlikler gösteriyorsa (bir inip iki çıkıyorsa mesela), bu parametreyi artırarak çok-erken durdurmanın önüne geçebilirsiniz.
sample.py
-
--length: üretilecek olan metnin karakter sayısı bakımından uzunluğu. Kelime değil karakter sayısı olduğu için 100’ler 1000’ler seviyesinde olabilir. -
--seed: metin üretimini bu karakter dizisiyle başlıyor.Merhabatercih edilebilir (varsayılan). Tek harften ziyade biraz uzun olması modele bağlam kazandırması açısından önemli. Eğer verilenseeddeğerindeki herhangi bir karakter, kullanıcının şu ana kadar yazdığı yanıtlarda yer almamışsa (yani sözlükte yoksa), sözlüğün içerisinden rastgele bir karakter seçiliyor. -
--temperature: yukarıda açıklandığı üzere “exploration vs explotation” dengesini kontrol ediyor.
notlar
-
en baştaki yanıtlar şu komutlarla üretildi:
python train.py dildeolupbiten --epochs 50 --rnn-hidden-units 250 --val-frac 0.1 --seq-length 200 --batch-size 128ve sonrasında istenilen uzunlukta metin üretimi:
python sample.py dildeolupbiten --length LENGTH --seed Merhaba -
chrome'da çalışacak şekilde yazıldı diğer tarayıcılarla da çalışabilecek şekilde ayarlanabilir. -
windows'ta çalışıyor,linux'te de çalışabilir belki. -
tensorflow.js ile bir sitede çalışacak şekle aktarılabilir
-
bir tane daha RNN katmanı ve / veya regulatör (örneğin dropout katmanı) eklenebilir.
-
YazBel’den verinin çekildiği kısım hızlandırılabilir / iyileştirilebilir. (discourse API’ını denedim ama forum yöneticisinin iznini felan istiyor galiba muvaffak olamadım).
-
Malum burası yazılım üzerine bir forum olduğu için kullanıcıların gönderilerinde kodların olması doğal. Dolayısıyla modelin kendini koda kaptırması da bazen kaçınılmaz olabiliyor.
-
program çok da matah bir şey değil evet :d
-
Kod, yorumlar, parametreler ingilizce ve Türkçe karışık…
-
bir defa train edildikten sonra
sample.pyhabire çalıştırılabilinir. -
Eğer halihazırda kayıtlı model ile aynı konfigürasyonda training yapılmaya çalışılıyor ise kullanıcıya soruluyor
-
Python >= 3.7gerekiyor ziradict'lerin kendilerine eklenen elemanların sırasını muhafaza etmesine dayanan bir kısım var. -
[1] The Unreasonable Effectiveness of Recurrent Neural Networks,
[2] Geração de texto com um RNN | Text | TensorFlow
çalıştırmak adına
git clone https://github.com/mustafaaydn/yazbel-net.git
cd yazbel_net
pip install -r requirements.txt
ile yüklendikten sonra
cd yazbel_net
python train.py kullanici_adi [--options]
ile veri elde edilir ve training gerçekleştirilir. Sonrasında ise
python sample.py kullanici_adi [--options]
ile metin üretilir.
verileri forumdan çekmeye çalışırken birkaç kullanıcının verdiği tüm yanıtları da şöyle bir görmüş oldum. buradan sayın @dildeolupbiten’e bu forumdaki varlığı için teşekkür etmek istiyorum.




