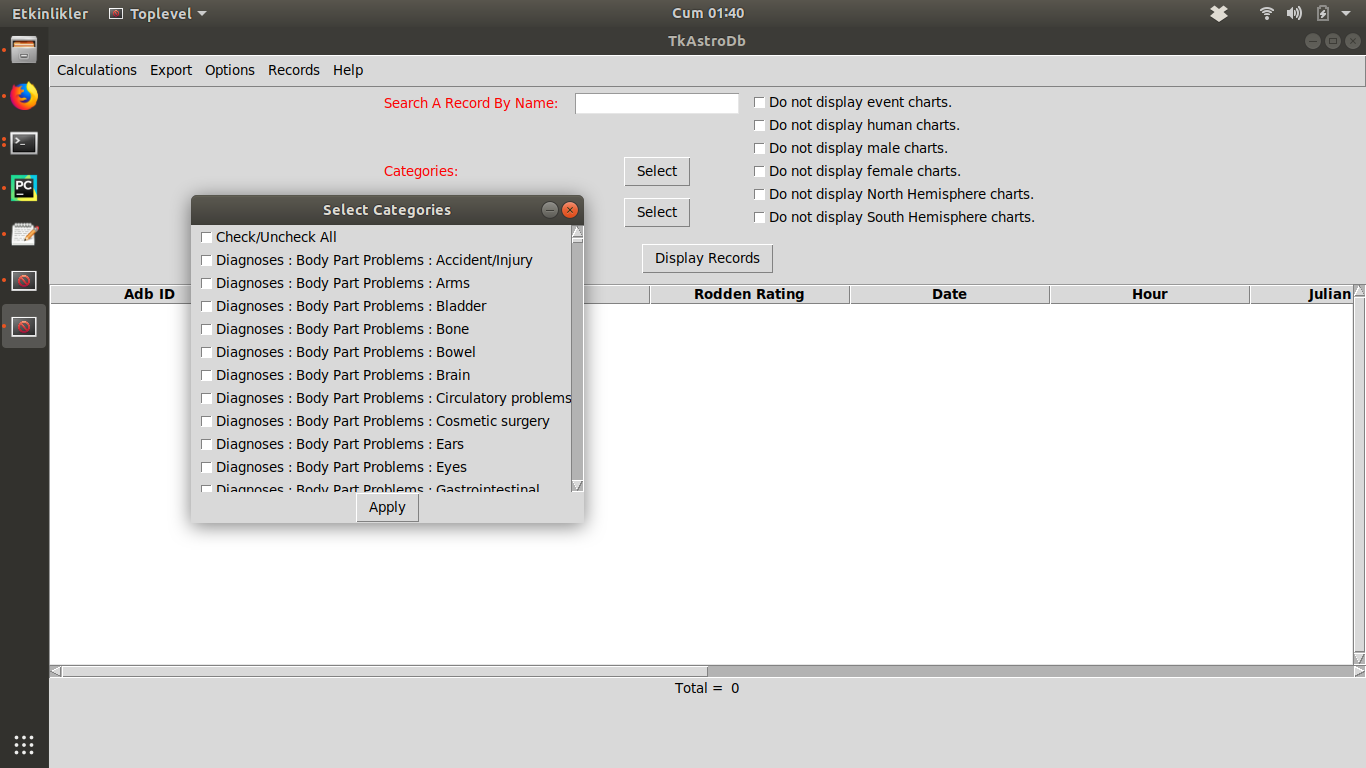
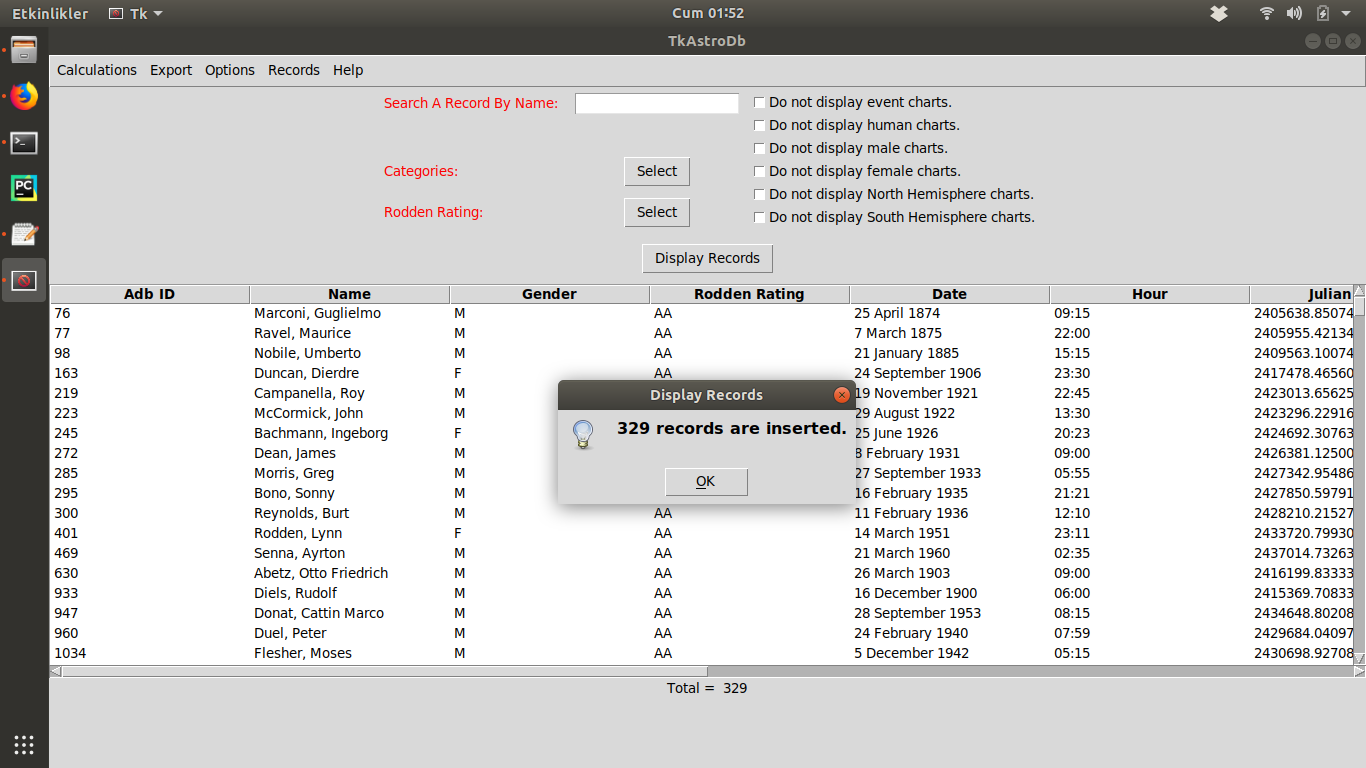
Herkese merhaba,
Programı şu adresten indirebilir ve program hakkında daha ayrıntılı bilgi edinebilirsiniz. Programı çalıştırdığınızda bazı modüller indirilip, kurulabilir.
Not: Windows kullanıcıları cmd’yi yönetici olarak çalıştırmadıkları sürece Pyswisseph modülünün kurulumu sırasında PermissionError hatasıyla karşılaşırlar.
Modüllerin kurulumu tamamlandıktan sonra, programın çok geçmeden açılması lazım.
Ama mevcut algoritmaya göre programın açılma hızı, programın bulunduğu dizinde programla uyumlu lisanslı xml dosyasının olup olmamasına bağlı. Zaman içerisinde sql veritabanındaki kayıt sayısı artmaya başlarsa, programın açılma hızı sql veritabanına da bağlı olur.
Burada program görünür hale gelene kadar faaliyet gösteren kodları paylaşacağım. Çünkü alternatifini aradığım kodlar bu mesajda paylaştığım son fonksiyona ait olan kodlar. Ondan önceki kodlar programın açılış zamanına bahsettiğim fonksiyon kadar etki etmiyorlar. Aslında programın hesaplama işlemlerinin de daha hızlı bir şekilde yapılmasını istiyorum. Ama o kısım şimdilik dursun.
- Modüller yüklendikten sonra ilk olarak bir sql veritabanı oluşturuluyor.
connect = sql.connect("TkAstroDb.db")
cursor = connect.cursor()
col_names = "no, add_date, adb_id, name, gender, rr, date, time, " \
"julian_date, lat, c_lat, lon, c_lon, place, country, " \
"adb_link, category"
cursor.execute(f"CREATE TABLE IF NOT EXISTS DATA({col_names})")
- Sonra, bir kaç satır sonra tanımlanacak olan işlemlerde kullanılacak olan değişkenler tanımlanıyor.
xml_file = ""
database, all_categories, category_names = [], [], []
_count_ = 0
category_dict = dict()
- Program daha sonra çalıştığı dizinde bir xml dosyayı olup olmadığına bakar.
for _i in os.listdir(os.getcwd()):
if _i.endswith("xml"):
xml_file += _i
- Eğer uzantısı xml olan sadece bir tane dosya varsa aşağıdaki
fordöngüsü çalışır.
döngüi=999999durumuna kadar devam edecek şekilde tanımlandı, zaten veritabanında o kadar kayıt yok, bir yerden sonraIndexErrorhatası yükseltilecek. Bu yüzden döngünün içinde yapılacak işlemlertry exceptdeyimi içine yazıldı.
Bufordöngüsünde xml veritabanında bulunan her bir kayıt içinuser_dataisminde bir liste üretilir. Her bir listeye, 13 tane, çeşitli veri tiplerinde eleman eklenecek. Veritabanındaki kayıtlara ulaşmak için bir başka döngü içinderoot'un index değerleri kullanılarak bazı ortak etiketlere bakılır. Sonra bu etiketlerdeki veriler değişik veri tiplerine aktarılır ve bu 13 değişik veri tipiuser_datalistesine eklenir.
if xml_file.count("xml") == 1:
tree = xml.etree.ElementTree.parse(f"{xml_file}")
root = tree.getroot()
for _i in range(1000000):
try:
user_data = []
for gender, roddenrating, bdata, adb_link, categories in zip(
root[_i + 2][1].findall("gender"),
root[_i + 2][1].findall("roddenrating"),
root[_i + 2][1].findall("bdata"),
root[_i + 2][2].findall("adb_link"),
root[_i + 2][3].findall("categories")):
_name = root[_i + 2][1][0].text
sbdate_dmy = bdata[1].text
sbtime = bdata[2].text
jd_ut = bdata[2].get("jd_ut")
lat = bdata[3].get("slati")
lon = bdata[3].get("slong")
place = bdata[3].text
country = bdata[4].text
category = [
(categories[_j].get("cat_id"), categories[_j].text)
for _j in range(len(categories))]
for cate in category:
if cate[0] not in category_dict.keys():
category_dict[cate[0]] = cate[1]
user_data.append(int(root[_i + 2].get("adb_id")))
user_data.append(_name)
user_data.append(gender.text)
user_data.append(roddenrating.text)
user_data.append(sbdate_dmy)
user_data.append(sbtime)
user_data.append(jd_ut)
user_data.append(lat)
user_data.append(lon)
user_data.append(place)
user_data.append(country)
user_data.append(adb_link.text)
user_data.append(category)
database.append(user_data)
except IndexError:
break
xml veritabanındaki her bir kaydın categories isimli bir etiketi var. Bu etiketin içinde birden çok kategori yer alıyor. Bu kategorileri de yukarıdaki kodlardaki şu kısım bir liste ve bir sözlüğe aktarır:
category = [
(categories[_j].get("cat_id"), categories[_j].text)
for _j in range(len(categories))]
for cate in category:
if cate[0] not in category_dict.keys():
category_dict[cate[0]] = cate[1]
category değişkeni döngü içinde sürekli yeniden oluşturulan bir değişkendir bu yüzden category_dict isimli döngü dışında duran bir sözlük tanımlanmıştır, category değişkeni değişmeden önce bütün kategoriler bu sözlüğe aktarılır.
- Sonra, her iki veritabanını birleştiren bir fonksiyon tanımlanır. Bu fonksiyonun yaptığı işlem şimdilik o kadar zaman alan bir işlem değil. (Aşağıdaki kodlarda
_data_listesinin 9. ve 10. elemanları düşürülüyor. Bu elemanlar daha sonra başka işlemlerde lazım olacak. Ama burada o elemanları listeden çıkarmak gerekiyor. Çünkü xml veritabanında bu sütunlar yok.)
def merge_databases():
global _count_
reverse_category_list = {
value: key for key, value in category_dict.items()
}
for _i_ in cursor.execute("SELECT * FROM DATA"):
_data_ = list(_i_)[2:]
_data_.pop(8)
_data_.pop(9)
new_category = []
edit_data = _data_[:12]
if "|" in _data_[12]:
edit_category = _data_[12].split("|")
for _cat_ in edit_category:
if _cat_ in category_dict.values():
new_category.append(
(reverse_category_list[_cat_], _cat_)
)
else:
new_category.append((str(4014 + _count_), _cat_))
category_dict[str(4014 + _count_)] = _cat_
_count_ += 1
reverse_category_list = {
value: key for key, value in category_dict.items()
}
else:
if _data_[12] in category_dict.values():
new_category.append(
(reverse_category_list[_data_[12]], _data_[12])
)
else:
new_category.append((str(4014 + _count_), _data_[12]))
category_dict[str(4014 + _count_)] = _data_[12]
reverse_category_list = {
value: key for key, value in category_dict.items()
}
_count_ += 1
edit_data.append(new_category)
database.append(edit_data)
- Yukarıdaki fonksiyondan sonra alternatif algoritma önerisi aradığım fonksiyon tanımlanır.
def group_categories():
global category_names, all_categories
category_names, all_categories = [], []
for _i_ in category_dict.keys():
_records_ = []
category_groups = {}
category_name = ""
for j_ in database:
for _k in j_[12]:
if _k[0] == f"{_i_}":
_records_.append(j_)
category_name = _k[1]
if category_name is None:
category_name = "No Category Name"
category_groups[(_i_, category_name)] = _records_
if not _records_:
pass
else:
if category_name not in category_names:
category_names.append(category_name)
all_categories.append(category_groups)
category_names = sorted(category_names)
Bu fonksiyonda şuanlık sayısı 793 olan kategorilerin her biri için aşağıdaki değişkenler tekrar tekrar tanımlanır:
_records_ = []
category_groups = {}
category_name = ""
Sonra her bir kategori için, 64338 adet elemanı olan database isimli bir liste tekrar tekrar taranır. Ayrıca her kaydın 13. sütunu, bir kategori listesi olduğu için, aranan kategori bu kategori listesi içinde mi ona bakılır. Şayet içindeyse, _records_ değişkenine kayıt eklenir. category_name değişkenine, döngü içinde sırası gelen kategorinin ismi aktarılır. Eğer kategori ismi None ise ismi No Category Name olarak değiştirilir. Sonra category_groups sözlüğünün anahtarı _i_ ve category_name olarak, değeri de bu kategoriye sahip kayıtların tutulduğu _records_ olarak belirlenir. Buradaki _i_ değişkeni int veri tipinde bir sayıdır. Eğer bu kategoride bir kayıt yoksa hiç bir işlem yapılmaz, varsa category_groups sözlüğü, döngü dışında tutulan all_categories listesine eklenir. Ayrıca daha sonra kategorileri alfabetik sıraya göre sıralamak için category_names listesine kategori ismi eklenir. Ve döngü diğer bir kategori için tekrar başa döner, en sonunda da category_names listesi alfabetik olarak sıralanır. Kategoriler kullanıcılara bu sayede alfabetk olarak sıralı bir şekilde gösterilir.
Biraz karışık anlattıysam özür dilerim.İşte bu yukarıda bahsettiğim işlemler bilgisayarımda aşağı yukarı 25 saniye sürüyor. Bu süre başka bir algoritma kullanılarak azaltılabilir mi? Önerisi olan arkadaşlara şimdiden teşekkür ederim.