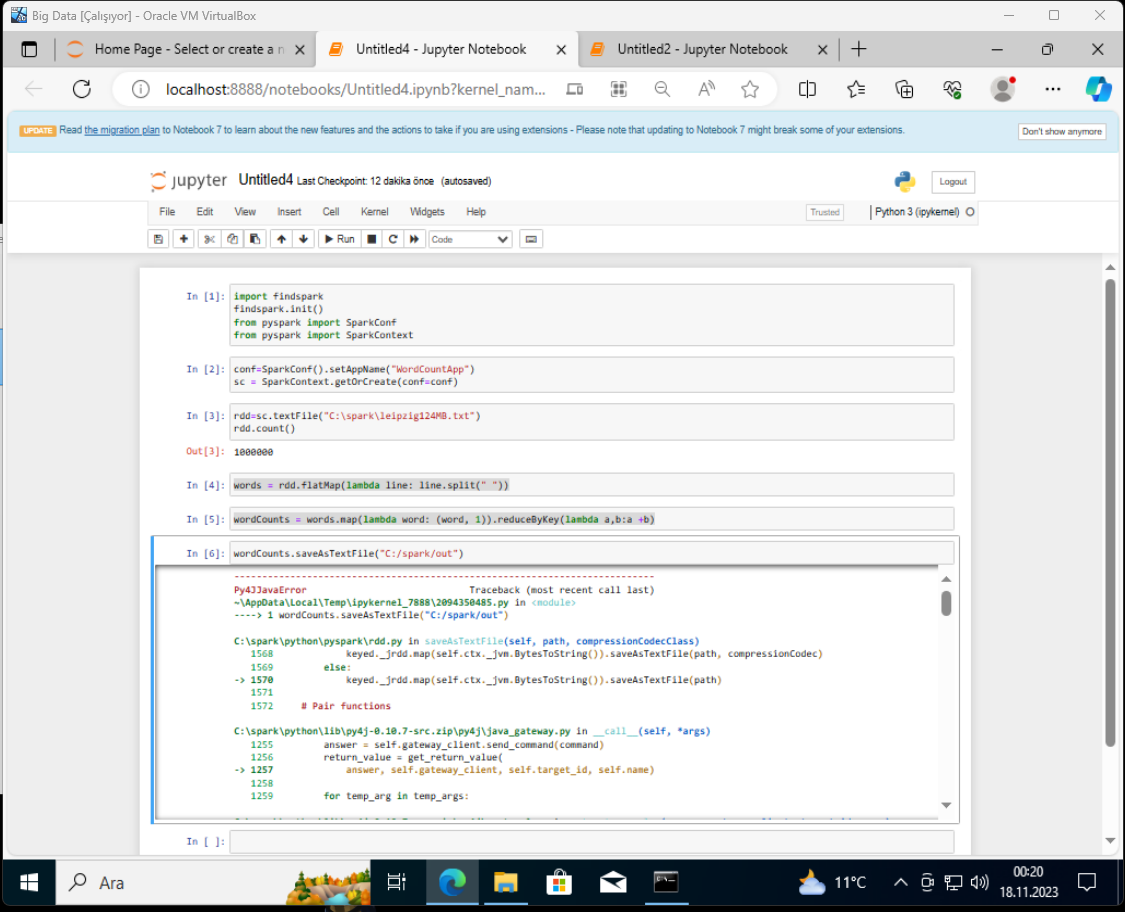
merhabalar proje ödevim için apache spark kullanarak bi dosyayı analiz etmem gerekiyor ve dosyayı kaydederken hata alıyorum yardımcı olur musunuz?
aldığım hata son aşamada dosya yazarken
import findspark
findspark.init()
from pyspark import SparkConf
from pyspark import SparkContext
conf=SparkConf().setAppName("WordCountApp")
sc = SparkContext.getOrCreate(conf=conf)
rdd=sc.textFile("C:\spark\leipzig124MB.txt")
rdd.count()
words = rdd.flatMap(lambda line: line.split(" "))
wordCounts = words.map(lambda word: (word, 1)).reduceByKey(lambda a,b:a +b)
wordCounts.saveAsTextFile("C:/spark/out")
Py4JJavaError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_7888\2094350485.py in <module>
----> 1 wordCounts.saveAsTextFile("C:/spark/out")
C:\spark\python\pyspark\rdd.py in saveAsTextFile(self, path, compressionCodecClass)
1568 keyed._jrdd.map(self.ctx._jvm.BytesToString()).saveAsTextFile(path, compressionCodec)
1569 else:
-> 1570 keyed._jrdd.map(self.ctx._jvm.BytesToString()).saveAsTextFile(path)
1571
1572 # Pair functions
C:\spark\python\lib\py4j-0.10.7-src.zip\py4j\java_gateway.py in __call__(self, *args)
1255 answer = self.gateway_client.send_command(command)
1256 return_value = get_return_value(
-> 1257 answer, self.gateway_client, self.target_id, self.name)
1258
1259 for temp_arg in temp_args:
C:\spark\python\lib\py4j-0.10.7-src.zip\py4j\protocol.py in get_return_value(answer, gateway_client, target_id, name)
326 raise Py4JJavaError(
327 "An error occurred while calling {0}{1}{2}.\n".
--> 328 format(target_id, ".", name), value)
329 else:
330 raise Py4JError(
Py4JJavaError: An error occurred while calling o55.saveAsTextFile.
: org.apache.spark.SparkException: Job aborted.
at org.apache.spark.internal.io.SparkHadoopWriter$.write(SparkHadoopWriter.scala:100)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1.apply$mcV$sp(PairRDDFunctions.scala:1096)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1.apply(PairRDDFunctions.scala:1094)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1.apply(PairRDDFunctions.scala:1094)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:363)
at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopDataset(PairRDDFunctions.scala:1094)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$4.apply$mcV$sp(PairRDDFunctions.scala:1067)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$4.apply(PairRDDFunctions.scala:1032)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$4.apply(PairRDDFunctions.scala:1032)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:363)
at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopFile(PairRDDFunctions.scala:1032)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$1.apply$mcV$sp(PairRDDFunctions.scala:958)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$1.apply(PairRDDFunctions.scala:958)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$1.apply(PairRDDFunctions.scala:958)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:363)
at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopFile(PairRDDFunctions.scala:957)
at org.apache.spark.rdd.RDD$$anonfun$saveAsTextFile$1.apply$mcV$sp(RDD.scala:1499)
at org.apache.spark.rdd.RDD$$anonfun$saveAsTextFile$1.apply(RDD.scala:1478)
at org.apache.spark.rdd.RDD$$anonfun$saveAsTextFile$1.apply(RDD.scala:1478)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:363)
at org.apache.spark.rdd.RDD.saveAsTextFile(RDD.scala:1478)
at org.apache.spark.api.java.JavaRDDLike$class.saveAsTextFile(JavaRDDLike.scala:550)
at org.apache.spark.api.java.AbstractJavaRDDLike.saveAsTextFile(JavaRDDLike.scala:45)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task 1 in stage 2.0 failed 1 times, most recent failure: Lost task 1.0 in stage 2.0 (TID 9, localhost, executor driver): ExitCodeException exitCode=-1073741515:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:582)
at org.apache.hadoop.util.Shell.run(Shell.java:479)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:773)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:866)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:849)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:733)
at org.apache.hadoop.fs.RawLocalFileSystem$LocalFSFileOutputStream.<init>(RawLocalFileSystem.java:225)
at org.apache.hadoop.fs.RawLocalFileSystem$LocalFSFileOutputStream.<init>(RawLocalFileSystem.java:209)
at org.apache.hadoop.fs.RawLocalFileSystem.createOutputStreamWithMode(RawLocalFileSystem.java:307)
at org.apache.hadoop.fs.RawLocalFileSystem.create(RawLocalFileSystem.java:296)
at org.apache.hadoop.fs.RawLocalFileSystem.create(RawLocalFileSystem.java:328)
at org.apache.hadoop.fs.ChecksumFileSystem$ChecksumFSOutputSummer.<init>(ChecksumFileSystem.java:398)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:461)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:440)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:911)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:804)
at org.apache.hadoop.mapred.TextOutputFormat.getRecordWriter(TextOutputFormat.java:123)
at org.apache.spark.internal.io.HadoopMapRedWriteConfigUtil.initWriter(SparkHadoopWriter.scala:228)
at org.apache.spark.internal.io.SparkHadoopWriter$.org$apache$spark$internal$io$SparkHadoopWriter$$executeTask(SparkHadoopWriter.scala:122)
at org.apache.spark.internal.io.SparkHadoopWriter$$anonfun$3.apply(SparkHadoopWriter.scala:83)
at org.apache.spark.internal.io.SparkHadoopWriter$$anonfun$3.apply(SparkHadoopWriter.scala:78)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:121)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1889)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1877)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1876)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1876)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:926)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:926)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:926)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2110)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2059)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2048)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:737)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2061)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2082)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2114)
at org.apache.spark.internal.io.SparkHadoopWriter$.write(SparkHadoopWriter.scala:78)
... 41 more
Caused by: ExitCodeException exitCode=-1073741515:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:582)
at org.apache.hadoop.util.Shell.run(Shell.java:479)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:773)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:866)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:849)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:733)
at org.apache.hadoop.fs.RawLocalFileSystem$LocalFSFileOutputStream.<init>(RawLocalFileSystem.java:225)
at org.apache.hadoop.fs.RawLocalFileSystem$LocalFSFileOutputStream.<init>(RawLocalFileSystem.java:209)
at org.apache.hadoop.fs.RawLocalFileSystem.createOutputStreamWithMode(RawLocalFileSystem.java:307)
at org.apache.hadoop.fs.RawLocalFileSystem.create(RawLocalFileSystem.java:296)
at org.apache.hadoop.fs.RawLocalFileSystem.create(RawLocalFileSystem.java:328)
at org.apache.hadoop.fs.ChecksumFileSystem$ChecksumFSOutputSummer.<init>(ChecksumFileSystem.java:398)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:461)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:440)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:911)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:804)
at org.apache.hadoop.mapred.TextOutputFormat.getRecordWriter(TextOutputFormat.java:123)
at org.apache.spark.internal.io.HadoopMapRedWriteConfigUtil.initWriter(SparkHadoopWriter.scala:228)
at org.apache.spark.internal.io.SparkHadoopWriter$.org$apache$spark$internal$io$SparkHadoopWriter$$executeTask(SparkHadoopWriter.scala:122)
at org.apache.spark.internal.io.SparkHadoopWriter$$anonfun$3.apply(SparkHadoopWriter.scala:83)
at org.apache.spark.internal.io.SparkHadoopWriter$$anonfun$3.apply(SparkHadoopWriter.scala:78)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:121)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
... 1 more