Google Drive API kullarak dosya yedekleme işlemi yapıyorum.
Aynı dosyaları birden fazla kez yedeklemek istemiyorum;
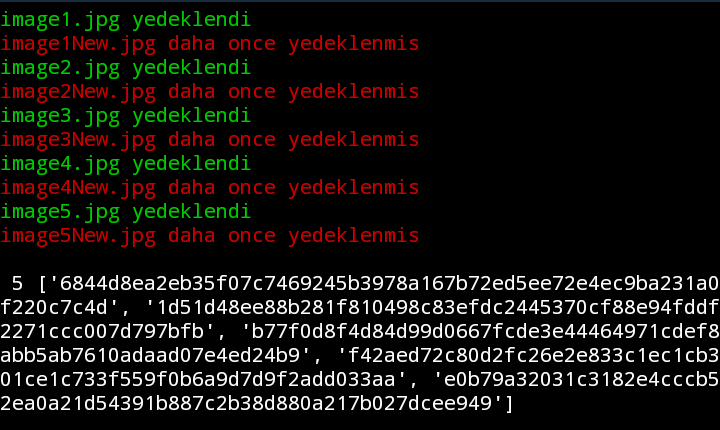
•Bunun için kontrol sağlamam gerekiyor ama dosya isimleri üzerinden kontrol edemem çünkü aynı dosya farklı isimlerle var olabiliyor; image.png veya imagenew.png veya image_1.png gibi…
•Yedeklemeden önce yedeklenecek dosyaları kendi aralarında kontrol edip aynı olmayanları yedekleyebilirim ancak aradan bir süre geçince hangi dosyaları yedeklediğimi unutucağımı düşünüyorum ve bu yüzden bunun verimli olacağını düşünmüyorum.
•Aklıma gelen çözüm ise yedeklenmiş dosyaları çekmek ve yedeklenecek dosya ile karşılaştırmak oldu.
from googleapiclient.discovery import build
from google.oauth2.credentials import Credentials
SCOPES = ['https://www.googleapis.com/auth/drive']
creds = Credentials.from_authorized_user_file('token.json', SCOPES)
service = build('drive', 'v3', credentials=creds)
yedeklenecekDosya = open('img.png', 'rb').read()
yedeklenmisDosyalar=[]
results = service.files().list(q=f"'{'1Lo5VUyLGj0xo_EIGvYO1XFcCTQ8TdzYr'}' in parents and trashed = false", fields="nextPageToken, files(id, name)").execute()
items = results.get('files', [])
for i in items:
yedeklenmisDosyalar.append(service.files().get_media(fileId=i['id']).execute())
if yedeklenecekDosya in yedeklenmisDosyalar:
print("zaten önceden yedeklenmis!")
else:
print("yedeklenebilir")
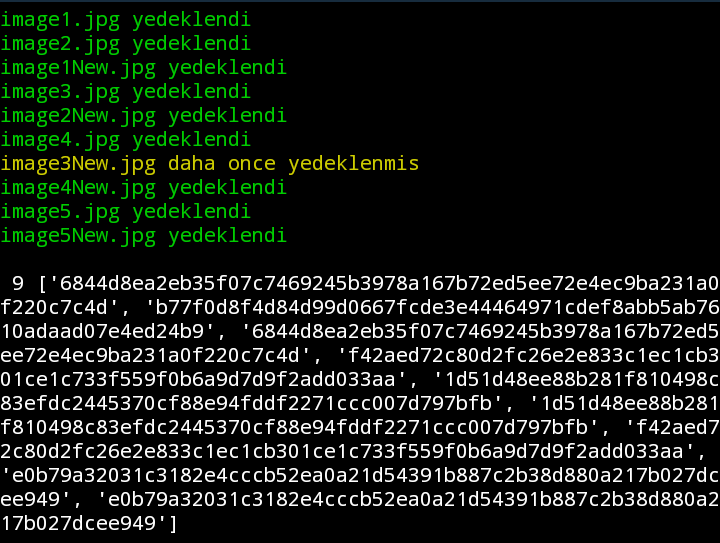
Bunun bi tık verimli hâli şu şekilde;
from googleapiclient.discovery import build
from google.oauth2.credentials import Credentials
import hashlib
SCOPES = ['https://www.googleapis.com/auth/drive']
creds = Credentials.from_authorized_user_file('token.json', SCOPES)
service = build('drive', 'v3', credentials=creds)
# Yedeklenecek dosyanın özeti (hash) hesaplanır
yedeklenecekDosya = open('img.png', 'rb').read()
yedeklenecekDosyaHash = hashlib.md5(yedeklenecekDosya).hexdigest()
# Yedeklenmiş dosyaların listesi alınır ve özetleri hesaplanır
yedeklenmisDosyalar = set()
results = service.files().list(q=f"'{'1Lo5VUyLGj0xo_EIGvYO1XFcCTQ8TdzYr'}' in parents and trashed = false", fields="nextPageToken, files(id, name)").execute()
items = results.get('files', [])
for i in items:
yedeklenmisDosyalar.add(service.files().get(fileId=i['id'], fields='md5Checksum').execute()['md5Checksum'])
# Yedeklenecek dosya, önceden yedeklenmiş dosyaların listesinde var mı diye kontrol edilir
if yedeklenecekDosyaHash in yedeklenmisDosyalar:
print("Zaten önceden yedeklenmiş!")
else:
print("Yedeklenebilir")
Daha verimli bir şekilde nasıl yapabilirim, mantığını anlamam yeterli olur. Daha verimli yol yoksa 2 örneği kullanmaya devam edeceğim sanırım.