arkadaşlar merhaba. ben amatörce ama merakla bu işlerle uğraşan biriyim. python u yeni keşfettim. işlemleri hızlandırma bakımından çok iyi ve yararlı olduğunu düşünüyorum. içinden çıkamadığım bir konu var lütfen bana yardımcı olur musunuz ?
Elimde 50 bin küsür wav formatlı kısa ses dosyaları var. bu dosyalardan hemen hemen yarısı türkçe yarısı ingilizce. yani ses yapısı birbirinin aynı olan ama farklı dilde olan binlerce ses var. bu seslerin sadece waveform durumlarını karşılaştırıp, eşleştirip sonra klasörlere taşıyan bir kod gerekiyor.
bu konuda bana yardımcı olursanız çok sevinirim.
import os
import shutil
src_files = os.listdir(src)
for file_name in src_files:
full_file_name = os.path.join(src, file_name)
if os.path.isfile(full_file_name):
shutil.copy(full_file_name, dest)
şöyle bir kod var. Ben denemedim.
kaynak : Copy multiple files in Python - Stack Overflow
1 Beğeni
Siz ne denediniz bizimle paylaşır mısınız?
1 Beğeni
Oncelikle bir planlama yapmaniz lazim. Dil tanima kadar yuksek seviye ve zor bir problemden bahsedip, yaninda WAV dosyasinin teknik detaylari ve dosya tasiyan bir python script’inden bahsediyorsunuz. Bu, problemi arastirmadiginizi gosteriyor.
Verilen seslerin benzerliklerini bulan bir kutuphane veya hizmet var mi? Nasil kullaniliyor, kac para? Yoksa yazacak misiniz? Bu konuda literatur ne diyor? Ses yerine yazi uzerinden gitmek daha kolay mi olur? Bunun nasil hizmetleri var…
Waveform durumlarini karsilastirmaktan ne kastediyorsunuz? Hic boyle bir karsilastirma yaptiniz mi? Uc adet ornek dosyada nasil sonuclar elde edildi?
Bunlari yaptiktan sonra python scripti yazma, dosyalari tasima kolay.
3 Beğeni
ben seslerin “sample” miktarına göre eşleştirip klasörlere taşıması için bir kod yazdım çalıştı fakat %60-70 olumlu sonuç alabildim. örneğim bazı klasörlerde; sample miktarı aynı ama alakasız 3-4 dosya atmış bazılarına ise sadece 1 dosya atmış. verimliliği yükseltmek ve daha mükemmele yaklaşmak istiyorum.
aynı sample miktarını bulması için çalıştırdığım kod:;
import os
import shutil
from collections import defaultdict
import librosa
ses_klasoru = "C:\seslerim"
hedef_klasor = "C:\seslerim\grupla"
dosya_gruplari = defaultdict(list)
for dosya in os.listdir(ses_klasoru):
dosya_yolu = os.path.join(ses_klasoru, dosya)
try:
# Dosya uzantısını kontrol edin
if not dosya.endswith(".wav"):
continue
# Ses dosyasını yükle ve sample miktarını al
ses, _ = librosa.load(dosya_yolu, sr=None)
sample_miktari = len(ses)
# Dosyayı sample miktarına göre gruplayın
dosya_gruplari[sample_miktari].append(dosya)
except Exception as e:
print(f"Hata: {e}")
continue
# Grupları sample miktarına göre sıralayın
sirali_gruplar = sorted(dosya_gruplari.items(), key=lambda x: x[0])
# Dosyaları taşıyın
for miktar, dosyalar in sirali_gruplar:
hedef_dizin = os.path.join(hedef_klasor, str(miktar))
# Hedef dizin yoksa oluşturun
if not os.path.exists(hedef_dizin):
os.makedirs(hedef_dizin)
# Dosyaları hedef dizine taşıyın
for dosya in dosyalar:
dosya_yolu = os.path.join(ses_klasoru, dosya)
hedef_yol = os.path.join(hedef_dizin, dosya)
shutil.move(dosya_yolu, hedef_yol)
basitçe örnek vermem gerekirse mesela sesin ilk 1 saniyesi boş diyelim. sonra konuşma var, sonraki 0.5 saniye de boş…sonra gene konuşma.vs.vs… bu şekilde diğer dildeki dosyanın da aynı yapıda olması gerekir. kod’un yapmasını istediğim bu benzer ikilileri bulup, seçip klasörlere gruplaması. sample miktarlarına göre denedim ama çok iyi olmadı
Merhaba.
Python mı? Dj mi?
Tüm programların amacı budur hemen hemen.
Yardımcı olmayı deneriz. Ama bunun için tam olarak ne istediğinizi iyi anlamamız gerekir. Bundan sonraki kısımlar sizi daha iyi anlamamız içindir.
Elimizdeki ipucu DJ 50 bin wav dosyası muhtemelen kısa kısa sample’lar.
Sample’larımızın yarısı ingilizce diğer yarısı da Türkçe ses içeren müzikleriaynı ses dosyaları anladığım kadarıyla.
Ses yapısı ne demek anlamadım ama sanırım, müzik kısımları, ritimler enstrumanlar vs aynı ama insan sesi olan kısımlar farklı sanırım.
waveform durumlarını neye göre karşılaştıracak ve eşleştirecek? Sonuçta biri ingilizce vocal diğeri Türkçe vokal içeriyorsa wave formları farklı olacaktır.
Bana sanki ChatGPT ye sormuşsunuz o da size bir kod önermiş gibi geliyor.
İyi olması için, öncelikle eşleştirmek ne demek onda anlaşmamız gerekir.
İki farklı ses dosyası içinde vokal sesleri varsa zaten aynı olamaz.
Ses aralarındaki boşluk frekansları da aynı çıkabilir de çıkmayabilirde.
Burada bir bilgisayarın yapamabileceğinin tam tersini istiyorsunuz. Bir bilgisayar bir konuda eşittir yada eşit değildir diye karar verir.
Elinizdeki ham ses dosyası datasının hiç bir şekilde bir diğer ses dosyası ile eşit olma durumu olmayacaktır.
Bana kızmayın,bilgisayarları ben tasarlamadım adamlar sadece 1 ve 0 lardan anlıyor.
Arasında bir karar aldırmak istiyorsanız, farklı yaklaşımlara ve belli toleranslara ihtiyacınız olacaktır.
Biz buna yapa zeka diyoruz.
Öyle chatgpt ye yazıp hadi bakalım yaz bu kod diyerek çözümlenecek sorunlar değil bunlar. Hele ki asıl işi bu olmayan birinin, bana şöyle bir araç lazım diye sipariş edip çözebileceği durumlardan hiç değil.
Şöyleki en basit çözüm yöntemi üzerinden gidelim…
Tensorflow veya benzeri bir kütüphane kullanacaksınız, müzik işinden anlıyorsanız, ses dosyalarınıza, vocal fader uygulayacaksınız. Sonra bu ses dosyalarını, dalga formları, süre ve dalga tepe noktaları gibi bir çok filtreden geçirerek benzer olduklarını doğrulamaya çalışacaksınız.
Yani aynı olamayacaklarına göre, ancak benzer oldukları üzerinden kararlar vermesi gerekecek kodun. Bu “benzer” de bilgisayar dünyasının sevmediği işlerden olduğundan, benzer kavramını tolerans değerleri ile belirginleştireceksiniz.
Sonrasında ise o tolerans değerleriniz içerisinde ise eşleşti kabul edip ilgili klasörünüze taşıtabilirsiniz.
Tabi tolerans değerlerini doğru belirlemeniz gerekir bu da ses dosylarında ufak hatalara neden olabilecektir.
Yani işlemleri basamaklayalım.
Ses dosyanızı bir yapay zeka algoritması ile insan sesinden arındırılmış bir dosyaya dönüştürüp, sonra bunu diğer dosyanıza da aynı işlemi uyguladıktan sonra karşılaştırıp, benzerlikleri sizi tatmin eden değere ulaştığında kopyalama yapabilirsiniz.
Bu durumda dahi ufak sapmalar olacaktır ama çoğu dosyada işe yarayacaktır.
Eğer ses örnekleriniz aynı uzunlukta ise bunu da bir veri olarka kullanıp, eşleştirmenizi sağlamlaştırmaya çalışabilirsiniz. Yada eşit uzunlukta değil ama bazı dalga formları belirli sürelerde belirli pattern/desen ler oluşturuyorsa bunu da bir indikatör olarak kullanabilirsiniz.
Elimizde üzerinde çalışmak için, benzer diye nitelediğiniz dosyalardan bir kaç çift örnek olursa kod üzerinde göstermek de mümkün olabilirdi.
Ama henüz tam netleşmemiş kısımlar olduğundan bu aşamada kod vermek zor.
Ve eşleştirme kavramınızı çok iyi kavramamızı sağlamanız gerekmekte.
Kolay gelsin.
Arkadaşım bu kadar destansı ve sorgulamalarla dolu bir cevap yazmana gerek yoktu. evet chat gpt den yardım aldım çünkü uzmanlık alanım coderlik değil. Bu konuda uzman olmadığımı yazdım zaten olsaydım emin ol bu konuyu açmazdım. Ayrıca bu tür konuları açan acemilere de kendimce tepeden bakıp sorgulamazdım. çok basit bir şey sordum ve bununla ilgili yardım istedim. üzgünüm senin kadar “teknik tabir” bilmiyorum kendimce daha basit bir şekilde göstereyim
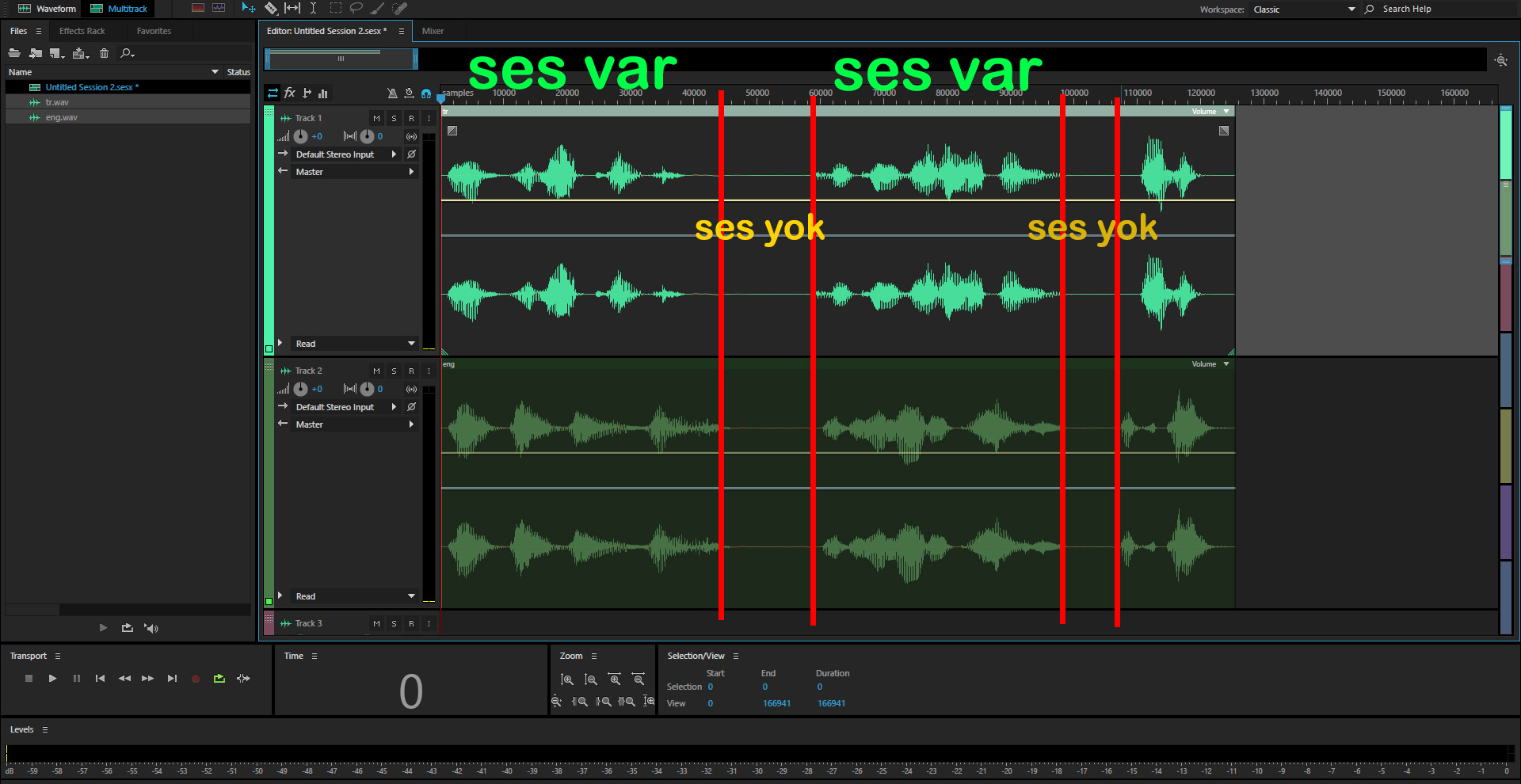
seslerin müzikle alakası yok hepsi bir oyuna ait birbirinin aynı türkçe ve ingilizce sesler. bunların eşleştirmesini yapmak istiyorum.
Yok destansı değil, ne sorduğunu anlamaya çalışıp, nasıl çözümleyeceğini gösterdim.
Derin Öğrenmeye dayalı ses kaynağı ayırma (ses giderici) sistemi (www-sefidian-com.translate.goog)
Şuradan oku belki biraz bir şeyler anlarsın.
Coderlar cevap versin o zaman.
Ses var/yok islemi icin basit bir thresholding yapilabilir (genlik < X). Daha sonra mesela sessizliklerin birbirleriyle toplam kac saniye ortustuklerine bakilabilir.
Mevcut kod sesleri uzunluklarina gore mi ayiriyor?
1 Beğeni
benim kullandığım kodda sesteki sample miktarına göre eşleştirip klasörlere taşıyordu. şu şekilde:
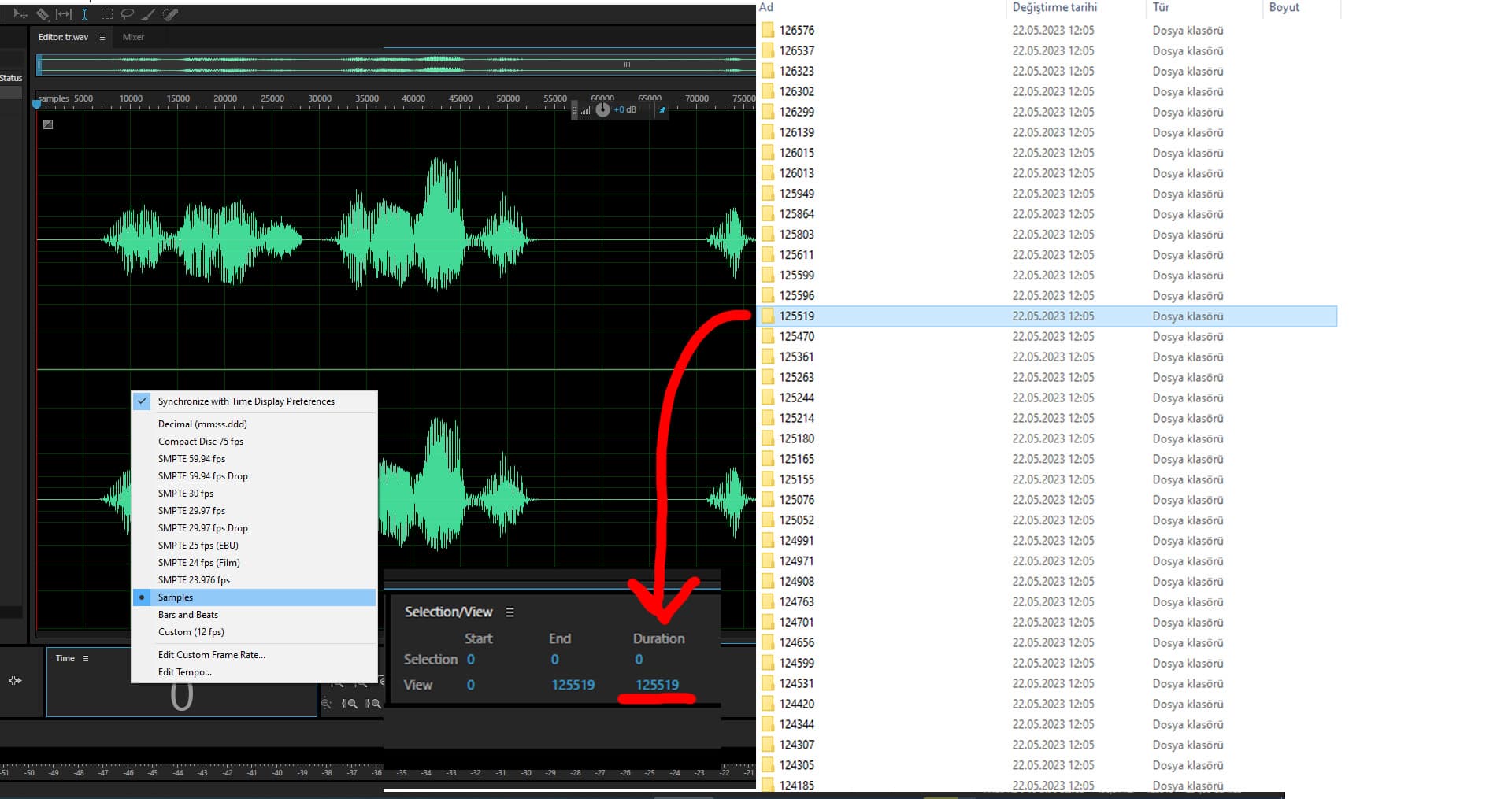
bu şekilde bulduğu tüm değerlere göre klasörler açıp aynı değerde olan sesleri eşleyip oraya attı..
fakat sorun şu aynı değere sahip başka sesleri de klasöre atmış mesela bazı klasörlerde 6-8 dosya var.. aslında bu da insanı biraz yorar ama iş görür. tek tek kontrol etmekten daha iyi.. sonuçta 50k küsür dosya var. benim konuyu açmamdaki amaç hem %100 e yakın bir başarı sağlamak hem de bu şekilde kod arayan arkadaşlara türkçe bir sitede kaynak sunmaktı. olursa olur olmazsa can sağlığı. teşekkür ediyorum yanıtın ve ilgilendiğin için
sample sayisi = sesin uzunlugu (× sample rate)
Yani sesin icerigine bagli hic bir islem yapilmiyor. Dosya boyutuna gore de gruplayabilirsin, kutuphane gerektirmez ve baska dosya turleri icin de calisir.
2 Beğeni