Bir Interpreter Yazalım - Part 1
“Eğer derleyicilerin nasıl çalıştığını bilmiyorsanız, bilgisayarların nasıl çalıştığını da bilmiyorsunuz demektir. Eğer derleyicilerin tam olarak nasıl çalıştığından emin değilseniz, o halde nasıl çalıştıklarını bilmiyorsunuzdur.”— Steve Yegge
Bunun hakkında biraz düşünün. Ne kadar acemi ya da tecrübeli olduğunuzun bir önemi yok: Eğer bir derleyicinin nasıl çalıştığını bilmiyorsanız, bilgisayarların da nasıl çalıştığını bilmiyorsunuz demektir. Bu kadar basit.
Bu yazı serisinde, birlikte bir interpreter yazacağız. Yazı serisinin sonunda, derleyicilerin ve yorumlayıcıların nasıl çalıştığını biliyor olacaksınız! ![]()
Başlamadan önce, neden bir yorumlayıcı yazmak isteyebileceğinizden bahsedelim.
- Bir derleyici ya da yorumlayıcı yazabilmek için, bir çok teknik yeteneğe ihtiyacınız vardır. Bir yorumlayıcı yazmak, bu teknik yeteneklerinizi geliştirmenizi sağlar. Tabii, geliştirdiğiniz bu teknik yetenekler ile çok daha iyi yazılımlar yapabiliyor olacaksınız, sadece yorumlayıcı değil.
- Bir bilgisayarın nasıl çalıştığını öğrenmek isteyebilirsiniz. Bazen derleyiciler ve yorumlayıcılar size sihir gibi gelir. Bu işlemin bir belirsizlik (sihir) teşkil ediyor oluşu sizi rahatsız edebilir ve bu sihiri çözmek isteyebilirsiniz!
- Kendinize ait bir programala dili ya da domain specific dilinizi (özel bir konu için geliştirilmiş dil, bkz: SQL, yacc, lex) oluşturmak istiyorsunuz. Bir tane oluşturdunuz diyelim, bunun için bir derleyici ya da yorumlayıcı da oluşturmanız gerekecektir.
Tamam iyi de, derleyici ve yorumlayıcı dediğimiz şeyler nedir?
Bir yorumlayıcının ya da derleyicini amacı, yüksek seviyeli (insanlar tarafından anlaması kolay) kodu farklı bir forma getirmektir. Çok belirsiz bir tanım, değil mi? Ama emin olun, bu yazı serisinin sonunda neyin ne olduğunu anlayacaksınız.
Bu noktada, bir yorumlayıcı ve derleyici arasındaki farkın ne olduğunu merak edebilirsiniz. Bir çevirici bir kaynak kodu makine koduna çeviriyorsa, onu bir derleyici olarak kabul edelim. Eğer bir çevirici, kaynak kodu direkt makine koduna çevirmeden işleyip çalıştırıyorsa, o bir yorumlayıcıdır. Görsel olarak şöyle ifade edebiliriz:
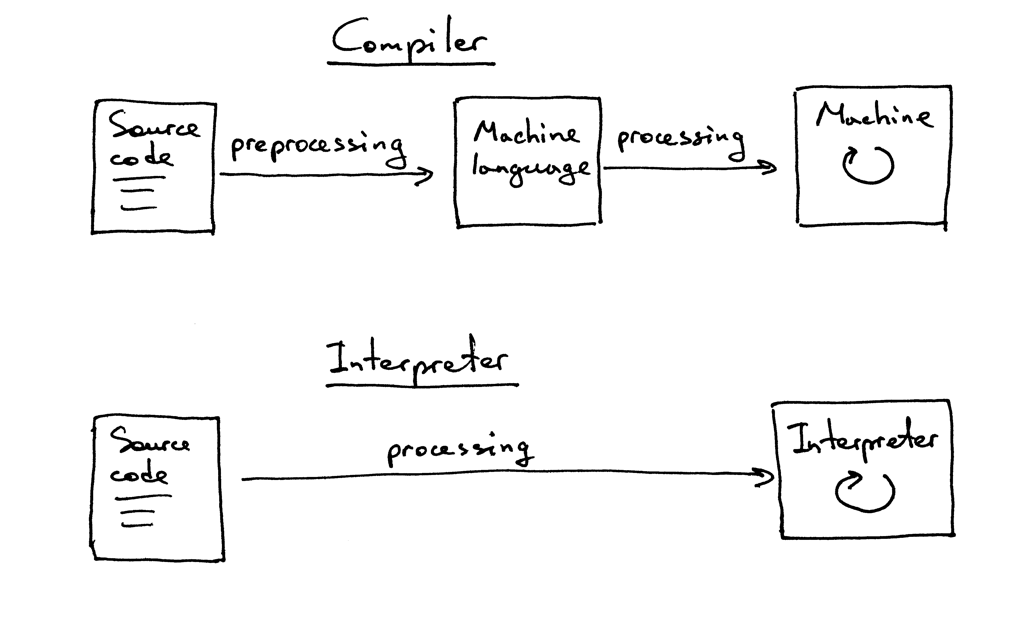
Umarım artık bir derleyici ya da yorumlayıcı yapmaya ikna olmuşsunuzdur.
İşte anlaşma, birlikte bu yazı dizinde Pascal dilinin büyük bir kısmı için bir yorumlayıcı yazacağız. Sona geldiğimizde, elinizde çalışan bir Pascal yorumlayıcısı ve Python’un pdb’si gibi source-level bir hata ayıklayıcı olacak.
Neden Pascal dilini tercih ettiğimi sorabilirsiniz. Bir şey için, Pascal sadece bu seri için oluşturulmuş bir basit bir dil değil, Pascal bir önemli yapılara sahip gerçek bir dil. Eski ama bazı CS kitaplarındaki örnekler de Pascal ile yazılmış durumdalar. (Pek geçerli bir sebep değil :P)
Aşağıda, yazacağımız yorumlayıcı ile yorumlanabilecek ve kaynak düzeyinde çalışan hata ayıklayıcı ile hata ayıklama yapabileceğimiz bir Pascal programı yer alıyor.
program factorial;
function factorial(n: integer): longint;
begin
if n = 0 then
factorial := 1
else
factorial := n * factorial(n - 1);
end;
var
n: integer;
begin
for n := 0 to 16 do
writeln(n, '! = ', factorial(n));
end.
Biz yorumlayıcıyı Python ile yazacağız fakat konsept dil bağımsız olduğu için farklı programlama dilleri kullanabilirsiniz. Hadi başlayalım!
İlk olarak aritmetik işlemleri yorumlayabilen bir yorumlayıcı yazarak başlayacağız. (Hesap makinesi yapıyoruz) Amacımız son derece basit: iki adet rakamı toplayabilmek yani 3+5 gibi bir işlemi yaptırabilmek. İşte, hesap makinesi, özür dilerim, yorumlayıcınızın kodları:
# Token types
#
# EOF (end-of-file) token is used to indicate that
# there is no more input left for lexical analysis
INTEGER, PLUS, EOF = 'INTEGER', 'PLUS', 'EOF'
class Token(object):
def __init__(self, type, value):
# token type: INTEGER, PLUS, or EOF
self.type = type
# token value: 0, 1, 2. 3, 4, 5, 6, 7, 8, 9, '+', or None
self.value = value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(PLUS '+')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=repr(self.value)
)
def __repr__(self):
return self.__str__()
class Interpreter(object):
def __init__(self, text):
# client string input, e.g. "3+5"
self.text = text
# self.pos is an index into self.text
self.pos = 0
# current token instance
self.current_token = None
def error(self):
raise Exception('Error parsing input')
def get_next_token(self):
"""Lexical analyzer (also known as scanner or tokenizer)
This method is responsible for breaking a sentence
apart into tokens. One token at a time.
"""
text = self.text
# is self.pos index past the end of the self.text ?
# if so, then return EOF token because there is no more
# input left to convert into tokens
if self.pos > len(text) - 1:
return Token(EOF, None)
# get a character at the position self.pos and decide
# what token to create based on the single character
current_char = text[self.pos]
# if the character is a digit then convert it to
# integer, create an INTEGER token, increment self.pos
# index to point to the next character after the digit,
# and return the INTEGER token
if current_char.isdigit():
token = Token(INTEGER, int(current_char))
self.pos += 1
return token
if current_char == '+':
token = Token(PLUS, current_char)
self.pos += 1
return token
self.error()
def eat(self, token_type):
# compare the current token type with the passed token
# type and if they match then "eat" the current token
# and assign the next token to the self.current_token,
# otherwise raise an exception.
if self.current_token.type == token_type:
self.current_token = self.get_next_token()
else:
self.error()
def expr(self):
"""expr -> INTEGER PLUS INTEGER"""
# set current token to the first token taken from the input
self.current_token = self.get_next_token()
# we expect the current token to be a single-digit integer
left = self.current_token
self.eat(INTEGER)
# we expect the current token to be a '+' token
op = self.current_token
self.eat(PLUS)
# we expect the current token to be a single-digit integer
right = self.current_token
self.eat(INTEGER)
# after the above call the self.current_token is set to
# EOF token
# at this point INTEGER PLUS INTEGER sequence of tokens
# has been successfully found and the method can just
# return the result of adding two integers, thus
# effectively interpreting client input
result = left.value + right.value
return result
def main():
while True:
try:
# To run under Python3 replace 'raw_input' call
# with 'input'
text = raw_input('calc> ')
except EOFError:
break
if not text:
continue
interpreter = Interpreter(text)
result = interpreter.expr()
print(result)
if __name__ == '__main__':
main()
Kodları incelemeden önce, komut satırından çalıştırıp kendisi ile biraz oynayın! Aşağıda bir kaç örnek bulunuyor.
➜ ~ python2 calc1.py
calc> 3+5
8
calc> 2+6
8
calc> 8+7
15
calc> 1+9
10
calc>
Hesap makinenizin sorunsuzca çalışması için, girilen verinin bazı kurallara uyması gerekiyor:
- Sadece tek haneli sayılar girebilirsiniz.
- Desteklenen tek aritmetik işlem, toplamadır.
- Girilen karakterler arasında boşluk olamaz.
Bu kısıtlamalar sizleri rahatsız ediyor olabilir. Endişelenmeyin, ilerde çok daha karmaşık hale getirebileceksiniz!
Şimdi, yorumlayıcımızın aritmetik işlemleri nasıl ele aldığını yakından inceleyelim. Yorumlayıcıdan 3+5 gibi bir işlem yapmasını istediğimizde, ilk olarak işlemi “3+5” şeklinde karakter dizisi olarak alır. Bu karakter dizisini anlayabilmesi için, diziyi token dediğimiz parçalara ayırması gerekir. Token, değeri ve türü olan bir objedir. Örneğin, “3” stringinin türü INTEGER (tam sayı) değeri ise 3 olur.
Diziyi parçalarına (tokenlere) ayırma işlemine lexical analysis denir. Yorumlayıcının ilk yapması gereken, girilen karakter dizisini tokenlerden oluşan bir diziye çevirmektir. Yorumlayıcıda bu kısmı yapan bölüme lexical analyzer ya da lexer adı verilir. Bunu farklı yerlerde scanner, tokenizer gibi isimlere görebilirsiniz. Hepsi aynı anlama geliyor.
Interpreter sınıfında bulunan get_next_token metodu bizim lexical analyzerimizdir. Metodu her çalıştırışınızda Interpreter sınıfına verilen girdiden bir sonraki tokeni alıp döndürüyor. Bu metodun işini nasıl yaptığını (nasıl token oluşturduğunu) yakından inceleyelim. Sınıfa verilen girdi, text adı altında bir değişkende saklanıyor. Bu değişkene bağlı olarak bir pos değişkeni de tanımlanıyor. Bu pos değişkeni, karakter dizisinin o an kaçıncı karakterinde olduğumuzu belirtiyor. Karakter dizilerini bir liste gibi düşünebilirsiniz, ilk elemanına ulaşmak istediğinizde, string[0] dediğinizde ilk karakteri almış olursunuz. Diziyi işleyebilmek için, pos değişkeni 0’dan başlar. Bizim Interpreter sınıfına verdiğimiz girdiyi düşünürsek (3+5), ilk karakter ‘3’ olur. Metod, ilk olarak karakterin bir hane olup olmadığını kontrol ediyor ve öyleyse, pos değişkeninin değerini bir arttırıp türü INTEGER değeri 3 olan bir token nesnesi döndürüyor:
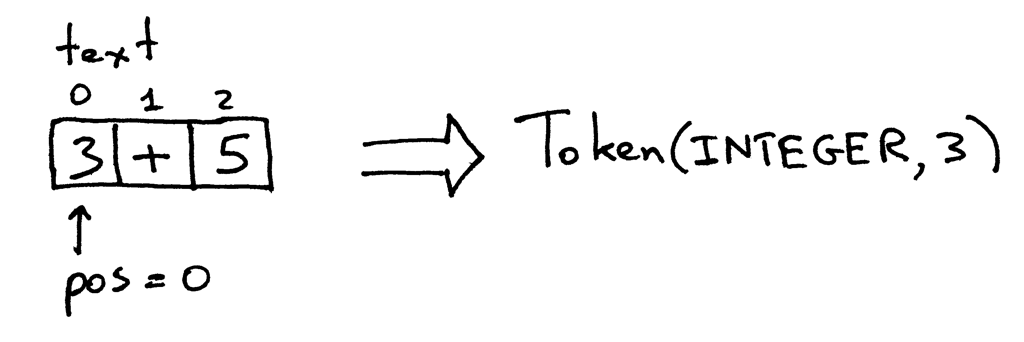
Şu an pos değişkeninin sahip olduğu değer, ‘+’ karakterinin yerini temsil ediyor. Metodu tekrar çağırdığınızda, o karakterin bir sayı mı yoksa artı işareti mi olduğunu kontrol ediyor. Sonuç olarak, pos değişkeninin değeri bir arttırıldıktan sonra, türü PLUS değeri + olan bir token nesnesi döndürülüyor.
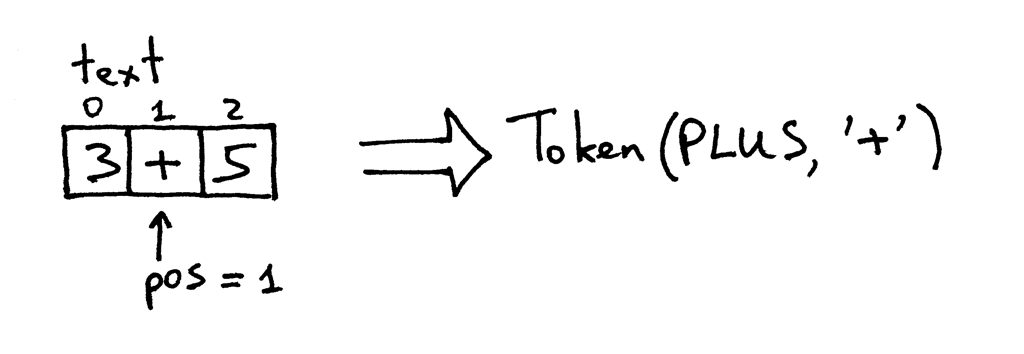
Artık pos’un değeri 2 ve ‘5’ karakterinin konumunu temsil ediyor. Bir daha get_next_token metodunu (metod derken hep bunu kast ediyordum) çağırdığımızda türü INTEGER değeri 5 olan bir token nesnesi döndürüyor. Tabii ki, pos değişkeninin değeri bir arttırıldı.
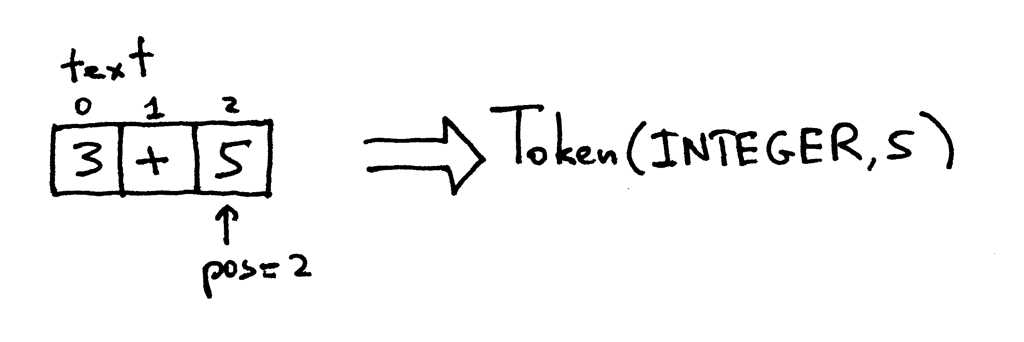
Karakter dizimizin sonuna geldik, artık pos’un değeri 3. Ama 3, karakter dizimizde harhangi bir şeyin konumunu temsil etmiyor. Bu durumda, türü EOF (end-of-file), değeri ise None olan bir token döndürüyoruz.
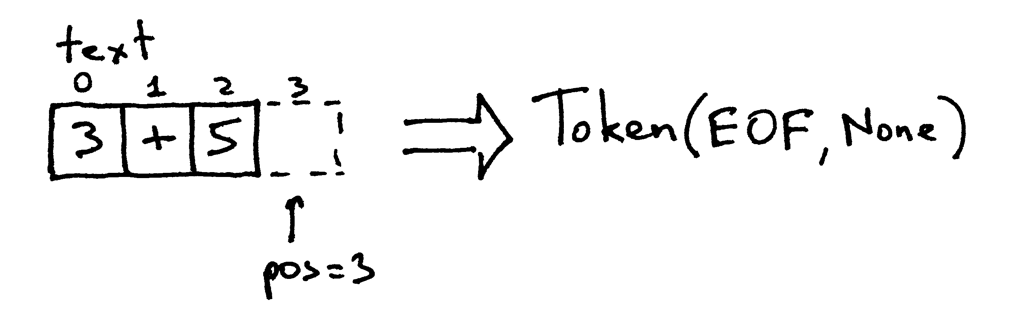
Bunu kendiniz test edebilirsiniz, aşağıda örnek bulunuyor.
>>> from calc1 import Interpreter
>>>
>>> interpreter = Interpreter('3+5')
>>> interpreter.get_next_token()
Token(INTEGER, 3)
>>>
>>> interpreter.get_next_token()
Token(PLUS, '+')
>>>
>>> interpreter.get_next_token()
Token(INTEGER, 5)
>>>
>>> interpreter.get_next_token()
Token(EOF, None)
>>>
Artık yorumlayıcınız Interpreter sınıfına verdiğiniz girdiden oluşturulmuş tamamen tokenler içeren bir diziye sahip. Yorumlayıcı bu diziyi kullanarak bir şeyler yapmalı: tokenlerden oluşan dizide bir yapı bulmalı. Bizim yazdığımız yorumlayıcı, şöyle bir yapı bekliyor: INTEGER → PLUS → INTEGER. Yorumlayıcı, tokenlerden oluşan bir cümle bulmaya çalışıyor: sayı ardından artı ardından sayı.
Bu yapıyı bulup çalıştırmaktan sorumlu metod, expr metodudur. Bu metod ilk olarak, token dizisinin beklenen yapıya (örn: INTEGER → PLUS → INTEGER) uygun olup olmadığını kontrol ediyor. İstenen yapı başarılı bir şekilde sağlandıktan sonra, PLUS’ın solundaki ve sağındaki rakamları toplayıp sonucu oluşturuyor.
İşlemi yapan expr metodunun kendisi, eat adında yardımcı bir fonksiyon kullanıyor. Bu metod, kendisine verilen token türünün current_token tokeninin türüne eşit olup olmadığını kontrol ediyor. Eğer eşitlerse, get_next_token metodunu çağırıp dönen yeni değeri current_token değişkenine atıyor, böylece o an kendisine verilen tokeni etkin bir şekilde “yiyor” ve hayali işaretçiyi token dizisi üzerinde ilerletiyor. Eğer token dizisi beklenen yapı olan INTEGER → PLUS → INTEGER yapısına uymuyorsa, hata mesajı gösteriyor.
Yorumlayıcınızın bir aritmetik ifadeyi değerlendirmek için neler yaptığını tekrarlayalım:
- Yorumlayıcı, bir girdi verisi kabul ediyor, örnek verelim: “3+5”
- Yorumlayıcı, lexical analyzer olan get_next_token tarafından döndürülmüş token dizisinde beklenen yapıyı bulmak için expr metodunu çağırıyor. Aranan yapı bulunduktan sonra, artı işaretinin solu ve sağındaki rakamları toplayarak sonucu döndürüyor.
Kendinizi tebrik edin, ilk yorumlayıcınızı yazdınız! Şimdi biraz egzersiz yapma vakti.

Umarım sadece bu yazıyı okumuş olmanın yeterli olacağını düşünmüyordunuz. Aşağıda uğraşabilmeniz için bir kaç egzersiz bulunuyor:
- Yorumlayıcıyı, sadece rakamlar değil, çok haneli sayılar ile de çalışabilir hale getirin (örn: “12+3”)
- Girdideki önemsiz boşlukları atlayan bir metod oluşturun, yani “12 + 3” ifadesini de işleyebiliyor olsun.
- Yorumlayıcıyı, toplama ve çıkarma yapabilecek hale getirin
Anladıklarınızı kontrol edin:
- Bir yorumlayıcı nedir?
- Bir derleyici nedir?
- Bir derleyici ile yorumlayıcı arasındaki fark nedir?
- Bir token nedir?
- Girdiyi tokenlere ayırma işlemine ne denir?
- Yorumlayıcıda lexical analysis işleminin yapıldığı bölümün adı nedir?
Son
Bu çalışma, bir çeviridir. Yazının İngilizce haline ruslanspivak.com adresinden ulaşabilirsiniz. Toplamda 14 yazıdan oluşan bir seri bu. Zaman buldukça çevirip paylaşmaya çalışacağım.
Blog: r0ark.xyz