Buradaki maç tarihi, maç sonucu, ilk yarı ve ikinci yarı sonucu, karşılaşma, 1.yarı,2.yarı istatistiklerini python ile çekebilen scrapper arıyorum. Varsa öyle bir delikanlı selam ederim.
2 gündür GPT ile uğraşıyorum, yapamadım. Scrapping gerçekten büyük emekmiş.
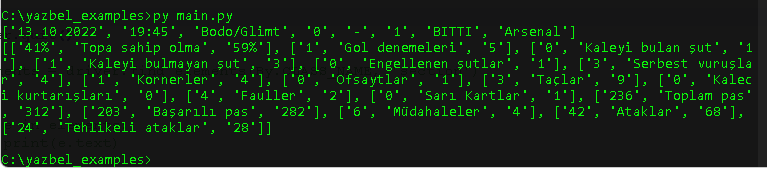
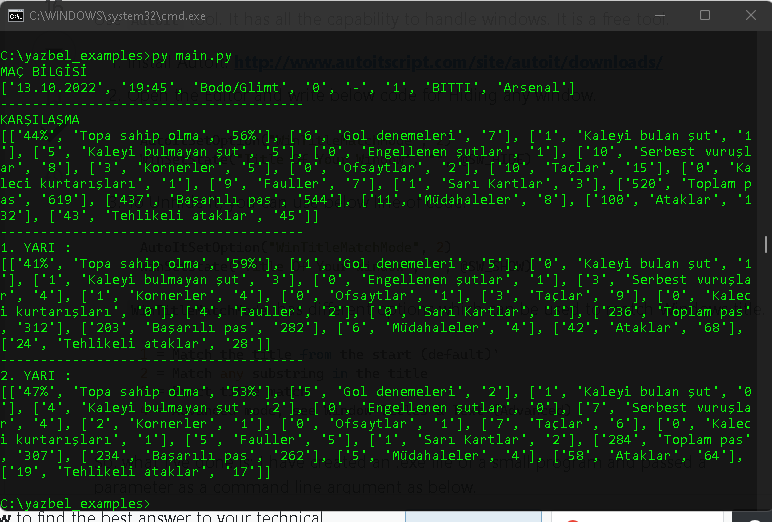
Bir tanesi için örnek çıktı. Verdiğin link, diğer sayfaları da aynı metodla kendin çekebilirsin.
Liste fonksiyonu yazdım bir tane. Tarafların sayısal değerleri ve hangi konuda istatistik olacak şekilde formatladım.
dataların iki dinamik sınıf içinde duruyor.
Bir tanesi: duelParticipant sınıfı içinde;
Diğeri section sınıfı içerisinde;
Hiç karmaşık bir kod yazmadım. Ama chorme yerine firefox kullanıyorum. Mozilla uyumluluğuna güvendiğim için.
Bu nedenle tarayıcıya başlık bilgisi eklmek yada tarayıcıyı non windowed çalıştırmak senin görevin. Basit kodu ıvır zıvırla karıştırmak istemedim.
Sorunun şu: Ve birden çok çözüm yolu var. Ben basiti seçtim.
Bir kere veri kazırken biraz siteye izin ver nefes alsın. Datayı oluşturmak için java script ler kullanılıyor. Bu scriptler tam çalışıp datayı çekmek istersen çuvallarsın. (Ben de çuvalladım.) Scriptlerin çalışması için biraz beklerse datayı çekebilirsin. ( Özelden kodunun bir kısmını görmüş threadlerinden haberim olmuş olmasını sihirbazlık sanmasın kimse.)
Neyse buna dikkat edersen, verdiğin link dışındaki diğer 0,1,2 pagelerinde de datayı sırayla çekebilirsin.
Amma laf salatası yaptım.
Kod:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
driver = webdriver.Firefox()
driver.get("https://www.flashscore.com.tr/mac/nDEQkX6B/#/mac-ozeti/mac-istatistikleri/1")
time.sleep(5)
dynamic_content = driver.find_element(By.CLASS_NAME, "duelParticipant")
output2= dynamic_content.text
list2 = output2.split()
print(list2)
dynamic_content = driver.find_element(By.CLASS_NAME, "section")
output= dynamic_content.text
def format_data(string):
stringler = string.split("\n")
list1 = []
for i in range(0, len(stringler), 3):
list1.append(stringler[i:i+3])
return list1
list1 = format_data(output)
print(list1)
driver.quit()
list1 içerisinde istatistiklerin, list2 içerisinde maç bilgilerin mevcut.
time.sleep(5) opsiyonel, hızlı yükleyeceğine güveniyorsan kaldırabilirsin. Daha doğrusu yorum satırına dönüştür elinde kod nasıl patlar oradan görebilirsin.
Yani ana fikir web scapping yapacaksa site dynamic ise biraz kodumuz frenli çalışmalıymış.
Ha senin kodu gördüm. O threadleri elinde patlatmamak için driver.get() lerden sonra frene nasıl basacağını biliyorsun.
Tabi google, selenium, waiting web page complately load diye aratıp daha şık çözümler de görebilirsin.
Her üç sayfa için yap demezsin herhalde o kısmı halledebilirsin.
Yukarda bahsettim aslında web sitesi api ile veriyi alıp js ile yayınlıyor bende api ile veriyi çekmeyi ve sonradan ayrıştırmayı daha mantıklı buldum ama bir sorunla karşılaştık gelen veriler içerisinde tarih ve saat bilgisi yok. Onuda başka bir kitaplık aracılığıyla hallettik ama hızı ciddi ölçüde düşürdü
Mantıksız değil, hatta imkan olsa doğrudan verilerin bulunduğu veri tabanından çekmek de hız anlamında mantıklı olabilir.
Bu da gayet normal bir durum, çünkü sayfanın farklı bölgelerini faklı yerlerden dolduruyor.
Kritermizin hız olduğunu başlıkta yada konuda göremiyoruz, özel mesajda ben de hız konusundaki kaygıyı farkettim.
Ama hala sorun şu benim açımdan, bu ciddi hız farkı ne kadarlık bir hız farkı.
Veriyi çekebilmek ve işleyebilmek ayrı bir husus, ama bunu hızlı bir biçimde yapmaktan bahsediyorsak bir beklentimiz de olmalı.
Bu beklentiyi de merak ettim. Bu nedenle sordum. Borsa verisi gibi anlık takip gerektiren bir durum mu var, ki olabilir maç süresince bahis oynamak gibi bir durum varsa ancak hız endişesi anlamlı gelebilir diye düşündüm.
Hız, genel olarak hayatımızın bir parçası. Hızlı olmaya mecburuz, her şeyden önce.
Hız farkına gelince, Muhammet’in önerdiği şekilde veriyi en fazla 2 saniyede işliyorum.
Driver kullanınca hızı ölçtüm 64 saniyeye çıktı, multithread kullandım 30 saniyelere düştü. Ama yine de yeterli olmuyor.
Evet öyle ama gelen verileri incelediğimde hiçbir yerde tarih ve saat bilgisine ulaşamamak beni şaşırttı nerden bu bilgiyi çektiklerini hala merak ediyorum. Js kodlarında saat ve tarih bilgisinin bulunduğu etiketin oluşturulduğu kod satırını buldum ama orada da herhangi bi içerik çekme durumu yoktu.
Tabi ki, ne kadar hızlı o kadar iyi. Ama başlığa bakan biri, veriyi çekemediğinde ilk sorun olarak acaba, sitede bir koruma mı var neden veriyi çekmekte sorun yaşamış demez mi? Nereden bilsin hız kaygısını. Bunu da belirtmekte fayda var diyorum.
Threadden verim almak beklediğim bir durum değildi zaten.
Driver kullanılrken 64 saniye ölçtüğün kısım sayfanın yüklenmesinden itibaren mi yoksa, sorguyu aldığı kısım mı?
Tabi ki araya driver sokmadan request etmek daha fazla hız farkı yaratır, ama bu derecek bir fark var mı ölçmedim ölçeyim bakayım.
Teşekkürlük bir durum yok, zihin jimnastiği yapıyorum, senlik bir durum değil, koşullara göre kurcalamak verim artırmak gibi hususlar ilgi alanım ondan irdeliyorum.
Çok üzerinde düşünmedim, sonuçta maç saati süresince oluşacak istatistik, ama sürekli maç saati güncellemekle doğrudan bağlı değil, aynı frame yada aynı region içinde bile tutmak zorunda değil. Vardır bir yerlerde bakarım ucundan. Görürsem şuradan generate etmiş derim.
İçerik çekmeyi dışarda update eden başka bir script yürüyordur söylediğim gibi bakmak lazım.
Burada driver yerien request tabi hızlı olur, ama analiz için bağlantı hızı, sistem hızı gibi değişkenleri de düşünüyordum. Hız konusu saniyeler bazında ciddi fark yaratıyorsa zaten çok da driverın öne geçebileceğini düşünmüyorum.
Görmek için bakmak lazım. Bakarsa başlığa eklerim.
Arada, 2 saniye ile 30 saniye olan bir sorgudan bahsediyorsak driver anlamsız duruyor, ama script erişim yetkisi vermiyorsa driver hala ihtiyaç mıdır diye düşünmek lazım. Tabi her türlü etrafından dolanılabilir.
Yüce semtex, chatgpt ile bir türlü şunu halledemedim, find_all ları selectleri kullandım, ama yapamadım. sadece şu kimliklere ulaşmak istiyorum: https://www.flashscore.com.tr/
Buradaki maçların <div id="g_1_0ltH1oZ5" title="Karşılaşmanın detayları için tıklayınız!" elementtiming="SpeedCurveFRP" class="event__match event__match--scheduled event__match--twoLine"><div class="eventSubscriber eventSubscriber__star eventSubscriber__star--event"><svg class="star-ico eventStar"><title></title>
buradaki gibi her maç için g_1_0ltH1oZ idsi var, bunları çekmek istiyorum.
mesela: