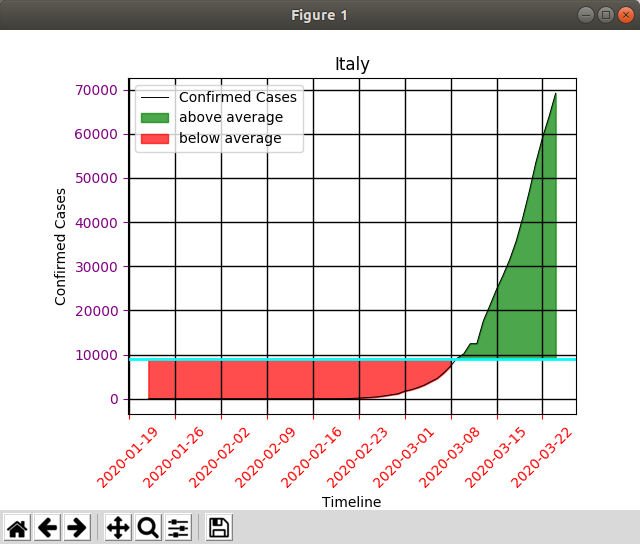
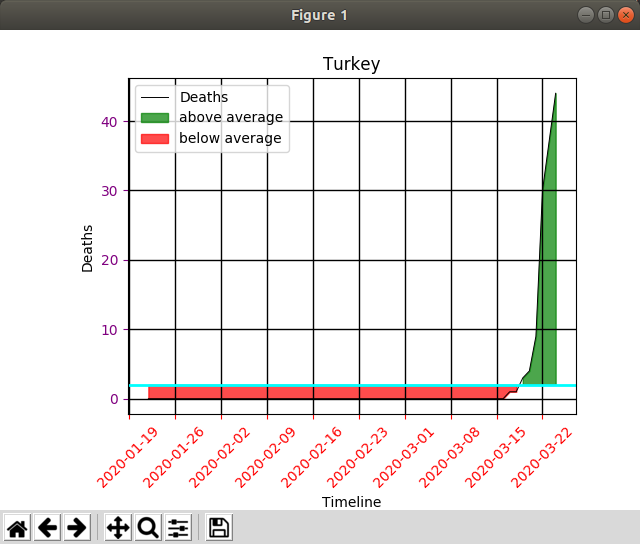
Merhaba arkadaşlar, bu sıralar gündemimizi meşgul eden Covid-19 virüsünün zaman içinde ülkelerdeki artış miktarı verilerini kullanan bir program hazırladım.
Veriler Covid-19 Cases Data sitesinden temin edilmektedir. İlgili olan arkadaşlar aşağıdaki github adresinden programı temin edebilir ve verileri paylatığım siteden indirip programı kullanmaya başlayabilir.
Bir süredir İngilizce dünyaya egemen bir dil. Dolayısıyla genelde programların dili İngilizce oluyor. Şayet Arapça dünyaya egemen bir dil olsaydı, o zamanda da programların dili çoğunlukla Arapça olurdu.
Python’ın geliştiricisi Guido Van Rossum Hollandalı. Ama Python’ın söz dizimi İngilizce. Bu tür konularda seçilen dil genelde dünyaya egemen olan dildir. Ve böyle konulara milliyetçilik gözlüğü ile bakılmaz.
Türklere yönelik olarak bir program tasarlayıp dili Türkçe yapabilirsiniz. Ama dünyanın birçok yerinde yaşayan insanlara yönelik bir program yapıyorsanız, ya her dil için bir dil paketi geliştirmeniz gerekir ki bu da bir ekip eşidir, ya da bunu yapamıyorsanız dünyada o dönem geçerli olan dili kullanırsınız.
Dosyaları değiştirmek yerine yeni dosyalar oluşturmayı tercih ediyor site.
Mesela şöyle dosyalar var:
time_series_2019-ncov-Confirmed.csv
DEPRECATED: Original wide form (new column for each day)
time_series_2019-ncov-Deaths.csv
DEPRECATED: Original wide form (new column for each day)
time_series_2019-ncov-Recovered.csv
DEPRECATED: Original wide form (new column for each day)
Dolayısıyla programın seçtiği dosya bir süre sonra güncelliğini yitirecek ve yeni dosyanın linki de yanılmıyorsam farklı bir linkte olacak.
Evet, archived_times kısmında yer alıyor. En son 23 Mart’ın verileri girilmiş. Hatta her ülke için 23 Mart’ın verileri de yok. Yanılmıyorsam listedeki bütün ülkeler için belirli bir güne ait veriler tamamlanınca humdata sitesindeki dosyayı güncelliyorlar. Mesela humdata sitesindeki veriler en son 22 Mart’a kadar.
Aslında benim de niyetim buydu da, baktım ki güncel dosya sürekli farklı bir linke aktarılacak, ben de bu yüzden hiç uğraşmak istemedim. Ama dediğiniz de yapılabilir tabi.
import requests as rq
from bs4 import BeautifulSoup as BS
r = rq.get("https://data.humdata.org/m/dataset/novel-coronavirus-2019-ncov-cases")
soup = BS(r.text, "html.parser")
ul = soup.select_one(".hdx-bs3.resource-list")
a = BS(str(ul), "html.parser").select_one('a[title="Download"]')
link = "https://data.humdata.org" + a["href"]
data = rq.get(link).content
with open("time_series_covid19_confirmed_global.csv", "wb") as f:
f.write(data)
import urllib.request as request
data = request.urlopen("https://data.humdata.org/hxlproxy/api/data-preview.csv?url=https%3A%2F%2Fraw.githubusercontent.com%2FCSSEGISandData%2FCOVID-19%2Fmaster%2Fcsse_covid_19_data%2Fcsse_covid_19_time_series%2Ftime_series_covid19_confirmed_global.csv&filename=time_series_covid19_confirmed_global.csv")
for row in [i.replace("\r", "").split(",") for i in data.read().decode("utf-8").split("\n") if i]:
print(row)
Hmm, aslında şöyle daha kısa oluyor. ul'e girmeye hiç gerek yok. Listenin ilk iki elemanı en güncel dosyalar. Birisi vaka sayısı, ikincisi de ölüm sayısı.
import requests as rq
from bs4 import BeautifulSoup as BS
r = rq.get("https://data.humdata.org/m/dataset/novel-coronavirus-2019-ncov-cases")
soup = BS(r.text, "html.parser")
links = ["https://data.humdata.org" + i["href"] for i in soup.select('a[title="Download"]')]
print(links)