Merhaba , yaptığım bu kodlamada herhangi bir hata da almıyorum ama çıktı da alamıyorum , iş bankasının sitesinden bilgiyi çekmeye çalışıyorum. Nerede eksik birşey yaptığımı söylerseniz sevinirim.
Sayfa url kısmı hatalı ilk gözüme çarpan o oldu.
Makas farkı amma çok artmış. Döviz de alım satımı yapılamıyor.
Selam aslında yanlış değildi de ben foruma yazınca direk yönlendirme şeklinde çıkmış , onu düzenledim postta , sorun halen devam ediyor
Daha önce hiç internetten veri çekme ile uğraşmadım ama sanırım sitenin bot koruması gibi bir şey var orijinal siteye yönlendirmiyor.
bunu hiç düşünmedim tabi ama olay bundan kaynaklıysa hata verir miydi yoksa hiç sonuç vermeden öylece durur muydu? Hata almadığımı ekleyeyim bu arada…
gösterdiğin şey mantıklı geldi teşekkürler , başka bir fikri yada yanlışımı gören varsa paylaşabilirse sevinirim
import requests
from bs4 import BeautifulSoup
URL ={"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"}
cagrigungor=requests.get("https://www.isbank.com.tr/doviz-kurlari",headers= URL)
sayfakaynagi=cagrigungor.content
soup=BeautifulSoup(sayfakaynagi,"html.parser")
result = soup.find_all("div", {"class":"dk_MC"})
for res in result:
print(res.decode_contents().strip())
Anlamsız bir kod ama, dümdüz dk_MC de olduğu gibi veriyi çektim.
Tabi parse edip düzenlemek size kalmış.
Veri çekmekte sitede herhangi bir kısıtlama göremedim.
1 Beğeni
o zaman hatayı nerede yapıyorum acaba bulabilen varsa belirtirse sevinirim , yoksa da yardımlar için teşekkürler.
import requests
from bs4 import BeautifulSoup
URL ={"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"}
cagrigungor=requests.get("https://www.isbank.com.tr/doviz-kurlari",headers= URL)
sayfakaynagi=cagrigungor.content
soup=BeautifulSoup(sayfakaynagi,"html.parser")
for icerik in soup.find_all("div", {"class":"dk_MC"}):
print(icerik.prettify())
dovizCinsi=icerik.find("span").text
dovizAlis=icerik.find_all("td")[1:][0].text
dovizSatis=icerik.find_all("td")[1:][1].text
print(dovizCinsi,dovizAlis,dovizSatis)
Bu aradığın yapıyı görmene yanrdımcı olur özellikle for altındaki koduna dokunmadım.
soup.find_all("tr",{"class":"dk_L0"}):
tr altında L0 bakıyorsun.
soup.find_all("div", {"class":"dk_MC"}):
ben dk_MC altında baktığımda.
Tüm yapıyı listeliyor.
Burada for altındaki tekra hangi verileri yazıracağınızı kendiniz ayarlayabilirsiniz.
tamamdır çözümünüz yeterli çok teşekkürler , ben hala bendeki sorunu anlayamadım ama en azından alternatif bir çözüm gördüm bu şimdilik yeterli teşekkürler =)
Kusra bakmayın ayak üstü bakabildim.
Bir kaç ihtimal var kodunuza tamamen bakmadım.
URL ={"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"}
Satırı ile siteye bir başlık bigisi gönderdik. Bazan siteler başlık bilgisi olmayan istekleri cevaplamayabiliyor.
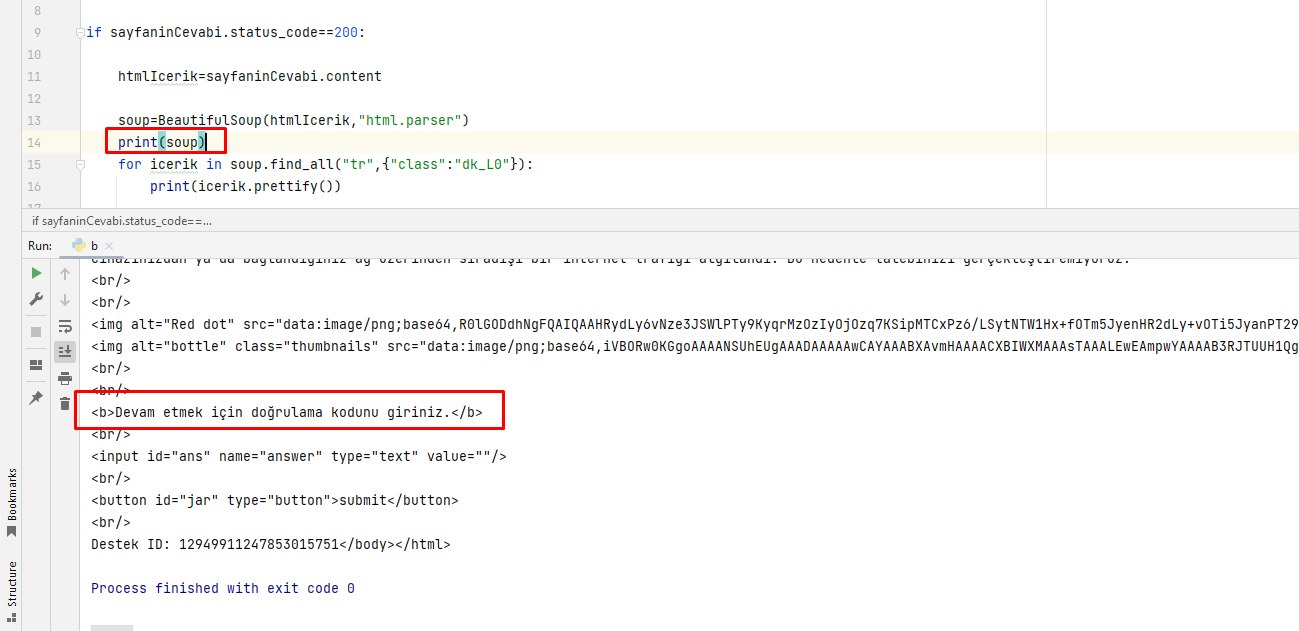
if sayfaninCevabi.status_code==200:
Kontrolünden sonra datayı çekmek istiyorsun, belki burada status kod gecikiyor yada doğru dönmüyor bakmak gerekir.
Üçüncüsü
soup.find_all("div", {"class":"dk_MC"})
ile dk_MC sınıfının tamamını çağırdım.
Siz sadece L0 a ulaşmaya çalışmışsınız.
Dördüncüsü
dovizCinsi=icerik.find("span").text
dovizAlis=icerik.find_all("td")[1:][0].text
dovizSatis=icerik.find_all("td")[1:][1].text
ile parse ederken sorun yaşamış olabilirsiniz. Çünkü sınıf yapısını iyi incelemek gerekiyor.
İçinde ikon listeleri de var sanırım ve alamadığında yada metne çeviremediğinde ne davranış sergiliyor bilemedim.
Yani birden çok yerde birden çok ihtimaldeki kodunuzu adım adım çalıştırıp bakmak gerekir ki, ven metin dosyasında yazıp, terminalden doğrudan çalıştırıp baktım.
import requests
from bs4 import BeautifulSoup
URL ={"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"}
cagrigungor=requests.get("https://www.isbank.com.tr/doviz-kurlari",headers= URL)
sayfakaynagi=cagrigungor.content
soup=BeautifulSoup(sayfakaynagi,"html.parser")
for icerik in soup.find_all("tr", {"class":"dk_HdrTr"}):
print (icerik.text)
for icerik in soup.find_all("tr", {"class":"dk_L0"}):
temp= icerik.text
print(temp.strip())
for icerik in soup.find_all("tr", {"class":"dk_L1"}):
temp=icerik.text
print(temp.strip())
Şeklinde kodu biraz daha basitleştireyim. Zaten bir kaç satır bir kod.
Burada siz icerikleri nasıl böleceğinize kendiniz karar verirsiniz.
1 Beğeni
sadece dk_L0 çağırmamın nedeni aslında döviz bilgilerinin o satırlarda olmasıydı.Dediklerinizden 4.'sünün olma ihtimali yüksek bu konuları da yeni öğrendiğimden o kısım hakkında çok bilgim yok.bilgilendirmeler için teşekkürler.
Yapı şu şekilde.
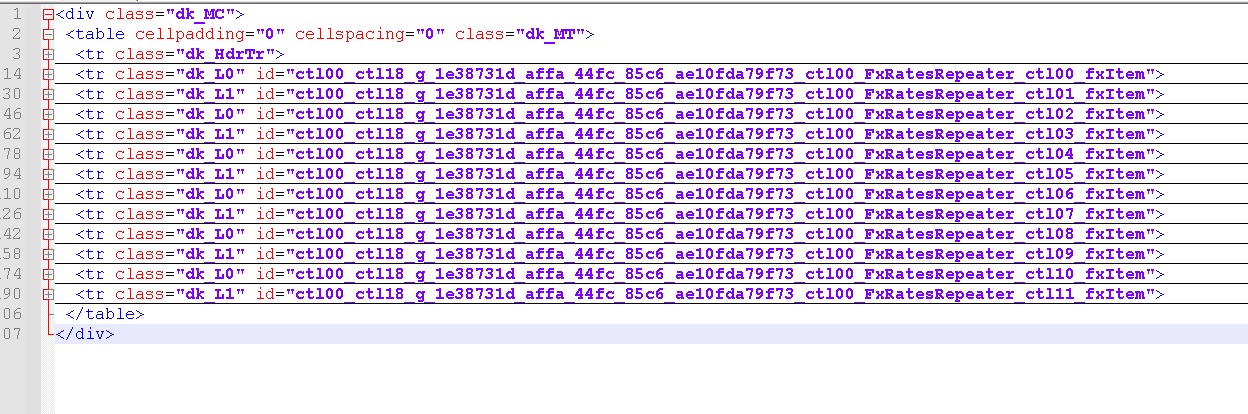
Bazı dövizler L0, Bazılar L1 içinde.
Mesela Euro dk_L1 içerisinde gördüm.
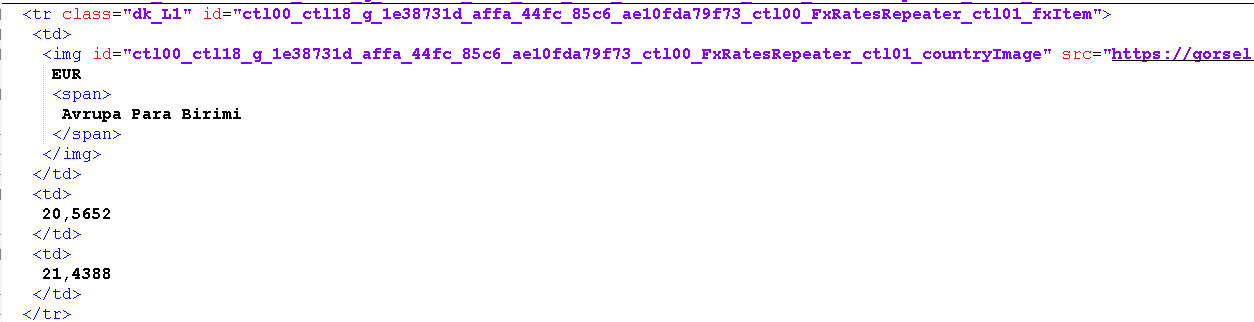
Bütün ihtimallere eşit uzaklıktayım. Denemeden yanlış bir şey söylemek istemem.
Olabilir, tabi ki yeni öğrendiğinizden bazı problemler çıkacaktır, siz de sorarak öğrenmeye uğraşacaksınız.
Bir de tabloları okumak için farklı yöntemler var.
python BeautifulSoup parsing table - Stack Overflow
Çünkü okuduğunuz veri bir tabloda ve tablo olarak okumak da bir başka yöntem.
1 Beğeni
L0’dan sonra L1 classlarını da çağırıcaktım (bütün döviz bilgileri bunların içinde olduğundan) ama işte çalıştıramayınca devamını getiremedim .
son bir soru şu parser mevzusunu tam anlayamıyorum , birkaç yere de baktım hiç bilmeyen biri için çok açıklayıcı birşey göremedim , bu kodlamalarda parser’în kullanımdaki anlam olarak a karşılığı nedir ?
Haklısınız. Ağız alışkanlığı herkes aynı terimi kullandığından bilindiği düşünülüyor.
Bir çok farklı şekilde anlatılabilir.
Sizin elde ettiğiniz data/bilgi bir ağaç yapısında;
Sınıf etiketlerinin altında başlık bilgileri, tablo bilgileri gibi bilgiler tag adı verilen etiket simgelerinin arasında tanımlanıyor.
tr, dk_L0, dk_MC buradaki etiketlerden bazıları.
Aslında biz bu etiketleri değil, bunların arasındaki datayı/ bilgiyi kullanıyoruz.
İşte bu bilgileri elde etmek, almak için kullandığımız ağaç yapısından çeken yardımcı koda parser diyebiliriz.
Programlama terimi olarka da kullanıyoruz, fakat burada kullandığımız, biraz daha spesifik bir durum.
Özetle html kodları içindeki, tag/etiket ler arasındaki hiyeyarşik ilişkiye dikkat ederek arasındaki data/bilgileri alan kod/yardımcı kod diyebiliriz.
1 Beğeni
çok teşekkürler yeniden bütün yardımlarınız için!’