Çok yeniyim o yüzden paylaşım yaparken yanlış ya da eksik bilgi verdiysem özür dilerim. Şöyle benim çalışmamın tam halini o zaman paylaşıyorum.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from seaborn import heatmap
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.preprocessing import MinMaxScaler
from sklearn.neural_network import MLPRegressor
import matplotlib.style as mplstyle
Burada kütüphaneleri yükledim. Daha sonra ben verileri çekip işledim.
plt.style.use('seaborn-white')
csv_file_url = 'http://www.facadium.com.tr/cvd19/nisansonunakadarolanveriler.csv'
dataset = pd.read_csv(csv_file_url, sep = ',', index_col=0)
pd.set_option("display.max.rows", None)
dataset.head(2000)
Ardından grafiğe döktüm tüm veri setindeki verileri.
for i, col in enumerate(dataset.columns.tolist()):
plt.figure(figsize=(10, 6))
x_axis = dataset.index.values
y_axis = dataset[col].values
plt.plot(x_axis, y_axis, label=col,marker='o')
plt.title(col)
plt.xlabel("Günler")
plt.ylabel("Veriler")
counter = 0
for a, b in zip(x_axis, y_axis):
counter +=1
if counter % 60 == 0:
plt.annotate(str(b), xy=(a,b))
Grafiğe döktükten sonra verileri listeledim.
dataset_shifted = dataset.iloc[0:,:]
dataset_shifted.head(2000)
dataset_shifted.describe()
scaler = MinMaxScaler()
dataset_scaled = scaler.fit_transform(dataset_shifted.values)
dataset_scaled = pd.DataFrame(scaler.fit_transform(dataset_shifted),columns=dataset_shifted.columns)
dataset_scaled.index = dataset_shifted.index
dataset_scaled.head(2000)
Ardından korelasyon ile ısı haritasını oluşturdum.
korelasyon = dataset_scaled.corr()
korelasyon
heatmap(korelasyon, xticklabels=dataset_shifted.columns, yticklabels=dataset_shifted.columns)
Daha sonra verilerden tahminler çıkarmaya çalışıyorum. Burada 1,2,4 numaralı verilerden 4 numralı veriyi tahmin etmesini istiyorum.
x = dataset_scaled.iloc[:,[1,2,4]]
y = dataset_scaled.iloc[:,[4]]
x
y
mlp = MLPRegressor(hidden_layer_sizes=(75,), max_iter=10000, learning_rate_init=0.05, random_state=41)
mlp.fit(x.values, y.values)
y_predicted = mlp.predict(x.values)
y_predicted
y.values.round(3)
Buradan aldığım sonuçlarda r2 leri ve array’leri buluyorum.
mean_squared_error(y.values, y_predicted)
r2_score(y.values, y_predicted)
mlp.coefs_[0].round(3)
mlp.intercepts_
Daha sonra grafiklere dökmeye çalışıyorum aldığım veriyi. Ancak verilerimi ekrana dökerken yatay eksende tarihleri düşey eksende verileri görmek istiyorum.
ax= y.plot(linestyle='-')
plt.xlabel("Günler",
fontdict={
'family' : 'Times New Roman',
'color' : 'black',
'size' : 14
})
plt.ylabel("Veriler",
fontdict={
'family' : 'Times New Roman',
'color' : 'black',
'size' : 14
})
plt.title("Tek Katmanlı Ağır Hasta Sayısı Grafiği",
fontdict={
'family' : 'Times New Roman',
'color' : 'black',
'size' : 20
})
plt.legend()
plt.grid()
Burada aldığım grafikte yatay eksende veriler tarih olarak geliyor ancak düşey eksende veriler 0-1 arasında ölçekleniyor. Onun yerine şunu denemek istedim.
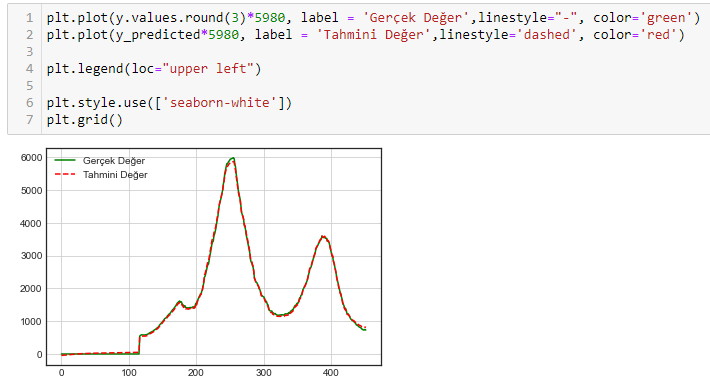
plt.plot(y.values.round(3)*5980, label = 'Gerçek Değer',linestyle="-", color='green')
plt.plot(y_predicted*5980, label = 'Tahmini Değer',linestyle='dashed', color='red')
plt.legend(loc="upper left")
plt.style.use(['seaborn-white'])
plt.grid()
Ama bu sefer de düşey eksende verileri alıyorum ama yatay eksende tarih yerine tarihlerin sıra numarasını görüyorum.
Ben iki veriyi ( gerçek değerler, tahmini değerleri) aynı ekranda çizdirmek ve düşey eksende verileri yatay eksende ise tarihleri görüntülemek istiyorum ancak yapamıyorum. Burada tıkandım. Umarım derdimi anlatabilmişimdir.