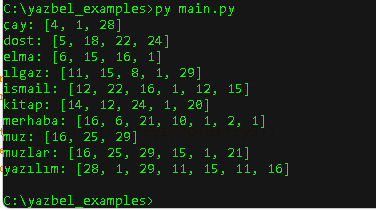
Kodunuz çok uzun biraz kısalttım.
liste = ['elma', 'yazılım', 'merhaba', 'muzlar', 'kitap', 'çay', 'ismail', 'muz', 'dost','ılgaz' ]
harf_degerleri = {
'a': 1, 'b': 2, 'c': 3, 'ç': 4, 'd': 5, 'e': 6, 'f': 7, 'g': 8, 'ğ': 9, 'h': 10,
'ı': 11, 'i': 12, 'j': 13, 'k': 14, 'l': 15, 'm': 16, 'n': 17, 'o': 18, 'ö': 19, 'p': 20,
'r': 21, 's': 22, 'ş': 23, 't': 24, 'u': 25, 'ü': 26, 'v': 27, 'y': 28, 'z': 29
}
sayisal_degerler = list(map(lambda kelime: list(map(lambda harf: harf_degerleri.get(harf.lower(), 0), kelime)), liste))
siralanmis_kelimeler = sorted(zip(liste, sayisal_degerler), key=lambda x: x[1])
for kelime, sayisal_degerler in siralanmis_kelimeler:
print(f"{kelime}: {sayisal_degerler}")
Bilgisayar Türkçe, ingilizce, almanca bilmez. Bilgisayar rakam bilir.
Harfleriniz alfabelere göre sayısal maplerseniz. Sıralama algoritmalarınızı da bu sayı dizilerini sıralayacak şekilde yazarsanız, her dil için yapmanız gereken tek şey alfabe dizisini sayısal karşılıkta ifade etmektir.
Daha sonra aldığınız kararlara göre sıralama koşulu belirleyip, bubble sort, quick sort, selection sort hangi metodla sıralamak isterseniz o metodla sıralarsınız.
Burada kullandığınız sıralama algoritması size iterasyon sayısı dışında bir fark yaratmayacaktır. İterasyon endişeniz varsa algoritma performanslarına bakar birini seçersiniz.
Son olarak, kodunuz çok uzun okuyup hatası nedir diye bulmak yerine basit bir örnek yazmak daha kolay gibi geldi bana.
Burada sizin istediğiniz kodu yazmadım, sadece bir sıralama algoritması ve bir sayısallaştırma göstermek istedim.
siralanmis_kelimeler = sorted(zip(liste, sayisal_degerler), key=lambda x: x[1])
satırında sıralama sayısal_deger listesine göre yapılır, siz harf olarak yapmak isteseniz x[0] ile sıfır indeksi verip alfabetik olan sıralama ile farkına bakabilirsiniz böylece sayısal sıralama size her zaman kodladığınız alfabeye göre sıralacaktır.
Tabi farklı koşul ve istekleriniz varsa satırı silip kendi sıralama algoritmalarınızı o satırla değiştirebilirsiniz.
Kolay gelsin.
EDIT:
Yukarıdaki kısım zaten komple geresiz döngünün daniskası anlamında bir mesaj idi. Can sıkıntısı hadi bakalım kodu ayıklayıp bir analiz etmeye çalışayım dedim.
Tamam anlıyorum. Tabi ki sıralama algortiması yazmak istemeniz normal lakin optimize edilmiş algoritma yerine kendiniz denemeniz de bir yere kabul edilebilir lakin kafamda deli sorular:
Mesela liste deki eleman sayınız ile aldığınız 512 arasında bir bağıntı var. 2 üzeri n-1,
yani 2 üzeri (10-1) = 2 üzeri 9 = 512 ve her eleman eksiltip denediğimde bu formüle göre değer hesaplaması doğru çıkıyor.
Hele bir kontrol değişkeniniz var bu kontrol değişkeni ile ne hesaplamaya çalıştığınızı hiç anlamadım.
Yani iterasyon sayısı desem j değişkenli for döngüsünde artırmamışsınız sonuçta orada da bir for döngüsüne giriyor.
i ile z yi takip ediyor desem neden böyle bir şey yapmak ister insan onu da anlamadım.
Birinci listeden eksiltip ikinci listeye ekleyerek yapsa desem o da değil. i ile başlayan for döngüsü sürekli 9 a kadar sayıyor.
z döngüsü ap ayrı bir dünya;
z döngüsünde ne yaptınız da z 512’ye kadar gitti diyeceğim, geri doğru taradım baş tarafı daha anlamsız bir halde.
Acaba bende mi problem var deyip, can sıkıntısından chatgpt ye sordum:
Elin delli chatgpt si şunları yazdı:
Bu kod bir liste üzerinde alfabetik sıralama yapmaya çalışıyor gibi görünüyor. Kodun işleyişini analiz edelim:
1. `alfabetik_siralama` adında bir fonksiyon tanımlanmış. Bu fonksiyon bir liste alıyor ve alfabetik sıralanmış bir listeyi döndürmeyi amaçlıyor.
2. `donecek_liste` adında boş bir liste ve `kontrol` adında bir sayı tanımlanıyor.
3. Bir `for` döngüsü kullanarak, `liste`nin elemanlarını tek tek işlemeye başlıyoruz.
4. İlk adımda (`i == 0`), `donecek_liste`'ye `liste`'nin ilk elemanını ekliyoruz ve `kontrol` değişkenini artırıyoruz.
5. İkinci adımda (`i > 0`), `donecek_liste`'deki elemanlarla karşılaştırma yapmak için bir iç içe `for` döngüsü kullanıyoruz.
6. İç içe `for` döngüsünde, `donecek_liste`'nin elemanlarını (`donecek_liste[z]`) `liste`'nin `i`'nci elemanıyla (`liste[i]`) karşılaştırıyoruz.
7. Karşılaştırma yaparken, `alfabe.index()` fonksiyonunu kullanarak harflerin alfabetik sıralamadaki indekslerini karşılaştırıyoruz.
8. Eğer `donecek_liste[z][j]` harfi, `liste[i][j]` harfinden önce geliyorsa, `liste[i]`'yi `donecek_liste`'ye ekliyoruz ve iç içe döngüden çıkıyoruz (`break`).
9. Eğer iki harfin indeksleri eşitse, her iki kelimenin de aynı kısmını karşılaştırıyoruz (`j` değişkeni ile kontrol ediyoruz).
10. Eğer karşılaştırma sonucunda aynı kısma kadar her iki kelime de aynı ise, uzunluğa göre kısa olan kelimeyi `donecek_liste`'de önce yerleştiriyoruz.
11. Eğer `donecek_liste[z][j]` harfi, `liste[i][j]` harfinden sonra geliyorsa, bu durumda `donecek_liste[z]` ile `liste[i]`'yi yer değiştiriyoruz.
12. `else` bloğunda herhangi bir durumun sağlanmadığı durumları kontrol ediyoruz.
13. İç içe döngülerden çıktıktan sonra, `donecek_liste`'deki elemanları tekrar sayarak (`donecek_liste.count()`) eğer bir elemandan birden fazla varsa, fazla olanları silme işlemi yapılıyor (`donecek_liste.remove()`).
14. Son olarak, `donecek_liste` ve `kontrol` değerleri yazdırılıyor.
Kodun bazı eksiklikleri ve
iyileştirmeleri şunlar olabilir:
- `alfabe` adında bir alfabe dizisi veya liste tanımlanmamış. Bu nedenle, `alfabe.index()` fonksiyonunun nasıl çalıştığına bağlı olarak bu kısım hata verebilir. Alfabe tanımlamasını kodun başına eklemeniz gerekebilir.
- Kodun okunabilirliği ve anlaşılırlığı düşük. Değişken adları ve kod bloklarının daha açıklayıcı olması önemlidir.
- Kodda aşırı döngü kullanımı var, bu da performansı olumsuz etkileyebilir. Daha etkili bir sıralama algoritması kullanarak bu sorunu çözebilirsiniz, örneğin `sorted()` fonksiyonunu kullanabilirsiniz.
- Fonksiyonun sonucunu döndürmesi yerine, doğrudan yazdırıyor. Fonksiyonun bir liste döndürmesi daha kullanışlı olabilir, böylece sonucu başka bir değişkene atayabilir veya başka işlemlerde kullanabilirsiniz.
Bu analizin size yardımcı olması umuduyla! Eğer başka bir sorunuz varsa, sormaktan çekinmeyin.
Söylediklerinin çoğuna katıldım, bu kadar iç içe for döngüsü yazarsa algoritma performansı düşer en çok katıldığım,
Bir diğer söylediği ise, fonksiyon dönüşünde liste versin fonksiyonun içinde print kullanılır mı?
Yani yapay zeka bile bir fonksiyon nasıl tanımlanır de değer döndürebilir nasıl bir mantıkla fonksiyonun içinde liste değeri döndürmek yerine ekrana yazdırılır diye merak etmiş.
Ben de merak ettim açıkcası:
Neyse başta söylemiştim, sıralama algoritmaları çeşit çeşit performans ve güçlü yönlerine göre birini seçebilirdiniz, inanın bu seçtiğinizin adını koyamadım, bubble desem değil, quick sort desem değil, heapsort desem değil, quick sort desem değil.
İlk listeden bir değer çekti isem ilk listem neden 1 azalıp da 9, 8,7 diye azalmıyor da her seferinde 9 döngü dönüyor bilemedim.
Hele z döngüsü 2 nin üsleri şeklinde nasıl şişti anlamadım. Çok daha da ilginci var if lerden kaynaklı olabilir, j ye kaç kez uğradığına bakınca daha da garipsedim.
liste=['elma', 'yazılım', 'merhaba', 'muzlar', 'kitap', 'çay', 'ismail', 'muz', 'dost','ılgaz']
alfabe=list(i for i in "abcçdefgğhıijklmnoöprsştuüvyz")
def alfabetik_siralama(liste):
donecek_liste = list()
kontrol = 0
for i in range(len(liste)):
if i == 0:
kontrol += 1
donecek_liste.append(liste[i])
else:
for z in range(len(donecek_liste)):
kontrol += 1
uzunluk = min(len(donecek_liste[z]), len(liste[i]))
for j in range(uzunluk):
if alfabe.index(donecek_liste[z][j]) < alfabe.index(liste[i][j]):
donecek_liste.append(liste[i])
break
elif alfabe.index(donecek_liste[z][j]) == alfabe.index(liste[i][j]):
print(" i:{}, z:{}, j:{}, kontrol:{}".format(i, z, j, kontrol))
#print("buraya {} ile {} için {} defa bakıldı".format(donecek_liste[z], liste[i], j + 1))
if j == uzunluk - 1:
a = len(liste[i]);
b = len(donecek_liste[z])
if a == b:
donecek_liste.append(liste[i])
elif a < b:
gecici = donecek_liste[z]
donecek_liste[z] = liste[i]
donecek_liste.append(gecici)
break
else:
donecek_liste.append((liste[i]))
break
elif alfabe.index(donecek_liste[z][j]) > alfabe.index(liste[i][j]):
gecici = donecek_liste[z]
donecek_liste[z] = liste[i]
donecek_liste.append(gecici)
break
else:
pass
#for i in donecek_liste:
# if donecek_liste.count(i) > 1:
# for j in range(donecek_liste.count(i) - 1):
# donecek_liste.remove(i)
#print(donecek_liste, kontrol, sep="\n")
alfabetik_siralama(liste)
Kodunuzu biraz budadım. Mesela garip çıktı aldığınız fonksiyonun içindeki forlu en alt çıktı alma kısmını yorum satırına değiştirdim.
Sonra, buraya uğradı falan yazan satırınızda durum nedir diye merak ettim.
Burayı da yoruma çevirip,
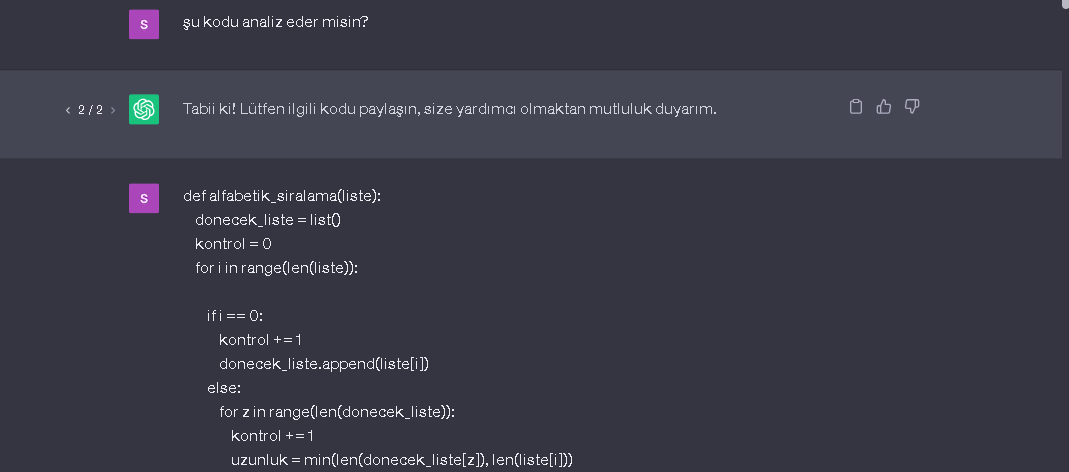
print(" i:{}, z:{}, j:{}, kontrol:{}".format(i, z, j, kontrol))
Satırı ile uğradığı durumlarda, x, z, j ve kontrol değişkenlerinizin değerlerine baktım. Kodu çalıştıralım;
Sizin uğradığını düşündüğünüz yere 16 kere uğramış.
Tamam en içteki z değişkenli for döngüsüne bakalım, if lerden önce bir yere kodumuzu yazalım ki x,z,j ve kontrol değişkenlerinizin tüm durumlarını görelim;
liste=['elma', 'yazılım', 'merhaba', 'muzlar', 'kitap', 'çay', 'ismail', 'muz', 'dost','ılgaz']
alfabe=list(i for i in "abcçdefgğhıijklmnoöprsştuüvyz")
def alfabetik_siralama(liste):
donecek_liste = list()
kontrol = 0
for i in range(len(liste)):
if i == 0:
kontrol += 1
donecek_liste.append(liste[i])
else:
for z in range(len(donecek_liste)):
kontrol += 1
uzunluk = min(len(donecek_liste[z]), len(liste[i]))
for j in range(uzunluk):
print(" i:{}, z:{}, j:{}, kontrol:{}".format(i, z, j, kontrol))
if alfabe.index(donecek_liste[z][j]) < alfabe.index(liste[i][j]):
donecek_liste.append(liste[i])
break
elif alfabe.index(donecek_liste[z][j]) == alfabe.index(liste[i][j]):
#print("buraya {} ile {} için {} defa bakıldı".format(donecek_liste[z], liste[i], j + 1))
if j == uzunluk - 1:
a = len(liste[i]);
b = len(donecek_liste[z])
if a == b:
donecek_liste.append(liste[i])
elif a < b:
gecici = donecek_liste[z]
donecek_liste[z] = liste[i]
donecek_liste.append(gecici)
break
else:
donecek_liste.append((liste[i]))
break
elif alfabe.index(donecek_liste[z][j]) > alfabe.index(liste[i][j]):
gecici = donecek_liste[z]
donecek_liste[z] = liste[i]
donecek_liste.append(gecici)
break
else:
pass
#for i in donecek_liste:
# if donecek_liste.count(i) > 1:
# for j in range(donecek_liste.count(i) - 1):
# donecek_liste.remove(i)
#print(donecek_liste, kontrol, sep="\n")
alfabetik_siralama(liste)
Bu sefer ;
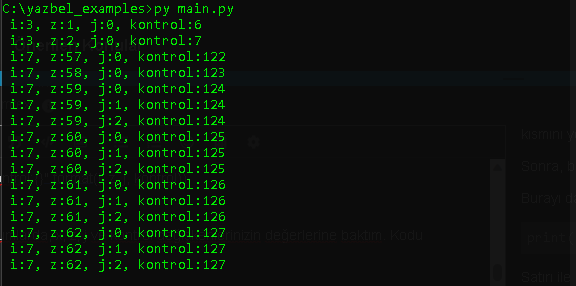
print(" i:{}, z:{}, j:{}, kontrol:{}".format(i, z, j, kontrol))
Satırımızı j döngüsü içerisinde if ile kararlar alınmadan hemen önce bir yere aldık ki sonuçta iç içe, x,z ve j ye nasıl giriyor ve hangi değerleri görüyor biz de görelim.
Ve;
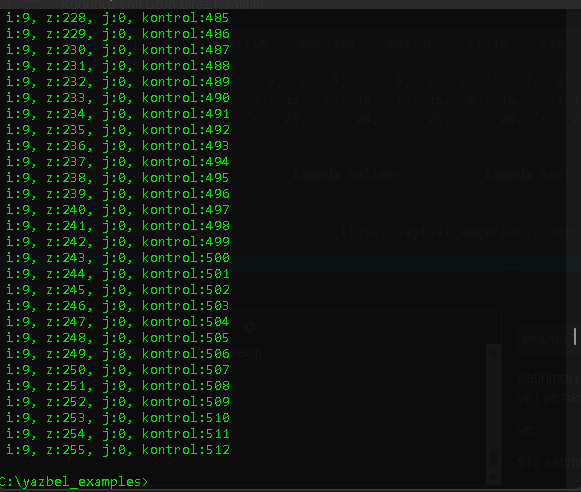
512 satırlık yeni durum:
z değeriniz nasıl 255’e kadar ulaşabildi?
j değişkenli for döngünüze uğradığında kontrol değişkeninizi 1 artırmıyorsunuz.
yani oraya uğradı ise dahi bunlar ilave edilmiyor peki bu durumda siz neyi sayıyorsunuz kontrol ile?
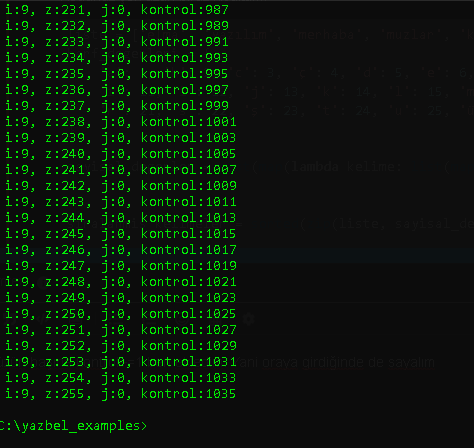
Sizin için j for döngünüzün başına kontrol+=1 ben ekledim. Yani oraya girdiğinde de sayalım dedim.
Bakın sonuç ne oldu?
1035…
Yani döndük başa, iterasyon sayınızı düzgün saymıyorsunuz.
Sıralama algoritmanız en kibar tabirle tuhaf. Ve adını koyamadım.
Bir fonksiyon dönüşünde ekrana yazmaz bir dönüş değeri döndürür sonra o değer ekrana yazdırılacaksa yazdırılır bu şekilde fonksiyon ruhuna aykırı.
listeleri karşılaştırma komutlarını doğru kullanmamışsınız, karşılaştırma komutları ile forlar azaltılabilirdi. Listenizden eleman çektikten sonra yeni listenizi baştan aşağı tekrar tekrar kontrol ederek çığ gibi büyen bir z değişkenli for döngüsüne dönüştürmüşsünüz bunun daha kolay yolu olan sıralama algoritmalarının mantığını hiç anlamamışsınız.
Yine başta söylediğim gibi ana fikri alfabe olsa sayılara kodlarsınız harf sıralama kaygınız ortadan kalkar. Sort kullanmak istemezseniz o tek satırı kendi sıralama fonksiyonunuzla değiştirirsiniz onda da problem yok ama o sıralama fonksiyonu bu sıralama fonksiyonu değil.
Yani evet sıralıyordur ama adımlayıp değerlere bakıyorum bu şekilde çalışan bir kod yazın deseniz yazamam bu karmaşayı ve kaosu yaratmak özel maharet ister.
Onca açıklama satırıyla daha da açıklanamaz ve anlaşılmaz hale getirmeniz de cabası:
#Fonksiyon başlangıç
açıklamanız bomba mesela. Bir fonksiyon def ile tanımlanır diye başlayan bir satır okuyan adam fonksiyon görünce herhalde buradan başlar fonksiyon diyordur, açıklamaya muhtaç görünmüyor.
Diğer yorum satırlarınıza girmiyorum dahi.
Bu şekilde kodunuz daha da okunmaz hale gelmiş. Yorumları silip anlayana kadar göbeğim çatladı.
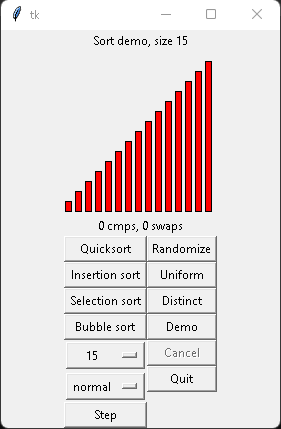
Python ın kurulu olduğu dizinde bir examples yada demos dizini olacak orada bir sıralama örnek kodu var.
Bence onu bulup bir inceleyin. Sanırım tools/demo dizini altında:
Burada bir bar listesi karıştırılıyor sonra sıralama algoritmaları ile sıralanıyor. Hem hız yönünden hem de adım adım sıralamayı görselleştiriyor.
Böylece bir algoritma seçip sizin koda uyarlasınız iyi olur.
Zaten kodunuzda bir şey yok.
bir fonksiyonunuz var o da facia.
Onu çıkarıp başka bir fonksiyon koyunca zaten kod hem okunaklı hem de basit hale geliyor.
Bu nedenle başta zaten kendi kodumu ekledim.
Yine hatırlatıp şu editi kapatayım. Tabi ki bir sıralama algoritmasını kendiniz yazmak isteyebilirsiniz, ama bunu daha iyi yapan optimize bir hazır fonksiyon varken yapacaksanız, sizin daha optimize bir tanesini yazabilecek kadar iyi olduğunuza güvenmeniz gerekir.
Bunca yıldır bende o güven yok mesela, onca sıralama algoritması bilirim kodlarım denerim ama bir dilin yerleşik sıralama yeteneği varsa kendi yazdığımdan çok ona güvenirim.
Ya daha iyisini yapacak kadar öğrenin yada bırakın o işi dilin ilgili fonksiyonu yapsın. Her iki yol için de örnek ve öneri verdim. Burada hunharca eleştirmek için eleştirmedim. Size faydası olacağını düşündüğüm deneyimlerimi aktarmaya çalıştım.
Burada zaten benim kadar yazıp açıklamaya çalışan çok da insan bulamazsın, şurasınız değiştir der zırt giderler hemen, ha öyle istiyorsan benlik bir sorun yok, pass geç benim mesajı diğer yorumculardan devam et.
Tekrar kolay gelsin.