Arkadaşlar merhaba. Kodlama bilgim sıfır. Elimde aşağıda paylaştığım gibi bir kod var. Bu kod google colab’ da kullanılıyor. “print” yazan satır da dahil oraya kadar olan kısım ayrı, alttaki kısım ayrı olarak colab’ da “kod” yazan kısma yazılıp, çalıştırılıyor. Bu kodla ilgili bazı eksikler ve düzenlenmesi gereken yerler var. Eğer yardımcı olabilirseniz çok sevinirim, çünkü aciliyeti ve önemi var:
1- Bu kodu başka bir platformda nasıl kullanabilirim ?(Örneğin;onecomplier.com benzeri online kullanım yerleri) çünkü bu haliyle yazınca hata veriyor.
2- Bakın kodda 4 adet küme için çıktı alıyorsunuz. Bu koda aynı anda bunun gibi atıyorum 3 adet 4’lü küme yazıp, aynı anda tek dosyada hepsi için ayrı ayrı çıktı almak istiyorum. Her bir sonuç ayrı ayrı sekmelerde yer alsın. Bunun için kodda düzenleme gerek.
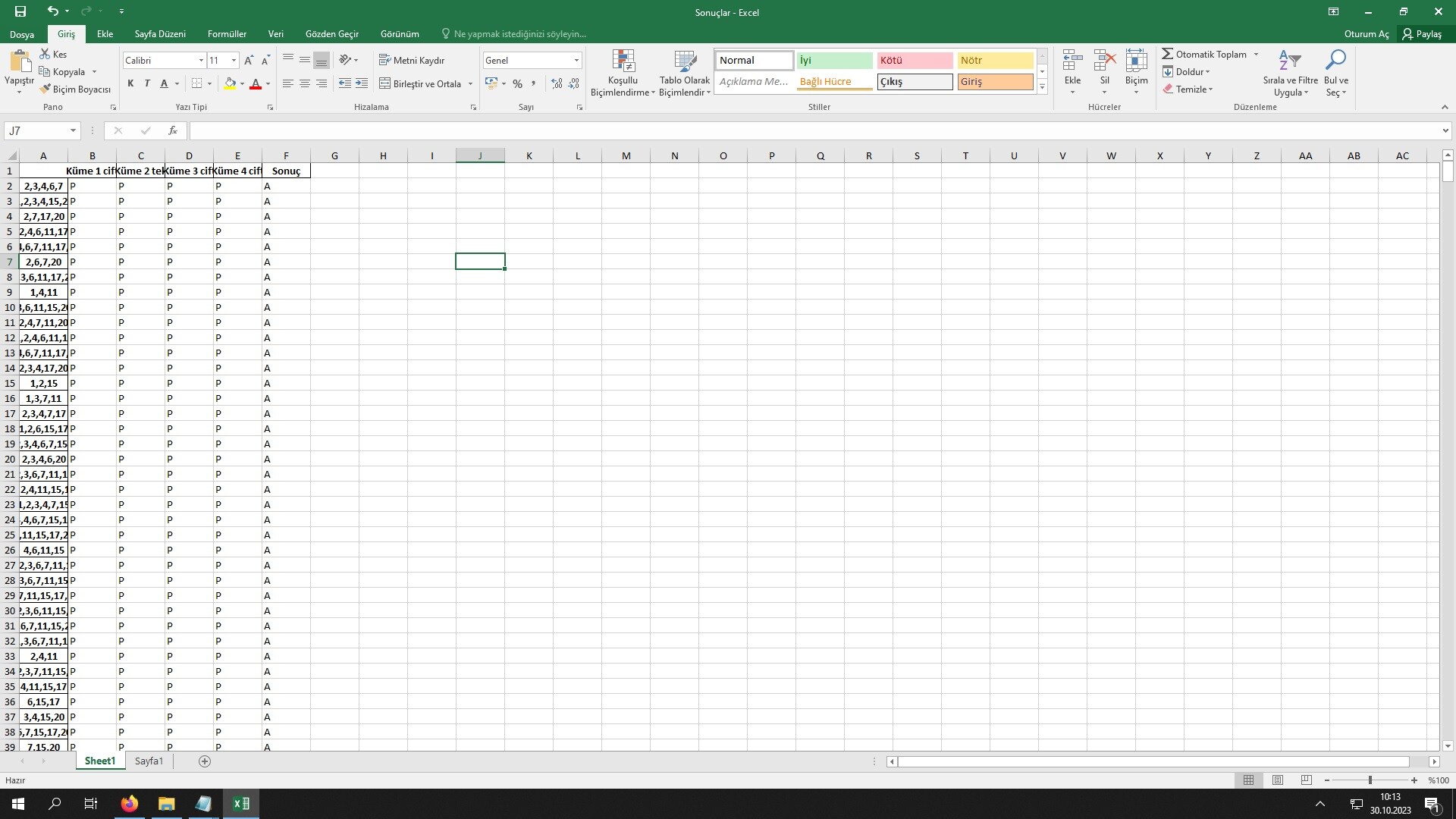
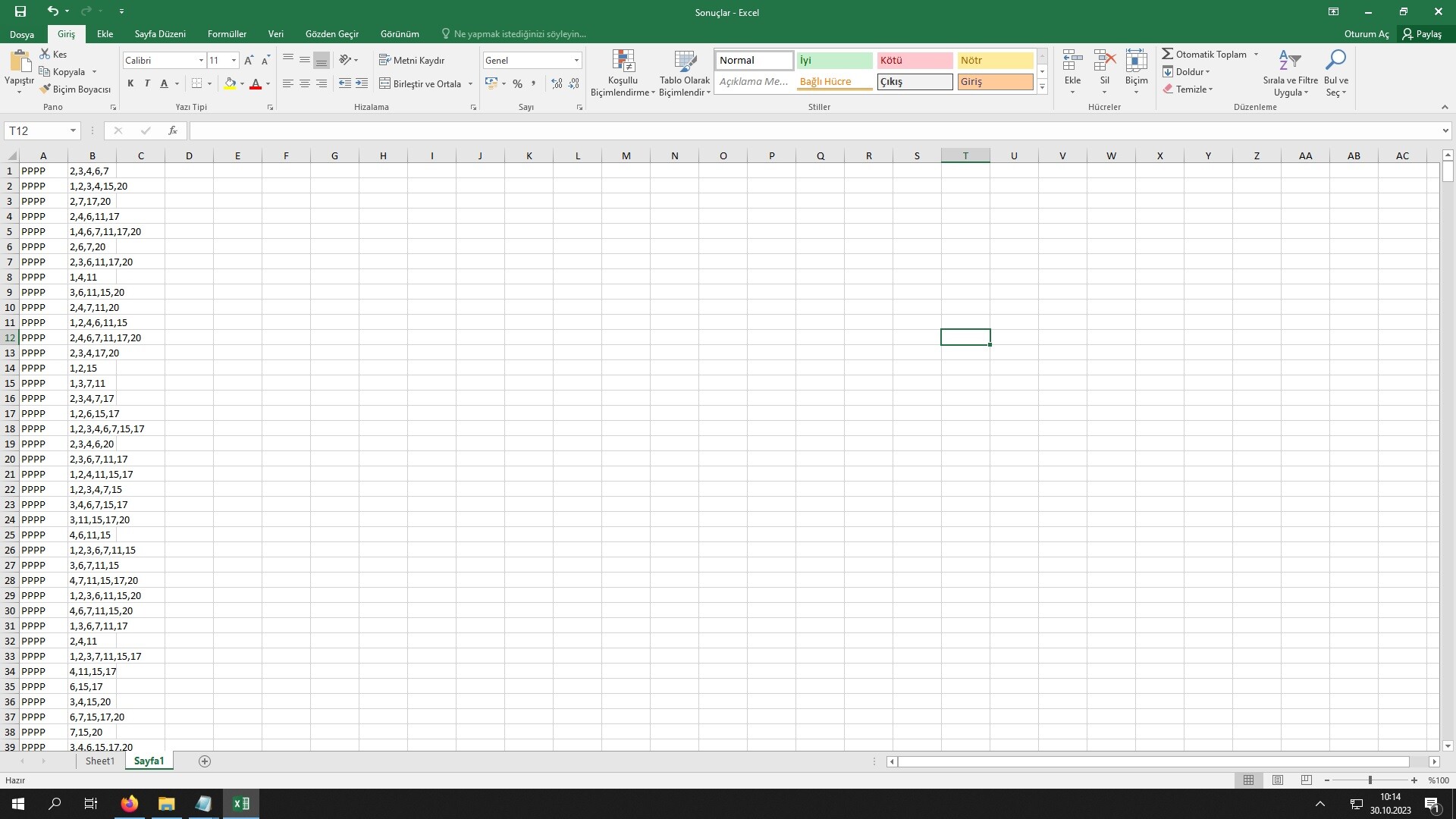
3- Kodun verdiği çıktının ekran görüntüsü 1 nolu resimde görülmekte. Ben bu formatta değişik istiyorum. Bakın P ve N’ ler ayrı ayrı sütunlarda belirtilmiş. benim istediğim format 2 nolu resimdeki gibi: P ve N’ler tek sütunda birleşik, hemen yanındaki sütunda ise değerler var. “PPPP” şeklindeki A sütunundaki değerler “Z’ den A’ ya sırala” şeklinde sıralanmış olmalı. Ben önce 1 nolu resimdeki çıktıdaki P ve N’ leri tek sütunda birleştiriyorum, sonra da “Sırala ve Filtre Uygula” dan “Z’ den A’ ya sırala” ya tıklayarak bir sıralama elde ediyorum. İşte bu manuel işlemi en başta kod otomatik olarak yapsın çıktı alırken.
Yukarıda üç ayrı maddede belirttim meramımı. Eğer yardımcı olabilecek arkadaşlar varsa çok makbule geçer. Herkese iyi haftalar diliyorum.
-- coding: utf-8 --
“”"Algoritma.ipynb
Automatically generated by Colaboratory.
Original file is located at
Google Colab
“”"
from itertools import combinations
import pandas as pd
import numpy as np
from google.colab import files
Veriler------------------------------
Sadece aşağıdaki rakamlar ve çift tek kısımları değişltirilecek.
Sonra yukarıdaki menüde Çalışma Zamanı → Tümünü Çalıştır.
kume_1 = [ [20,7,4,11], “cift”]
kume_2 = [ [1,2,4,15,4], “tek”]
kume_3 = [ [17,3,6,1,2,4], “cift”]
kume_4 = [ [20,7,3], “cift”]
-------------------------------------
tum_kumeler = [kume_1, kume_2, kume_3, kume_4]
kullanilan_sayilar =
for kume in tum_kumeler:
for sayi in kume[0]:
if sayi not in kullanilan_sayilar:
kullanilan_sayilar.append(sayi)
kullanilan_sayilar.sort()
print("Kullanılan Sayılar: ",kullanilan_sayilar )
def sub_lists (l):
comb =
for i in range(len(l)+1):
comb += [list(j) for j in combinations(l, i)]
return comb[1:]
def conver_str(l):
result_list =
for x in l:
string = “”
for y in x:
string +=str(y) + ‘,’
result_list.append(string[:-1])
return (result_list)
df = pd.DataFrame(columns = ["Küme 1 " + kume_1[1], "Küme 2 " + kume_2[1], "Küme 3 " + kume_3[1], "Küme 4 " + kume_4[1]],
index = conver_str(sub_lists(kullanilan_sayilar)))
df.head(5)
for x in range(len(df.index)):
for y in range(len(df.columns)):
sum = 0
for z in df.index.split(‘,’):
sum += tum_kumeler[y][0].count(int(z))
df.iloc[x,y] = sum
df.head(5)
df_result = pd.DataFrame(index = df.index,
columns = list(df.columns) + [“Sonuç”])
for row in df.index:
for col in df.columns:
if (df.loc[row, col] % 2 == 0 and col[-1] == “t”) or (df.loc[row, col] % 2 != 0 and col[-1] == “k”):
df_result.loc[row,col] = ‘P’
else:
df_result.loc[row,col] = ‘N’
row_result = list(df_result.loc[row])
if row_result.count('P') == 4:
df_result.loc[row, "Sonuç"] = 'A'
elif (row_result[2] == 'N' or row_result[3] == 'N'):
df_result.loc[row, "Sonuç"] = 'B'
elif (row_result[0] == 'P' and row_result[1] == 'P'):
df_result.loc[row, "Sonuç"] = 'C'
elif (row_result[0] == 'N' or row_result[1] == 'N'):
df_result.loc[row, "Sonuç"] = 'D'
elif (row_result[0] == 'P' or row_result[1] == 'P'):
df_result.loc[row, "Sonuç"] = 'E'
elif row_result.count('B') == 4:
df_result.loc[row, "Sonuç"] = 'F'
df_result.sort_values(by=[‘Sonuç’]).head()
df_result.sort_values(by=[‘Sonuç’]).to_excel(“Sonuçlar.xlsx”)
files.download(‘Sonuçlar.xlsx’)