# -*- coding: utf-8 -*-
# 📦 GEREKLİ KÜTÜPHANELER
# Uninstalling all relevant libraries to ensure a clean state
!pip uninstall -y numpy mediapipe opencv-python tensorflow pandas
# Installing all necessary libraries together
# This helps pip resolve compatible versions
!pip install numpy mediapipe opencv-python tensorflow pandas
import kagglehub
# Download latest version
path = kagglehub.dataset_download("nandwalritik/yoga-pose-videos-dataset")
print("Path to dataset files:", path)
import os
import shutil
import re
def group_videos_by_pose(source_folder, destination_folder):
if not os.path.exists(source_folder):
print(f"Hata: Kaynak klasör '{source_folder}' bulunamadı.")
return
# Hedef klasörü oluştur (varsa geç)
if not os.path.exists(destination_folder):
os.makedirs(destination_folder)
print(f"Hedef klasör oluşturuldu: {destination_folder}")
print(f"'{source_folder}' içindeki videolar pozlara göre gruplanıyor...")
# Kaynak klasördeki tüm dosyaları listele
for item_name in os.listdir(source_folder):
item_path = os.path.join(source_folder, item_name)
# Sadece video dosyalarını işle
if os.path.isfile(item_path) and item_name.lower().endswith(".mp4"):
# Dosya adından poz adını çıkar
# İsim ve poz adının alt çizgi ile ayrıldığını varsayıyoruz.
# Bu regex, dosya adındaki son alt çizgiden sonraki kısmı (uzantı hariç) alır.
match = re.search(r'_([^_]+)\.mp4$', item_name, re.IGNORECASE)
if match:
pose_name = match.group(1)
# Poz adını kullanarak hedef alt klasör yolunu oluştur
destination_pose_folder = os.path.join(destination_folder, pose_name)
# Hedef alt klasörü oluştur (varsa geç)
if not os.path.exists(destination_pose_folder):
os.makedirs(destination_pose_folder)
print(f"Poz klasörü oluşturuldu/var: {pose_name}/")
# Dosyayı hedef poz klasörüne kopyala
destination_file_path = os.path.join(destination_pose_folder, item_name)
try:
shutil.copy2(item_path, destination_file_path) # Metadataları da kopyalar
print(f" '{item_name}' -> '{pose_name}/'")
except Exception as e:
print(f" '{item_name}' dosyası kopyalanırken bir hata oluştu: {e}")
else:
print(f" '{item_name}' dosyasından poz adı çıkarılamadı, işlenmedi.")
elif os.path.isdir(item_path):
print(f" '{item_name}/' bir klasör, atlanıyor.")
else:
print(f" '{item_name}' bir video dosyası değil veya uzantısı farklı, atlanıyor.")
print("Pozlara göre gruplama işlemi tamamlandı.")
# Kullanım örneği:
# Kaynak klasör, zip'ten çıkarılan 'Yoga_Vid_Collected' klasörünün yolu olacaktır.
# Bu yol, zip'i nereye çıkardığınıza bağlı olacaktır.
# Not defterinizdeki 'exracted_video_dataset' değişkeni bu yapıya uygun olabilir.
# Tam yolu doğrulamanız gerekebilir. Örnek: /content/exracted_dataset/Yoga_Vid_Collected
kaynak_klasor_yolu = os.path.join(path, "Yoga_Vid_Collected") # exracted_video_dataset değişkeninizin içeriğini kontrol edin
hedef_klasor_yolu = "/content/grouped_yoga_videos" # Yeni oluşturulacak hedef klasör yolu
group_videos_by_pose(kaynak_klasor_yolu, hedef_klasor_yolu)
# Oluşturulan yapıyı görmek için klasör ağacını yazdırabilirsiniz:
# === 0. Kurulumlar ve İçe Aktarmalar ===
import os
import shutil
import zipfile
import csv
import re
import cv2
import numpy as np
#import mediapipe as mp
from google.colab import drive
# === 1. Zip Dosyasını Çıkarma ===
pose_name = "Yoga_Vid_Collected"
video_folder_path = f"/content/drive/MyDrive/dataset2/{pose_name}.zip"
extracted_video_dataset = "/content/grouped_yoga_videos"
extracted_csv_dataset = "/content/extracted_csv_dataset"
drive_hedef_yolu = "MyDrive/Csv_Dataset_Mediapipe"
zip_adı = pose_name
# === 3. MediaPipe ile Keypoint Çıkarımı ===
mp_pose = mp.solutions.pose
pose_model = mp_pose.Pose(static_image_mode=False, min_detection_confidence=0.5)
def extract_mediapipe_keypoints(frame):
image_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = pose_model.process(image_rgb)
if not results.pose_landmarks:
return None
keypoints = []
for lm in results.pose_landmarks.landmark:
keypoints.extend([lm.x, lm.y, lm.visibility])
return keypoints # 33*3 = 99 değer
# === 4. Tek Bir Videoyu CSV'ye Dönüştürme ===
def video_to_csv_mediapipe(video_path, csv_path):
cap = cv2.VideoCapture(video_path)
frame_index = 0
fps = cap.get(cv2.CAP_PROP_FPS)
with open(csv_path, mode="w", newline="", encoding="utf-8") as csv_file:
fieldnames = ["timestamp_sec"] + [f"{coord}{i}" for i in range(1, 34) for coord in ['x', 'y', 'v']]
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
while True:
ret, frame = cap.read()
if not ret:
break
timestamp = frame_index / fps
keypoints = extract_mediapipe_keypoints(frame)
if keypoints is None:
frame_index += 1
continue
row = {"timestamp_sec": round(timestamp, 2)}
for i, val in enumerate(keypoints):
row[fieldnames[i + 1]] = val
writer.writerow(row)
frame_index += 1
cap.release()
print(f"✅ CSV oluşturuldu: {csv_path}")
# === 5. Tüm Videoları İşleme ===
def is_video_file(filename):
return filename.lower().endswith(".mp4")
def process_all_videos_mediapipe(root_path):
for folder in os.listdir(root_path):
folder_path = os.path.join(root_path, folder)
if not os.path.isdir(folder_path):
continue
for video_file in os.listdir(folder_path):
if is_video_file(video_file):
video_path = os.path.join(folder_path, video_file)
video_id = os.path.splitext(video_file)[0]
csv_path = os.path.join(folder_path, f"{video_id}.csv")
print(f"📹 İşleniyor: {video_file}")
video_to_csv_mediapipe(video_path, csv_path)
process_all_videos_mediapipe(extracted_video_dataset)
# === 6. CSV Dosyalarını csv/ Alt Klasörüne Taşı ===
def csv_dosyalarini_tasi(kok_klasor):
for yoga_klasoru in os.listdir(kok_klasor):
klasor_yolu = os.path.join(kok_klasor, yoga_klasoru)
if not os.path.isdir(klasor_yolu):
continue
csv_klasoru_yolu = os.path.join(klasor_yolu, "csv")
os.makedirs(csv_klasoru_yolu, exist_ok=True)
for dosya in os.listdir(klasor_yolu):
if dosya.endswith(".csv"):
shutil.move(os.path.join(klasor_yolu, dosya), os.path.join(csv_klasoru_yolu, dosya))
csv_dosyalarini_tasi(extracted_video_dataset)
# === 7. CSV'leri Üst Klasöre Kopyala ===
def csv_dosyalarini_ust_klasore_kopyala(kaynak_ana_klasor, hedef_ana_klasor):
if not os.path.exists(hedef_ana_klasor):
os.makedirs(hedef_ana_klasor)
for pose_klasor_adi in os.listdir(kaynak_ana_klasor):
pose_klasor_yolu = os.path.join(kaynak_ana_klasor, pose_klasor_adi)
csv_alt_klasor = os.path.join(pose_klasor_yolu, "csv")
if os.path.isdir(csv_alt_klasor):
hedef_pose_klasor = os.path.join(hedef_ana_klasor, pose_klasor_adi)
os.makedirs(hedef_pose_klasor, exist_ok=True)
for dosya in os.listdir(csv_alt_klasor):
if dosya.endswith(".csv"):
shutil.copy2(os.path.join(csv_alt_klasor, dosya), os.path.join(hedef_pose_klasor, dosya))
csv_dosyalarini_ust_klasore_kopyala(extracted_video_dataset, extracted_csv_dataset)
# -*- coding: utf-8 -*-
"""TezWoA01_ExtractCsv_Mediapipe.ipynb"""
# === 8. ZIP ve Google Drive'a Kaydet ===
def klasoru_zipla_ve_drivea_kaydet(klasor_yolu, zip_dosya_adi, drive_hedef_yolu):
zip_path = f"/content/{zip_dosya_adi}.zip"
shutil.make_archive(zip_path.replace(".zip", ""), 'zip', klasor_yolu)
drive.mount('/content/drive')
drive_hedef_klasor_yolu = os.path.join("/content/drive", drive_hedef_yolu)
os.makedirs(drive_hedef_klasor_yolu, exist_ok=True)
shutil.move(zip_path, os.path.join(drive_hedef_klasor_yolu, os.path.basename(zip_path)))
print("✅ ZIP dosyası Drive'a yüklendi.")
klasoru_zipla_ve_drivea_kaydet(extracted_csv_dataset, zip_adı, drive_hedef_yolu)
import zipfile
import os
zip_file_name="Yoga_Vid_Collected"
extract_folder = f"/content/unzipped-dataset-csv-{zip_file_name}" # Çıkarılacak klasör
dataset_zip_path=f"/content/drive/MyDrive/Csv_Dataset_Mediapipe/{zip_file_name}.zip"
# Check if the file exists
if not os.path.exists(dataset_zip_path):
raise FileNotFoundError(f"The file {dataset_zip_path} does not exist. Please check the path and try again.")
# Check if the file is a valid zip file
try:
with zipfile.ZipFile(dataset_zip_path, 'r') as zip_ref:
# If it's a valid zip file, extract it
zip_ref.extractall(extract_folder)
print("Çıkarma işlemi tamamlandı.")
except zipfile.BadZipFile:
# If it's not a valid zip file, raise an error
raise zipfile.BadZipFile(f"The file {dataset_zip_path} is not a valid zip file. It may be corrupted or have a different format.")
# -*- coding: utf-8 -*-
"""TezWoA02_TrainModel_MediaPipe.ipynb"""
# === 1. Kütüphaneler ve Yardımcı Fonksiyonlar ===
import os
import zipfile
from shutil import rmtree
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
extract_csv_dataset = "/content/dataset"
# === 3. Dataset Hazırlığı ===
def load_sequences_mediapipe(base_path, test_size=0.40, window_size=50, step=10):
person_data = {}
label_map = {}
current_label = 0
for pose_folder in sorted(os.listdir(base_path)):
pose_path = os.path.join(base_path, pose_folder)
if not os.path.isdir(pose_path): continue
if pose_folder not in label_map:
label_map[pose_folder] = current_label
current_label += 1
for file in os.listdir(pose_path):
if not file.endswith(".csv") or file.endswith("_genelEvre.csv"):
continue
person_name = file.split("_")[0]
csv_path = os.path.join(pose_path, file)
person_data.setdefault(person_name, []).append((pose_folder, csv_path))
train_people, test_people = train_test_split(sorted(person_data), test_size=test_size, random_state=42)
def augment_sequence(window, noise_std=0.005, time_shift_max=3):
# Gaussian noise
noise = np.random.normal(0, noise_std, window.shape)
window_noisy = window + noise
# Time shifting
shift = np.random.randint(-time_shift_max, time_shift_max+1)
if shift > 0:
window_shifted = np.pad(window_noisy, ((shift, 0), (0, 0)), mode='edge')[:-shift]
elif shift < 0:
window_shifted = np.pad(window_noisy, ((0, -shift), (0, 0)), mode='edge')[-shift:]
else:
window_shifted = window_noisy
return window_shifted.astype(np.float32)
def spatial_scaling(window, scale_range=(0.9, 1.1)):
scale = np.random.uniform(*scale_range)
return (window * scale).astype(np.float32)
def mirror_pose(window):
# x-koordinatlarını 1 - x ile aynala (normalize edilmiş kabul edilir)
flipped = window.copy()
flipped[:, ::2] = 1.0 - flipped[:, ::2]
return flipped.astype(np.float32)
def create_dataset(people, augment=False):
X, y = [], []
coord_columns = [f"{axis}{i}" for i in range(1, 34) for axis in ['x', 'y']]
for person in people:
for pose_label, csv_file in person_data[person]:
df = pd.read_csv(csv_file)
if not set(coord_columns).issubset(df.columns): continue
features = df[coord_columns].to_numpy(dtype=np.float32)
if np.isnan(features).any() or np.isinf(features).any(): continue
for start in range(0, features.shape[0] - window_size + 1, step):
window = features[start:start+window_size]
if window.shape[0] == window_size:
X.append(window)
y.append(label_map[pose_label])
"""X.append(spatial_scaling(window))
y.append(label_map[pose_label])"""
X.append(mirror_pose(window))
y.append(label_map[pose_label])
if augment: # Artırımlı örnek ekleniyor
aug_window = augment_sequence(window)
X.append(aug_window)
y.append(label_map[pose_label])
return np.array(X), np.array(y)
X_train, y_train = create_dataset(train_people, augment=True)
X_test, y_test = create_dataset(test_people, augment=False)
return X_train, X_test, y_train, y_test, label_map
X_train, X_test, y_train, y_test, label_map = load_sequences_mediapipe(extract_csv_dataset)
print("Eğitim verisi:", X_train.shape)
print("Test verisi:", X_test.shape)
# === 4. PyTorch Dataset ve DataLoader ===
import torch
from torch.utils.data import Dataset, DataLoader
class PoseSequenceDataset(torch.utils.data.Dataset):
def __init__(self, X, y):
self.X = torch.tensor(X, dtype=torch.float32)
self.y = torch.tensor(y, dtype=torch.long)
def __len__(self): return len(self.X)
def __getitem__(self, idx): return self.X[idx], self.y[idx]
train_dataset = PoseSequenceDataset(X_train, y_train)
test_dataset = PoseSequenceDataset(X_test, y_test)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# === 5. LSTM Modeli ===
import torch.nn as nn
import torch
import torch.nn as nn
class CNNPerFrame(nn.Module):
def __init__(self, input_channels=66, cnn_out_channels=32, kernel_size=3, dropout=0.2):
super(CNNPerFrame, self).__init__()
self.conv1 = nn.Conv1d(in_channels=2, out_channels=cnn_out_channels, kernel_size=kernel_size, padding=kernel_size//2)
self.relu = nn.ReLU()
self.bn = nn.BatchNorm1d(cnn_out_channels)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = x.view(-1, 33, 2).permute(0, 2, 1) # (B, 2, 33)
x = self.conv1(x) # (B, cnn_out, 33)
x = self.relu(x)
x = self.bn(x)
x = self.dropout(x)
return x.view(x.size(0), -1) # (B, cnn_out * 33)
class CNNLSTM_YogaModel(nn.Module):
def __init__(self, frame_cnn_out=32*33, lstm_hidden_size=128, num_classes=6):
super().__init__()
self.cnn_per_frame = CNNPerFrame()
self.lstm = nn.LSTM(input_size=frame_cnn_out,
hidden_size=lstm_hidden_size,
num_layers=1,
batch_first=True,
bidirectional=True)
self.fc = nn.Linear(lstm_hidden_size * 2, num_classes)
def forward(self, x):
B, T, C = x.size() # (B, 50, 66)
x = x.view(B * T, C) # (B*T, 66)
cnn_features = self.cnn_per_frame(x) # (B*T, F)
cnn_features = cnn_features.view(B, T, -1) # (B, T, F)
lstm_out, _ = self.lstm(cnn_features) # (B, T, 2*H)
out = self.fc(lstm_out[:, -1, :]) # (B, num_classes)
return out
# === 6. Eğitim Hazırlığı ===
from sklearn.utils.class_weight import compute_class_weight
from sklearn.metrics import accuracy_score, f1_score
import torch.nn.functional as F
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class_weights = compute_class_weight(class_weight='balanced', classes=np.unique(y_train), y=y_train)
class_weights_tensor = torch.tensor(class_weights, dtype=torch.float32).to(device)
#model = PoseLSTMClassifier(input_size=66, num_classes=len(label_map)).to(device)
model = CNNLSTM_YogaModel(
frame_cnn_out=32*33, # CNN çıkış boyutu (cnn_out_channels * keypoint sayısı)
lstm_hidden_size=128, # LSTM gizli katman boyutu
num_classes=6 # Yoga pozu sayısı
).to(device)
criterion = nn.CrossEntropyLoss(weight=class_weights_tensor)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# === 7. Eğitim Döngüsü ===
num_epochs = 75
patience = 10
best_val_loss = float('inf')
epochs_no_improve = 0
early_stop = False
train_losses, val_losses = [], []
train_accuracies, val_accuracies, val_f1_scores = [], [], []
for epoch in range(num_epochs):
if early_stop: break
model.train()
train_loss = 0
train_preds, train_labels = [], []
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
preds = torch.argmax(outputs, dim=1)
train_preds.extend(preds.cpu().numpy())
train_labels.extend(labels.cpu().numpy())
train_acc = accuracy_score(train_labels, train_preds)
# Doğrulama
model.eval()
val_loss = 0
val_preds, val_labels = [], []
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
preds = torch.argmax(outputs, dim=1)
val_preds.extend(preds.cpu().numpy())
val_labels.extend(labels.cpu().numpy())
val_acc = accuracy_score(val_labels, val_preds)
val_f1 = f1_score(val_labels, val_preds, average='weighted')
# Kayıt
train_losses.append(train_loss / len(train_loader))
val_losses.append(val_loss / len(test_loader))
train_accuracies.append(train_acc)
val_accuracies.append(val_acc)
val_f1_scores.append(val_f1)
if val_loss < best_val_loss:
best_val_loss = val_loss
epochs_no_improve = 0
torch.save(model.state_dict(), "best_model.pt")
else:
epochs_no_improve += 1
if epochs_no_improve >= patience:
early_stop = True
print(f"Epoch {epoch+1}/{num_epochs} - loss: {train_losses[-1]:.4f} - acc: {train_acc:.4f} - val_loss: {val_losses[-1]:.4f} - val_acc: {val_acc:.4f} - val_f1: {val_f1:.4f}")
# === 8. Sonuç ve Model Kaydı ===
from sklearn.metrics import classification_report
model.eval()
all_preds, all_labels = [], []
with torch.no_grad():
for inputs, labels in test_loader:
inputs = inputs.to(device)
outputs = model(inputs)
preds = torch.argmax(outputs, dim=1).cpu().numpy()
all_preds.extend(preds)
all_labels.extend(labels.numpy())
print("Test Doğruluğu:", accuracy_score(all_labels, all_preds))
print(classification_report(all_labels, all_preds, target_names=label_map.keys()))
# Model kaydı
torch.save(model.state_dict(), "pose_lstm_model.pt")
print("✅ Model başarıyla kaydedildi.")
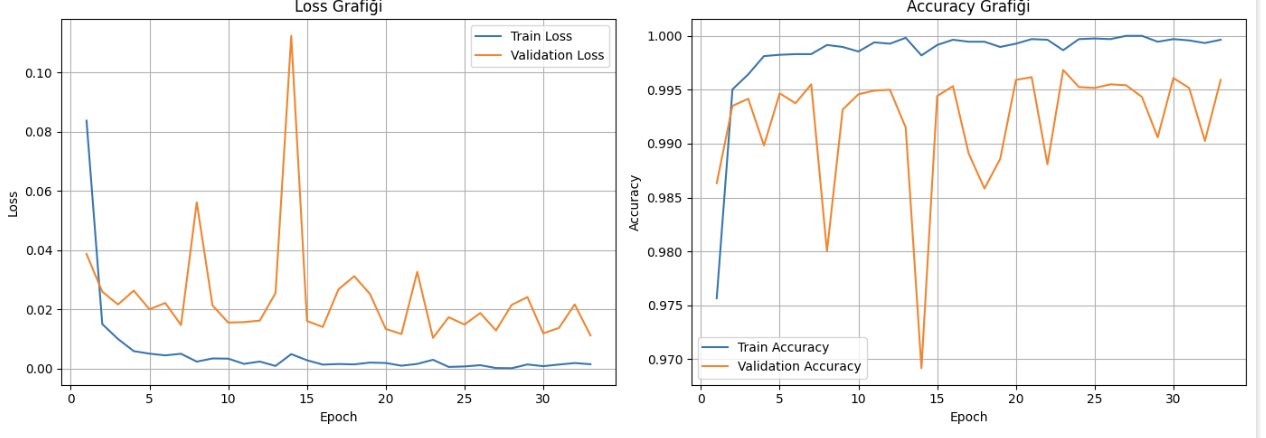
import matplotlib.pyplot as plt
epochs = range(1, len(train_losses) + 1)
plt.figure(figsize=(14, 5))
# --- LOSS GRAFİĞİ ---
plt.subplot(1, 2, 1)
plt.plot(epochs, train_losses, label="Train Loss")
plt.plot(epochs, val_losses, label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Loss Grafiği")
plt.legend()
plt.grid(True)
# --- ACCURACY GRAFİĞİ ---
plt.subplot(1, 2, 2)
plt.plot(epochs, train_accuracies, label="Train Accuracy")
plt.plot(epochs, val_accuracies, label="Validation Accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.title("Accuracy Grafiği")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
import matplotlib.pyplot as plt
epochs = range(1, len(train_losses) + 1)
plt.figure(figsize=(14, 5))
# --- LOSS GRAFİĞİ ---
plt.subplot(1, 2, 1)
plt.plot(epochs, train_losses, label="Train Loss")
plt.plot(epochs, val_losses, label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Loss Grafiği")
plt.legend()
plt.grid(True)
plt.xlim(1, 10)
plt.ylim(1, 10) # LOSS için y aralığı
# --- ACCURACY GRAFİĞİ ---
plt.subplot(1, 2, 2)
plt.plot(epochs, train_accuracies, label="Train Accuracy")
plt.plot(epochs, val_accuracies, label="Validation Accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.title("Accuracy Grafiği")
plt.legend()
plt.grid(True)
plt.xlim(0, 30)
plt.ylim(0, 1) # ACCURACY için y aralığı
plt.tight_layout()
plt.show()
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
# Confusion matrix hesapla
cm = confusion_matrix(all_labels, all_preds)
# Etiket isimleri
class_names = list(label_map.keys())
# Görselleştir
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=class_names)
fig, ax = plt.subplots(figsize=(10, 10))
disp.plot(ax=ax, cmap=plt.cm.Blues, xticks_rotation=45)
plt.title("Confusion Matrix")
plt.grid(False)
plt.show()
burada başından sonuna kadar kullandığım kodlarım var mediapipe ile keypoint verilerini csv dosyalarına kaydedip bu dosyalar ile modelimi eğitmeye çalışıyorum
Test Doğruluğu: 0.9959153051017006
precision recall f1-score support
Bhujangasana 1.00 0.99 1.00 2108
Padmasana 1.00 1.00 1.00 2074
Shavasana 0.99 1.00 1.00 1846
Tadasana 0.99 0.99 0.99 2000
Trikonasana 1.00 1.00 1.00 1866
Vrikshasana 0.99 0.99 0.99 2102
accuracy 1.00 11996
macro avg 1.00 1.00 1.00 11996
weighted avg 1.00 1.00 1.00 11996
ilgili etiketlerimin doğruluk oranları bu şekilde çıkıyor bu değerler normal mi ya da ner hata yapıyorum çözemedim