Sizlerle yaptığım bir projeyi paylaşıp ayrıca bazı sorular sormak istiyorum. Ben Google Summer of Code kapsamında ROS middleware’lerinin benchmark’larını yapmak için bir tool oluşturdum. Bu toplulukta ROS’un ne olduğunu bilmeyen çok fazla insan var. Burada middleware ile kasteddiğim şey, kafka, mqtt gibi low level data iletim araçlarını kullanan ROS middleware’leri. Bu middleware’ler sensor verilerinin iletimi için kritik önem arz ediyor. Ben de bunların performanslarını ölçmeye çalıştım. Ayrıntılı bir postu şu linkte bulabilirsiniz: [Google Summer of Code 2024] Zenoh Support & Benchmarking - MoveIt - ROS Discourse
Neyi benchmark ettiginizi bulamadim. Kolayca erisilebilir bir sonuclar sayfasi da bulamadim. ROS olduguna gore response suresi gibi bir sey oldugunu tahmin ediyorum?
Benchmarking metodolojisini bir giris yazisina koymak da iyi olabilir. “Kendimizi middleware olarak tanitip, benchmark edilecek middleware’e mesaj atip cevabin gelis suresini tick cinsinden olcuyoruz” veya “ROS benchmark kutuphanesinin X tanimina gore Y benchmark sinifi yaratip calistiriyoruz” gibi.
Genel olarak: Olculmek istenen senaryoya mumkun oldugunca yakin olmak. Mesela gorsel isler birbirine zamanda yakinlilik ve benzerlik gosterebilir; her saniye alinan goruntuler birbirine yakin olacaktir ve rastgele verilen gorsel girdilerden cok farkli olabilir. Gercek hardware icin tasarlanmis bir sey mesajla cevap arasinda belirli bir gecikme bekleyip ona gore optimize edilmis olabilir; simulasyonda calistiginda daha dusuk performans sergileyebilir. (Gerci kendi testleri/olcumleri de simulasyonda yapilacagi icin bunun olma ihtimali dusuk, ama goz onunde bulundurmak lazim.)
Neyin, nasil olculdugunu belirtmeden bir sey soylemek zor, fakat projeyi ozgur yazilim olarak uretip tek bir sirketin bir urunune baglamak yazik.
Genel olarak CI araclarinin diger container calistiran/virtual makinelerden farki yok, fakat ozellikle bedava olan cloud hizmetleri uzerinde bilgi ve kontrol sahibi olunamiyor. (Mesela Microsoft GitHub Actions’da Android NDK yuklu olmayan bir runner elde etmek mumkun mu? Veya tek bir karakterlik degisiklik icin commit yap–github’a push et–runner’in calistirmasini bekle–runner faturasini kontrol et–loglara bak zincirinden daha kisa bir sey kullanmak mumkun mu?)
Istenilen her makinede, bedavaya calistirilabilen imajlar kullanildigi surece hangi platformda veya urunde calistirildiklari onemli degil. Hatta degisik ortamlarda calistirip sonuclarinin ayni veya orantili olup olmadiklarina bakabilirsiniz.
Sicakliga bagli olarak yapilan isler var. Belirli bir sicakligin uzerinde CPU saat hizi dusurulebiliyor mesela. Boyle bir sey CPU hizini dogrudan, dogru orantili olarak etkiler.
Bu, ROS’a veya “benchmark” kutuphanesine ozel bir soru olsa gerek.
Sorduğun sorunun robotics alanında önemli bir konuya temas ettiğine inanıyorum. ROS (Robot Operating System) hakkında bilgim olsaydı seve seve yardımcı olurdum, fakat maalesef bu konuda deneyimim yok.
Senin de belirttiğin gibi, forumda ROS ve robot teknolojileriyle ilgilenen insan sayısı sınırlı. Bu nedenle, önce @aib’in yardımcı olabileceğini düşündüm; aramızdaki en deneyimli insanlardan biri olarak onun sana tavsiye verebileceğine inanıyorum.
Teknik bir yardım sağlayamasam da pratik bir önerim var: Aynı soruyu ROS ile ilgili teknik soruların sorulduğu daha geniş kitlelere sahip forumlarda sorman faydalı olabilir. Aşağıda sana yardımcı olabileceğini düşündüğüm forumları listeledim. (Her ne kadar, robotics ile ilgili senin daha fazla forum tavsiyesi verebileceğini varsaysam da…)
Öncelikle iyi dilekleriniz için sağ olun. Konunun spesifik bir konu olduğunu biliyorum. O yüzden her soruma cevap vermemenizi tabi ki de anlayışla karşılamalıyım.
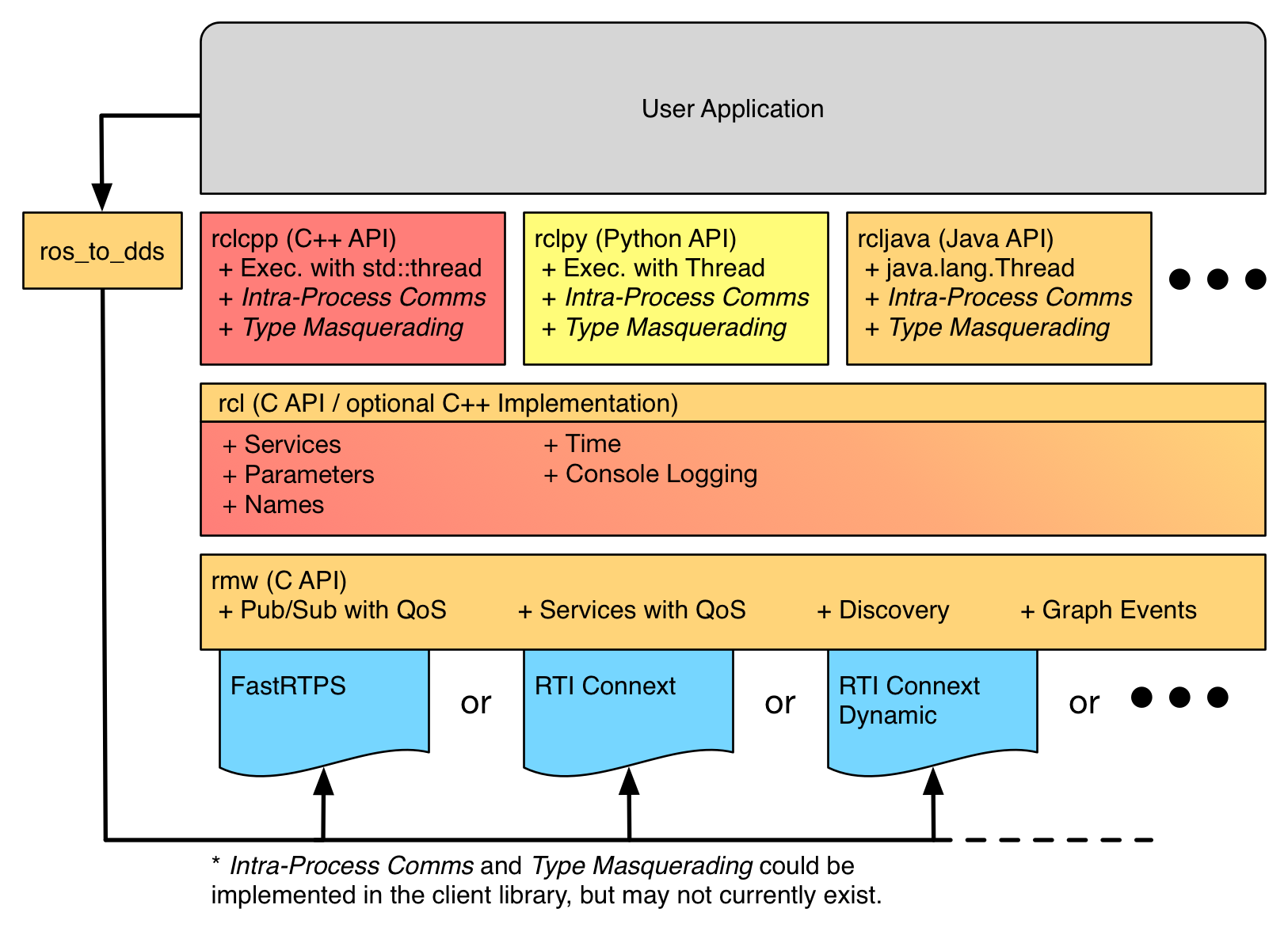
Aslında message latency ölçüyorum. Yani ben mesela Singapur’daki bilgisayarımdan byte array yolladım, Fransa’daki adam bu veriyi kaç saniye sonra alıyor gibi soruların cevabını arıyorum yaptığım benchmark ile. ROS, altyapı olarak DDS, Zenoh gibi protokoller kullanıyor. Daha iyi anlaşılması için hemen aşağıya bir resim ekledim.
Buradan bir soru sormak istiyorum. Mesela ben bir middleware’in motion planning algoritmaları üzerine etkisini merak ediyorum ve bu motion planning algoritması random planlar üretip en optimal planı seçiyor. Ben bu senaryoda senaryonun deterministiğini nasıl artırabilirim veya sonuçları nasıl güvenilir yapabilirim? Mesela deneme sayısını artırmak bir çözüm ve bunu toolumda kullandım.
Google micro benchmark tool kullanıyorum. Süre bazlı ölçüm yapıyorum şimdilik. İleride hafıza kullanımıni da ölçmeyi hedefleyebilirim. Bu sorunu iyi cevaplayamadigim için üzgünüm.
Bir şeyi anlayamadım. fakat projeyi ozgur yazilim olarak uretip tek bir sirketin bir urunune baglamak yazik ile kastettiğinizi çok iyi anlayamadım. Merak ettiğim için sormak istedim. Aslında CI entegrasyonu temel amaç değildi ama benchmark süreleri 1-2 saati buluyor. Ondan sordum bu soruyu. Bir de benchmark güvenilirliğini artırmam için TCP ve UDP’nin kernel konfigurasyonlarındaki memory limitini artırmam gerekiyor ve bunu CI’da yapamıyorum.
Teşekkür ederim, bu benim için faydalı bir geri dönüştü. Gerçek robot senaryoları için benchmark yapınca bilgisayarım ısınıyordu.(Bir sürü data akışı var, kamera verisi, 3d poincloud verisi vs.)
taskset aslında linux man sayfasında var. Yani ROS özelinde bir konu değil aslında. Anladığım kadarıyla bir processin çalışacağı core u secmemizi sağlıyor. Benchmark güvenilirliğini artırdığı için kullanmayı tavsiye ediyorlar. Benim benchmarkını yaptığım senaryolar, birden fazla thread içerebiliyor.
@dildeolupbiten hocam iyi dilekleriniz için sağ olun. Ben bu soruyu zaten belirttiğiniz şartların bilincinde olarak sordum. Bu forumda yıllardır bulunuyorum. Forum tavsiyesi için teşekkür ederim. Ama ben zaten https://discourse.ros.org/ da post paylaştim Bu gönderinin ilk postumda bu paylaşımı görebilirsiniz. Diğer forumlara ise bakacağım. Eğer elle tutulur sonuçlar bulursam burada da paylaşmayı planlıyorum.
Burada DDS, Zenoh yok gibi?
Ama zaten hangi tek sey linklense yetmeyecek. Ogrenmek isteyen kisinin basit bir “ROS nedir, ROS’a giris” yazisi okumasi lazim. Biraz karmasik malesef, veya “ortak bir protokol stack’i uzerinde calisan distributed kernel” gibi basit ozetleyen bir kaynak bulamadim.
Yapilacak cok bir sey yok malesef.
Iterasyon sayisini arttirmak cok kisa sureli degisiklikleri (“spike”) etkisiz hale getirir.
Denenen degisik kod parcalarini A/B/A/B seklinde bolmek de kisa/orta vadeli degisikliklerin sonucu bir tarafa dogru kaydirmasina engel olur. (Ama yine her seferinde coklu iterasyonlu calistirmak lazim; her isin ilk calismasi soguk cache ile oldugu icin sonraki iterasyonlardan uzun surecektir.) Ax100,000, Bx100,000, Ax100,000, Bx100,000… mesela
Yanda ve arkaplanda calisan seyleri minimuma indirmek lazim.
Baska bir sey gelmiyor aklima… Baskalarinin metodolojilerini okumak lazim?
Cok guzel. Bir tavsiye: Grafiklere baslik veya eksen basligi olarak olculen seyleri de ekleyin. “average latency (ns)” veya “Latency of network stack vs. commit” gibi.
Benchmark “ölçüm” gibi bir sey; neyin olculdugu eklenmeden pek bir sey ifade etmiyor.
Test metodolojisini bir yerlere yazmak da burada sordugunuz sorularin bir kisminin cevabinin otomatik gelmesini saglayabilir. Bir yerlere sey yazmaktan bahsediyorum: "Test kodunu soyle bir bilgisayarda su ozelliklerle compile ettik, kutuphaneleri su script’i kullanarak indirip ayni bilgisayarda soyle compile ettik. Sonra su Dockerfile’i kullanarak container imaji olusturduk.
“Test programi rastgele goruntu senaryolari olusturup su mesajla middleware’e pasliyor, cevap gelene kadar arada gecen duvar zamanini olcuyor.”
Okudugunuz bilimsel makalelerde oldugu gibi, kisacasi.
GitHub Workflow’dan bahsediyorum. Su kod sadece GitHub’da calisabiliyor. Su anda zaten GitHub’a (pages) bagli olmayan pek bir sey yok gibi, ama dikkat edilmezse zamanla kod GitHub’a yazilmis bir kod haline gelebiliyor.
Su an danismanlik verdigim sirketlerin birinde tum testleri calistirmanin bir komutu yok mesela. Binlerce dolarlik canavar makinalardan GitHub’a push edip yavas ve parali calisan runner’lardan bir tanesinin alip calistirmasini bekliyoruz.
Anladim. Terimin adi CPU (veya processor) affinity.
Cok karmasik; anlamasi zor oldugundan degil, yapilan seylerin sonuclarinin ne olacagini onden kestirmesi zor oldugundan.
Oncelikle, calisan tek sey benchmark programi olacagi icin cok bir seyin fark etmemesi lazim. Her thread zaten calismakta oldugu core’a meyilli oldugu icin affinity’si ayarlanmayan bir programin core core gezip cache’siz kalmasi boyle bir akista mumkun degil.
(taskset(1)'in manuel sayfasina simdi baktim, yukarida soylediklerimin cogunu ilk paragrafta soyluyormus.)
Sistemde baska yuk yokken programin affinity’sini ayarlamak sadece yavaslatir gibi geliyor: Maksimum thread sayisindan az core’a verilirse buyuk olcude, yoksa kucuk olcude.
Core’larin esit olmadigi durumlarda buyuk farkliliklar yaratabilir. Ornegin hizli 2 core’a baglanmis program vs yavas 2 core’a baglanmis (veya baglanmamis) program.
Guvenilirligi arttiriyorsa kullanin. Tek core’a indirmek kesinlikle bir takim karmasik interaksiyonlari engelleyecektir. Fakat hakkaten programin single-threaded performansini olcmek istiyor musunuz?
Aslında orada geçen FastRTPS , RTI Connext ve RTI Connext Dynamic ifadeleri, protokol implementasyonları. (Bu arada FastRTPS ifadesi, FastDDS’in önceki adı falan olması lazım). Mesela burada Zenoh u yerleştirebiliriz. Evet malesef ROS(Robot Operating System) 2’nin ne olduğunu anlamak için efor göstermek lazım. Ama belki şöyle özetlemeye çalışabilirim. Öncelikle kendisi adından sanıldığının aksine bir işletim sistemi değil. ROS aslında veri akışlarını yönetmek için yazılmış orta katman bir framework. Mesela bir örnek verelim. Elimizde bir protokol var ve bu protokolde de sadece send_data ve get_data fonksiyonları olsun. Bu send_data ve get_data ile istediğim yere data gönderebilirim. Ama bu fonksiyonlar low level ve robot sistemlerinde kullanılması zahmetli. ROS, bu send_data ve get_data fonksiyonlarını kullanarak bize ortak bir API sağlıyor gibi düşünebiliriz.
Bir örnek daha vermek gerekirse, aşağıdaki iki kod (zenoh altyapısını kullanan), alt seviyede bir datayı bir yerden diğerine aktarmak için kullanılıyor.
CycloneDDS için bir örnek
ROS hepsini bir şemsiye altında topluyor ve sadece bir kodla birden fazla protokolü kullanmamı sağlıyor. CycloneDDS kullanmak istersem sadece export RMW_IMPLEMENTATION=rmw_cyclonedds ve zenoh kullanmak istersem sadece export RMW_IMPLEMENTATION=rmw_zenoh komutları ile ortam değişkenini ayarlamam yeterli oluyor.
Evet burada şöyle bir püf nokta var. Ben benchmarklarımda birden fazla process çalıştırıyorum. En basitinden benchmarklarımdan birinde, client bir process’te, server ayrı bir process’te çalışıyor ve benchmark kodları client tarafında çalışıyor. Yani çalışan tek bir process yok ve çalışan tek şey benchmark programı değil.
Bu da baya iyi bir tavsiye, dikkate alacağım
Bu tavsiyeyi google’ın benchmark kütüphanesinde şu linkte veriyorlar bu tavsiyeyi ve dahası bu tavsiyeleri de genellikle llvm projesinden almışlar gibi görünüyor.
Burayı tam anlayamadım, buradan şöyle bir soru sormuş olayım. Bir process’i tek bir core’a hapsetmekle multithreading’in avantajlarını kaybeder miyim? Veyahut threadlerin tek bir core’daki cacheyi paylaşmak zorunda kalacaklarından dolayı mı sordunuz bu soruyu?
Genellikle multi-CPU (ve NUMA) makinelerden bahsediyorlar. Sistemde birbirinden farkli hizlarda calisan iki core varsa, programin hangisinde calisacagi sonuclari etkiler diyor kisaca.
Benzer sekilde, program bir CPU uzerinden yakindaki hafizaya yazip sonra o datayi hafizaya uzak CPU’dan okumaya kalkarsa, yine yavaslar.
LLVM dokumentasyonun ise, affinity ayarini, diger butun programlari belirli core’lardan uzak tutacak sekilde ayarlamayi tavsiye ediyor. Benchmark’lanan program disinda genel CPU yuku yuksek degilse cok degisiklige yol acacagini sanmiyorum, ama denemek lazim tabi.
Sadece en buyugunu: Birden fazla thread’in paralel olarak (ayni anda) calisabilmesini.
Bu da yavaslatici bir sebep elbet, ama paralellik kaybindan buyuk degil.
Bu arada butun bunlarin CPU-agir yukler icin oldugunu soylemis miydik? Network paketi veya timer bekleyen thread’in nerede schedule edileceginin hic bir onemi yok.