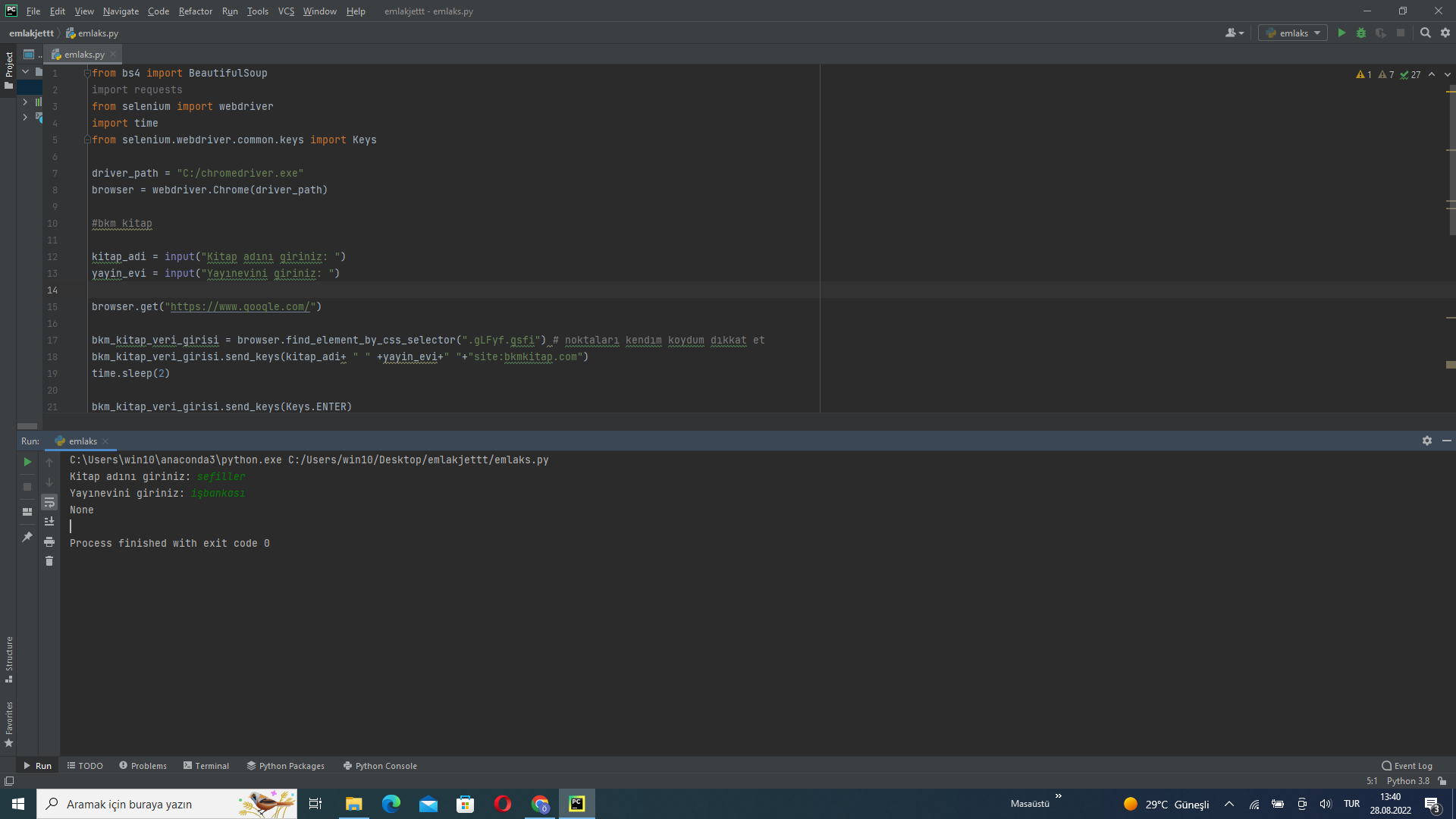
kodu açıklama kısmına gelirsek. seve seve anlatırım tabii.
class BkmKitap:
def __init__(self, book_title):
self.book_title = book_title
init methoduna book_title veriyoruz çünkü sorguyu buna göre atacağız. sanırım yayınevi vs. gibi şeyler için de çalışıyor bu ama emin değilim denemedim.
def get_books(self):
data = {
"cm":"conv",
"f":True,
"d":True,
"q":self.book_title
}
r = requests.get("https://bkm.wawlabs.com/avx_wse", params=data)
return r.text
asıl işimizi bu method yapıyor. sanırım bunu init methodunun içine koymak daha mantıklı bilemiyorum. çünkü response’un içerisindeki farklı bilgilerle farklı işler yapan methodlar yazmak gerektiğinde sürekli get_books methodunu çağırıp sürekli istek atmak mantıklı değil. bir kere istek atıp dönen cevabın içeriğiyle oynamak daha mantıklı göründü şu an. neden öyle yazmışım anlamak güç 
def parse_books(self):
books = self.get_books()
jsonify = json.loads(books)
results = []
for book in jsonify["res"]:
result = {}
result["book_title"] = book["Title_txt_tr"]
result["book_author"] = book["Brand_txt_tr"]
result["book_price"] = book["Price_txt_tr"]
result["book_sale_price"] = book["Sale_Price_txt_tr"]
result["book_publisher"] = book["Publisher"]
result["book_rating"] = book["Rating"]
results.append(result)
return results
bu kısımda da parse ediyorum dönen sonucu. aşağı yukarı ne yaptığımı anlamışsındır zaten.
if __name__ == "__main__":
book_input = input("Kitap adı giriniz: ")
data = BkmKitap(book_input).parse_books()
print("--SORGU SONUCU GELEN KİTAP BİLGİLERİ--")
for i in data:
print(f"Kitap Adı: {i['book_title']}\nKitap Yazarı: {i['book_author']}\nKitap Fiyatı: {i['book_price']}\nKitap İndirimli Fiyatı: {i['book_sale_price']}")
print(f"Yayımcı: {i['book_publisher']}\nKitap Puanı: {i['book_rating']}\n")
burayı da pek anlatmaya gerek yok sanırım.
burada asıl önemli olan api’ı nereden nasıl bulacağın. bunun için developer tools’a giriyorsun (sağ tıklayıp öğeyi denetle dediğin kısım) daha sonra yukarıdaki sekmelerden network kısmına tıklıyorsun (sende ‘ağ’ yazıyor olabilir)
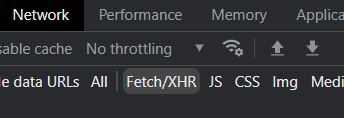
buradan Fetch/XHR seçiyorsun
daha sonra tekrar bkmkitap sitesine gelip bir arama yapıyorsun. arama yaptıktan sonra developer tools’un içerisine bir şeylerin dolduğunu göreceksin. örnek:
daha sonra bunlara tıklıyorum ve içerisinde ne var ona bakıyorum
örneğin wa.wawlabs com’da işime yarar hiçbir şey yok. hepsine tek tek bakıyorum işime yarayacak bilgiyi hangisinde bulabilirim onu araştırıyoruz aslında şu an.
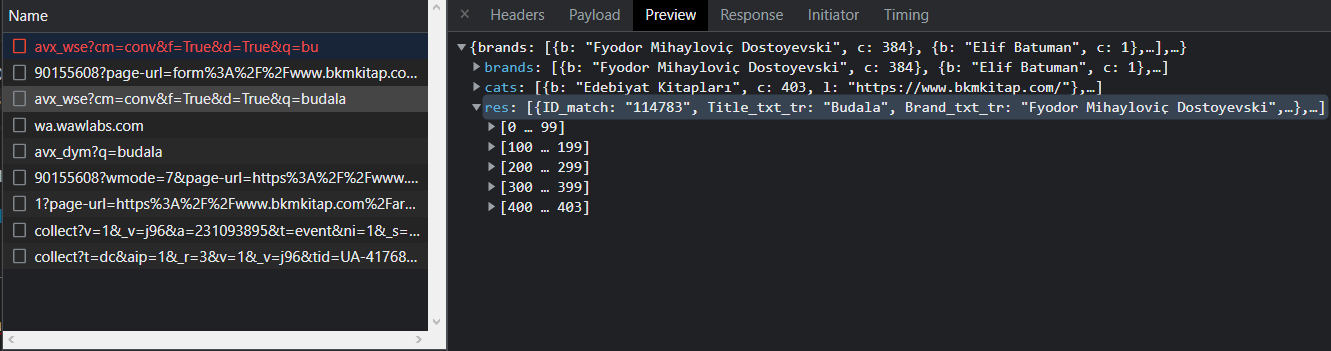
avx_wse ile başlayan response’un içinde işime yarayacak şeyler var gibi görünüyor. brands’de yazarlar catste kategoriler var bana kitaplar lazım. bunlar da res’in içerisinde.
inan ne kadar açık yazdım bilmiyorum. konu hakkında başka bir sorun olursa discord üzerinden de detaylıca anlatmaya çalışırım. ayrıca küçük bir not da düşeyim tüm siteler api ile haberleşmez direkt db’den alıyor olabilir. o durumda developer tools’a işine yarar bir şey düşmeyebilir bilgin olsun.