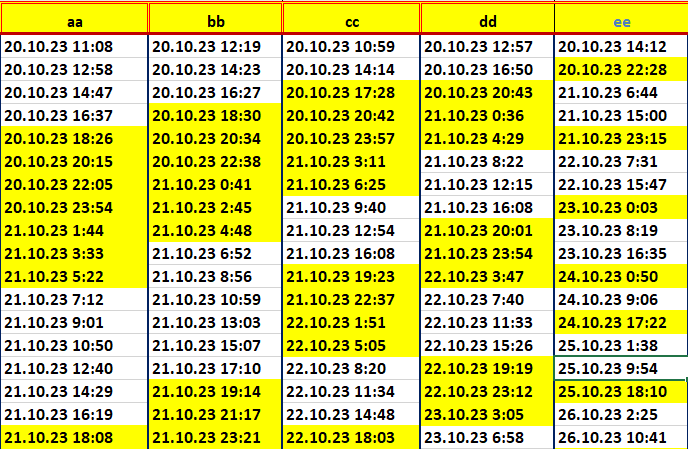
Merhabalar herkese, elimde normalde excel de bazı formüller ile oluşturulmuş önümüzdeki 4 ayın tarihleri var. Tarihler gün ay yıl saat ve dakika olarak tek bir sütunda yer almakta. Saati filtreleyerek 17:00 ile 06:00 arasında olan tarihleri göstermesini istiyorum fakat bu konuda becerikli olamadım. Elimdeki verinin bir kısmını ve yazdığım kodu aşağıya bırakıyorum. Kod bazı tarihleri ne yazık ki atlıyor özellikle ilk dört satırda bulunanları.Bu konu da yardımcı olursanız çok sevinirim.
Veri:
AA;BB;CC;DD
1.11.2023 11:11;1.11.2023 12:47;1.11.2023 11:13;1.11.2023 12:16
1.11.2023 13:01;1.11.2023 14:51;1.11.2023 14:27;1.11.2023 16:09
1.11.2023 14:50;1.11.2023 16:55;1.11.2023 17:42;1.11.2023 20:02
1.11.2023 16:39;1.11.2023 18:58;1.11.2023 20:56;1.11.2023 23:55
1.11.2023 18:29;1.11.2023 21:02;2.11.2023 00:10;2.11.2023 03:48
import pandas as pd
df = pd.read_csv('deneme.csv', sep=';')
cols = df.columns
start = '17:00'
end = '06:00'
secilen_veriler = pd.DataFrame()
for col in cols:
df[col] = pd.to_datetime(df[col], format='%d.%m.%Y %H:%M')
filtre = (df[col].dt.strftime('%H:%M').between(start, '23:59')) | (df[col].dt.strftime('%H:%M').between('00:00', end))
secilen_veriler[col] = df[col][filtre]
secilen_veriler
Bunlar verilerimin bir kısmı sarı ile işaretlediklerim işime yarayan saatler. ‘aa’ sütununda ilk dört satırda istediğim veriler olmadığı için otomatik olarak tüm kolonlarda ilk dört satırı atlıyor. Kısaca sadece ilk kolonda işine yarayan satırları alıyor eğer diğer kolonlarda da bu aralığa denk gelen var ise onlarıda alıyor yok ise boş bırakıyor. Bu konuda bir fikir önerebilirseniz çok sevinirim.
Paylaştığınız veri çerçevesine benzer bir veri çerçevesi oluşturuyorum:
import pandas as pd
from random import randint
from datetime import datetime as dt, timedelta as td
columns = ["a", "b", "c", "d", "e"]
data = [
[dt.now() + td(hours=randint(0, 100)) for i in range(len(columns))]
for row in range(10)
]
df = pd.DataFrame(data, columns=columns)
df.to_csv("data.csv", index=False)
data.csv’nin içine bakalım:
a
b
c
d
e
2023-10-24 10:57:21.899950
2023-10-26 08:57:21.899966
2023-10-26 14:57:21.899969
2023-10-24 22:57:21.899972
2023-10-24 16:57:21.899975
2023-10-25 07:57:21.899979
2023-10-23 12:57:21.899981
2023-10-26 19:57:21.899984
2023-10-24 15:57:21.899987
2023-10-23 15:57:21.899990
2023-10-26 11:57:21.899993
2023-10-23 19:57:21.899995
2023-10-25 10:57:21.899999
2023-10-26 20:57:21.900001
2023-10-23 10:57:21.900003
2023-10-25 17:57:21.900006
2023-10-23 21:57:21.900009
2023-10-25 02:57:21.900011
2023-10-23 03:57:21.900014
2023-10-23 10:57:21.900017
2023-10-26 05:57:21.900020
2023-10-25 19:57:21.900023
2023-10-25 06:57:21.900026
2023-10-26 00:57:21.900029
2023-10-22 21:57:21.900031
2023-10-26 16:57:21.900035
2023-10-24 22:57:21.900037
2023-10-23 02:57:21.900040
2023-10-25 11:57:21.900043
2023-10-25 16:57:21.900046
2023-10-23 16:57:21.900049
2023-10-25 07:57:21.900052
2023-10-25 06:57:21.900055
2023-10-24 10:57:21.900058
2023-10-24 11:57:21.900060
2023-10-25 17:57:21.900063
2023-10-26 19:57:21.900066
2023-10-23 13:57:21.900069
2023-10-25 05:57:21.900072
2023-10-25 23:57:21.900074
2023-10-26 13:57:21.900077
2023-10-25 13:57:21.900080
2023-10-23 05:57:21.900083
2023-10-22 21:57:21.900085
2023-10-25 14:57:21.900088
2023-10-25 11:57:21.900091
2023-10-26 10:57:21.900094
2023-10-25 04:57:21.900097
2023-10-24 15:57:21.900099
2023-10-23 17:57:21.900102
Sizin paylaştığınız veri çerçevesine benziyor değil mi?
Kod için teşekkür ederim sizdeki veriler Yıl Ay Gün Saat Dakika Saniye cinsinde verilmiş. Bendekiler Gün Ay Yıl Saat ve Dakika cinsinde verildi. Bunun için yazdığım kod da “format=’%d.%m.%Y %H:%M’)” olarak belirtiyorum. Bilmediğim bir şey olabilir konuya çok hakim değilim kusura bakmayın. Ekstradan yanlış aktarmış olabilirim saat 17 ile 6 arasında olarak (17,18,19,20,21,22,23,00,01,02,03,04,05,06).
İlk attığınız kodu buna çevirerek denedim fakat hata alıyorum. Hatayı aşağıya bıraktım. Teşekkürler
time data “13.11.2023 00:18” doesn’t match format “%m.%d.%Y %H:%M”, at position 152. You might want to try:
- passing format if your strings have a consistent format;
- passing format='ISO8601' if your strings are all ISO8601 but not necessarily in exactly the same format;
- passing format='mixed', and the format will be inferred for each element individually. You might want to use dayfirst alongside this.
Yine hata alıyorum, çok uğraştırdım kusura bakma.
ValueError: to assemble mappings requires at least that [year, month, day] be specified: [day,month,year] is missing
Veriniz nasıl bir yapıda ki? Yani sizinle çalıştırabileceğiniz bir kod paylaştım. Deneyip sonuçları görebilirsiniz. Siz de benzer şekilde, çalıştırabileceğimiz ve sonuçları kendi gözlerimizle görebileceğimiz bir kod paylaşın lütfen. Ne tür bir veri üzerinde çalıştığınızı, nasıl bir kod yazdığınızı görmemiz sorunun çözümüne katkı sağlayabilir.
Sizde çalıştımı tam bilmiyorum ama bende tekrar hata veriyor attığınız kod da. Soruda kendi attığım kod işimi görüyor fakat veri atlıyor. Bir bakımıda onu çözmeye çalışıyorum.