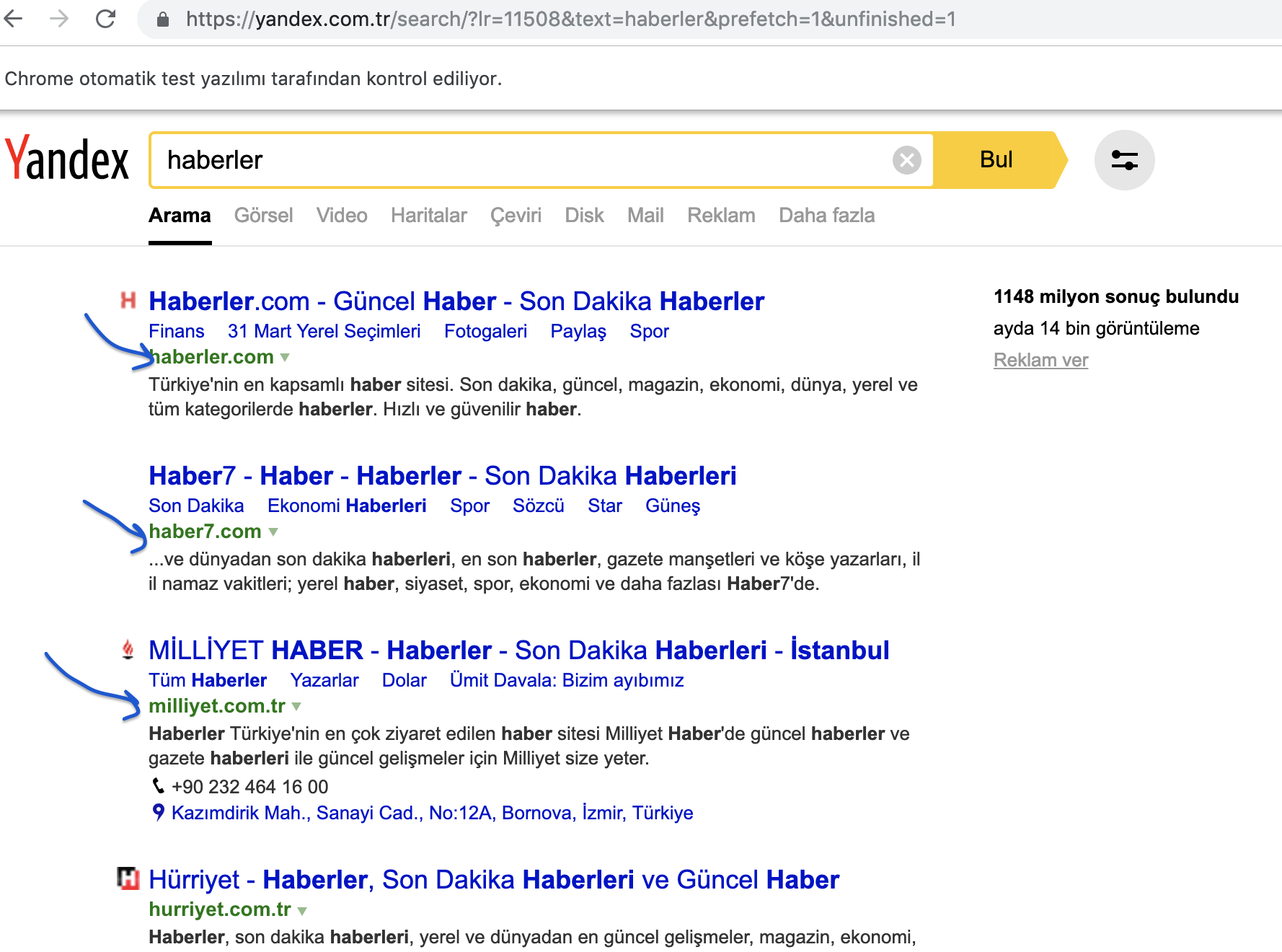
Merhaba arkadaşlar,
yandex ufak bir projem için python selenium ile gittim sayfadaki url, title vs gibi bilgileri tarayıcı üzerinde çekmek istiyorum bu konuda internette araştırdım fakat request yöntemi var yalnız ben selenium web browser ile gittiğim. sayfada iken çıkan sonuçtan almak istiyorum nedeni : selenium ile alınan bilgiye göre ilerleyeceğim ve aynı url tekrar kaydetmemek için veritabanına kaydedip karşılaştıracağım
seleniumda bu resme göre bir örnek url çekme kodu ve mantıgını yazabilrmisiniz ?
python3 ile aşağıdaki kodda Yandex search kadar gittim
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
chrome_options = Options()
chrome_options.add_argument(‘Mozilla/5.0 (iPhone; CPU iPhone OS 11_4_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15G77 [FBAN/FBIOS;FBAV/189.0.0.44.93;FBBV/124150883;FBDV/iPhone9,3;FBMD/iPhone;FBSN/iOS;FBSV/11.4.1;FBSS/2;FBCR/ClaroBrasil;FBID/phone;FBLC/pt_BR;FBOP/5;FBRV/124823384]’)
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.delete_all_cookies()
browser.get(‘https://yandex.com.tr/’)
browser.find_element_by_xpath('//input[@aria-label="Sorgu"]').send_keys("haberler" + Keys.RETURN)
time.sleep(2)