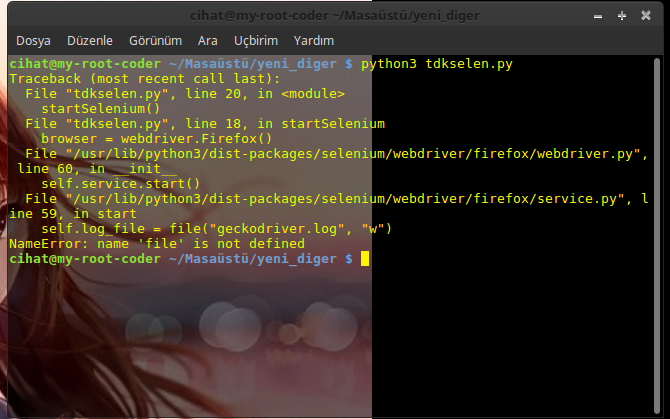
Merhabalar, tdk dan veri çekmeye çalışıyordum,amacım kullanıcıdan kelimeyi alıp tdk sitesinin veri tabanından anlamını çekmekti.Burada selenium kullanayım dedim,bana verdigi hata:
Bana biraz daha yardım edebilme imkanınız var mı?Gerçekten araştırdım, hala araştırıyorum,elime kayda deger pek bir şey geçmedi malesef.
Başka bir yol biliyorsanız anlatabilirseniz cidden çok sevinirim.Illa kod falan da olmayabilir,bu yolda kullanabilecegim kutuphane vb onerisi de olabilir, incelemekten çekinmem.
Adamlar nasıl site yapmışsa artık,istedigim veriyi çekemiyorum.(belki de ben beceriksizim)
Ben de başka şeyler bulabilirsem burada paylaşırım,belki buradan bir şey çıkar diye duşundum.
Selenium kullanmanız mecburi mi? HTTP isteği + gelen HTML verisini işleme yolu ile çözülemez mi? Engelliyor mu bu şekilde erişimi? Biraz baktım da belirli bir URL deseni yok ancak belirli bir URL’e POST atıyor, bununla birlikte çevrilmesi istenen metni gönderiyor. Bunun yanında bir de guid isimli bir query string parametresi gönderiyor. Bu guid’in gönderilen metin ile uyumlu olması gerek. Bunun nasıl üretildiğini anlamak için JS kodunu çözümlemek gerek. Maalesef daha ileri gidecek vakti bulamadım.
#-*-coding: utf-8-*-
import urllib
import urllib2
import re
url="http://www.tdk.gov.tr/index.php?option=com_gts&arama=gts&guid=TDK.GTS.5b3540b01b6e58.33593130" #sorgu URL'miz
postdata=urllib.urlencode({"kelime":"piton"})#aranacak kelime 'piton'. urllib kütüphanesinin urlencode methoduyla post verisine çevirliyor
req = urllib2.Request(url=url,data=postdata)#bir sorgu(request) gönderiliyor
cont = str(urllib2.urlopen(req).read()).replace("\n","")#kaynak kod okunuyor. replace mehodunu satırları kaldırmak için kullandım çünkü re'nin search methodu alt satıra geçmiyor
regex = r"</i></th></tr></thead>(.*?)</table>"#html'i parçalamak için regex cümlesi (kaynak kodda kelime anlamlarının olduğu kısım)
result = re.search(regex,cont)#regex aranıyor
result = result.group(1)
result = str(result.replace("\n","").replace("\r","").replace("\t",""))#alınan kısmı replace methoduyla düz bir metne çevirdim
regex2 = r"</i>(.*?)<br>"#kelime anlamalarını çekmek için regex cümlesi
mean = re.findall(regex2,str(result))#findall methoduyla tüm anlamlar liste olarak geri döndürülüyor
say = 1
for i in mean:
print str(say)+"-"+ i
say+=1
Buna benzer bir şey yapılabilir.Regex kullanmak istemezseniz alternatif olarak Beautiful Soup gibi html parçalamaya yarayan kütüphanelerde kullanılabilir veya urllib yerine requests gibi kütüphanelerde kullanılabilir.Kod bu haliyle kullanılamaz, sorun çıkaracaktır.Örneğin her kelimede kaynak kod aynı şekilde dönmeyecektir bu yüzden regex ile parçalarken istenmeyen kısımlar da ekrana yazdırılabilir.Kodu sadece fikir olması açısından yazdım.
Tam aksine hocam,selenium u pc ye kuramadım,vazgeçtim.Ben siteyi biraz inceledim,dediginiz gibi adamlar form etiketi altından belli bir yere kelimeyi yolluyor,donen sonucu aynı html sayfasında yazdırıyor,bir tane url var ama kelimeyi ne şekilde,nasıl yazdıracagımı şaşırdım gerçekten.
Dediginizi pek anlayamadım ama
kelime = "elma"
https://www.google.com.tr//search?q= + kelime
gibi onune kelime koyup sonucu çekebilecegim bir şekilde degil site.Adamlar sırf veri çekemesinler diye ugraşmış.
Yok veri çekebiliyorum ama arattırdıgım kelimenin anlamını alamıyorum.
Form etiketinin post attıgı yeri goremiyorum,nasıl bir script yapısı kullanmışlar anlamadım.
Canınız sagolsun.
İncelerim, çok teşekkurler, duzenleme de yapmaya çalışır, sonucu bildiririm.
RoboBrowser ile çok rahat yapılabilir istenilen işlem. Tek yapmanız gereken TDK’da kelime arama kutusuna sağ tıklayıp ögeyi denetle(incele) yapmanız ve gerekli form etiketlerini tespit etmeniz.
Çıktının dilimlenme sebebi tam olarak HTML tag’ine göre nasıl çıktı alacağımı bilmememden kaynaklı. Dilimlenmesi yüzünden çıktı yarıda kesilebilir veya gereksiz yazılar ekrana çıkabilir. Bir yolunu bilen varsa ve yaparsa daha sağlıklı olur o şekilde kullanmak. Yine de şimdilik tam sonucu veriyor.
bu selenium var ya gecko driver siz yapamaz, gecko driver ile selenium un aşkı yanında leyla ile mecnun halt etmiş
gecko driver kurulumu için şu linkte belirtilen adımları takip edin, hem firefox hem de chrome için anlatılmış, gecko driver kurulum
sonra da şu şekilde firefox u açmayı deneyin:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Firefox()
driver.get("http://www.python.org")
assert "Python" in driver.title
elem = driver.find_element_by_name("q")
elem.clear()
elem.send_keys("pycon")
elem.send_keys(Keys.RETURN)
assert "No results found." not in driver.page_source
driver.close()
O bende,o işin kolay yanı gibi gözüküyor,sadece arama sonucu da olsun da,tag ayırma sıkıntı degil.
Bir de selenium u sizin dediginiz gibi kurmayı deneyeyim.Biliyorum geckodriver lazım,ama linux un kendi deposunda sundugu bir paket degil,o yuzden ben kuramadım bunu, aslında kurdum ama sizin önerilerinize göre tekrar kurayım.Çok teşekkurler.
Sen reyissin yav,cidden allah razı olsun,allah izin verirse edebiyat hocama faydalı olacagım, çok teşekkürler, çıktı parserleme babı bende.Çözemedigim yer olursa burada sorarım.Cidden çok teşekkürler
Kolay gelsin