Aynı html dosyasını kullandığınızdan emin misiniz? 6 tane tablo yok diyor hatada.
from lxml import html
# HTML dosyasını aç
with open("python/deneme/c/deneme.htm", "r") as f:
html_content = f.read()
# HTML içeriğini parse et
tree = html.fromstring(html_content)
tables = tree.xpath("//table")
for table in tables:
print(30*"-",tables.index(table),"-"*30)
for row in table.xpath('.//tr'):
row_data = []
for cell in row.xpath('.//td'):
row_data.append(cell.text_content())
print('\t'.join(row_data))
bu kodu çalıştırır mısınız.
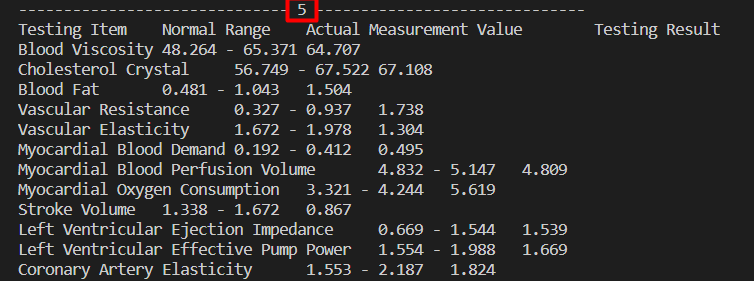
Bu bilgilerin yazılı olduğu yerden önce yazan sayı kaç.
Paylaştığım drive linkinden tekrar indirdim dosyayı ve yeni bir klasör oluşturup içinde çalıştırdım fakat sonuç [ ] verdi
Verdiği sayı nedir? (20 karakter)
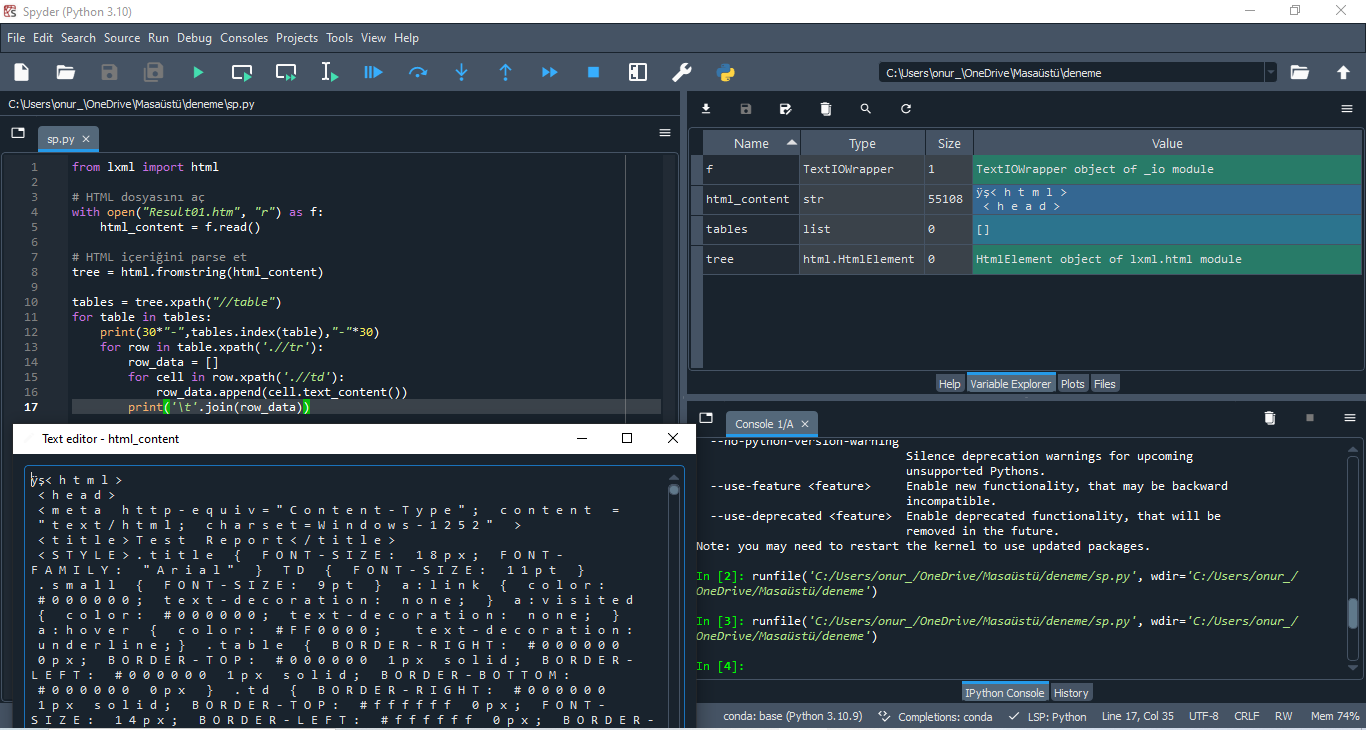
html dosyasında mı bozukluk oluyor sol altta html_content’ i büyüttüm, ancak öyle olsa sizde nasıl çalıştı
Şimdi drivedan dosyayı indirdiğim zaman bana da [] döndürdü ama drivedan içeriği kopyalayıp bir htm dosyasına yapıştırdığımda çalıştı. Anlamadım bende.
hocam dediğinizi de düşünerek şunları denedim; ilk önce Result01.htm dosyasının orjinalini metin belgesi ile açtım ve aşağıda UTF-16 LE yazdığını gördüm, hatanın buradan olabileceğini düşündüm ve bütün içeriği kopyalayıp yeni bir metin belgesine yapıştırıp sizin de ilk yaptığınız gibi dosyayı tekrar oluşturdum. Gördüm ki oluşturduğum dosya UTF-8 formatında oldu. Daha sonra sizin kodunuz ile denedim ve çalıştı, yardımcı olduğunuz için teşekkür ediyorum. @makalidap @BandoLero
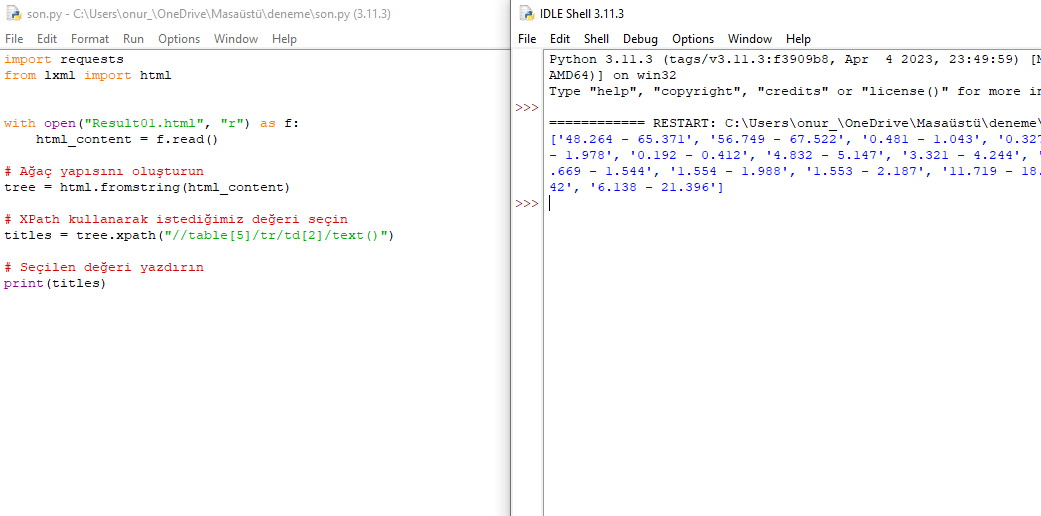
Anladım ki program bu html dosyalarını UTF-16 LE formatında üretiyor, bunu parse ederken UTF-16 LE ye göre parse etmem lazım değil mi?
Evet için bu satırı ekleyebilirsiniz
with open("python/deneme/c/avb.html", "r",encoding="utf-16") as f: