Merhaba,
Localde bir html dosyası var ve ben bu dosyayı python ile açıp içindeki bazı sayısal değerleri çekmek istiyorum. XPath alarak direk o değere ulaşmak istiyorum fakat hiçbir şekilde çıktı alamıyorum. Hep [] boş bir değer veriyor, bunu aşamıyorum. Yardımcı olabilecek olan varsa çok memnun olurum. Bu arada dosya html formatında da değil, htm formatında.(İlk aldığım hata .html yazdığımda dosyayı bulamamış olmasıydı, en sonunda .htm olduğunu gördüm ve dosya yoluna yazdığım uzantıyı .html den .htm ye çevirince düzeldi.)
kodu ekliyorum:
from lxml import html
# HTML dosyasını aç
with open("Result01.htm", "r") as f:
html_content = f.read()
# HTML içeriğini parse et
tree = html.fromstring(html_content)
# XPath kullanarak veri çek
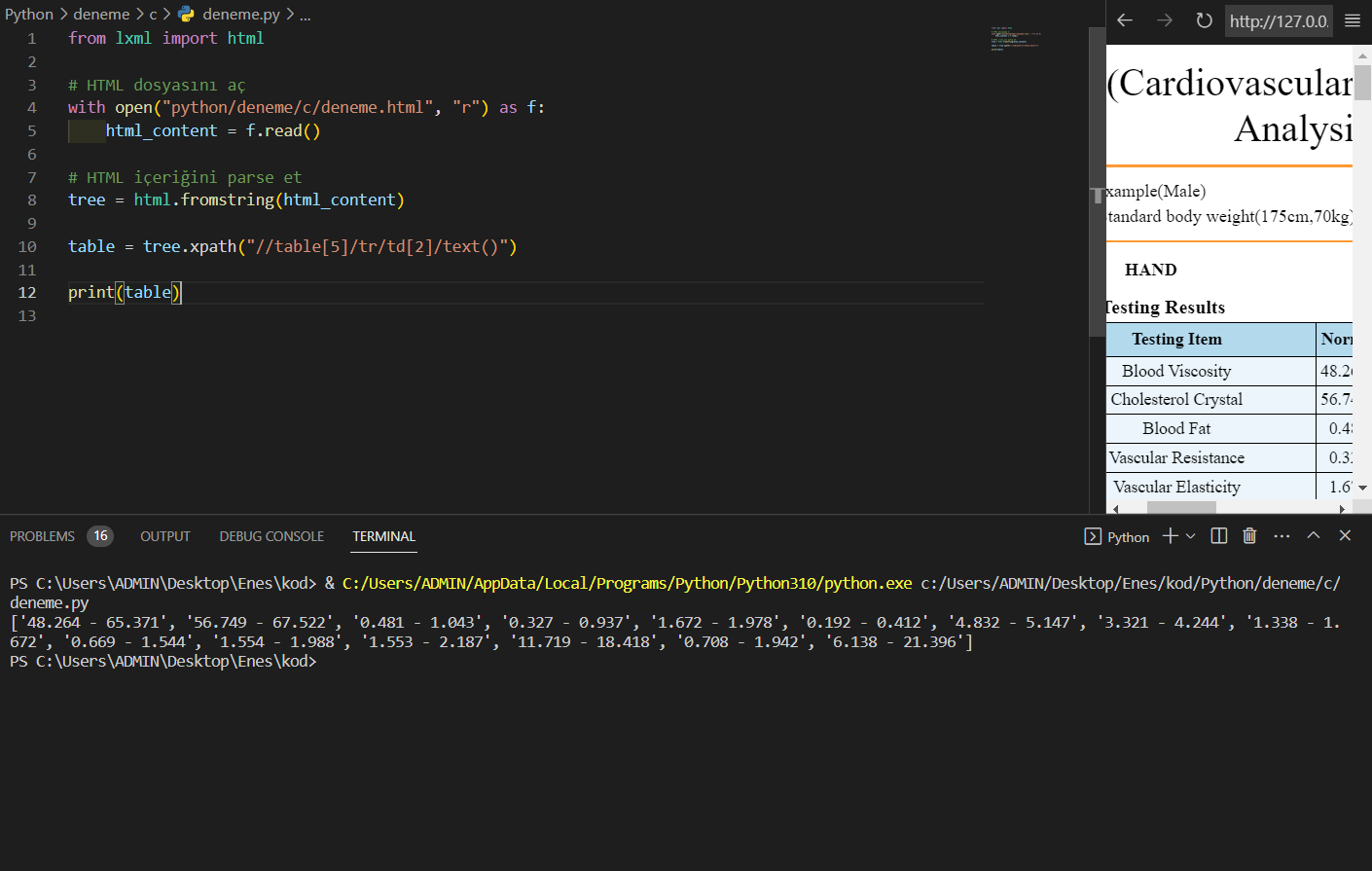
titles = tree.xpath("/html/body/table[5]/tbody/tr[1]/td[2]/text()")
# Sonuçları göster
print(titles)
ben olayı anlamadım. html dosyasının içinde ki verileri niye almaya çalışıyosun ? yani şunu neden yapmadın onu anlamadım. bu html dosyasını sunucuda çalıştırıp. requests ve bs4 ile çok basit istediğin veriyi çekersin ?
eğer sunucudan çekmeyeceksek, html dosyasından çekmenin de bi anlamı yok. txt dosyasından çek yani.
html dosyası statik değil, sürekli aynı şablonda farklı değerler ile oluşturuluyor.(aynı dosyaların üzerine yazılıyor) o yüzden xpath ile direk otomasyona bağlayabilirim diye düşündüm fakat bu düşüncelere de açığım. yardımcı olursanız sevinirim tabiki
yani senaryoyu bilmediğim için yorum yapmakta zorlanıyorum. siteden veri çekmeye mi çalışıyorsunuz ? o yüzden mi sitedeki html dosyasını indirip içinden alıyorsunuz ?
senaryo çok karışık hocam. bir program sürekli olarak Result01’ den Result40’ a kadar html formatında bir çıktı basıyor. ben ise bu html dosyalarındaki bazı değerleri çekmek istiyorum. bu dosyalar programa işlem yaptırdıkça basılıyor, yani statik değil sürekli aynı isimde değerler değişiyor. ben bu değerleri sürekli olarak yakalayıp çekmek istiyorum. dediğiniz yöntemi nasıl yapabilirim? sadece html sayfasından bir veri çekmeye çalışıyorum olarak düşünebilirsiniz
şöyle bişey yaptım. bitane oyun sitesinde ki href leri çekiyo. herhangi bişey de olabilirdi tabi. yani bu şekilde siteden veri çekseniz olmuyor mu ?
import requests
from bs4 import BeautifulSoup
select = BeautifulSoup(requests.get("https://clashofclans.fandom.com/wiki/Elixir_Troops").content, "html.parser").find("div", {"class":"flexbox-display bold-text hovernav"}).find_all("a", href=True)
for i in select:
print(i["href"])
bu şekilde attığım dosyadaki actual measurement ve normal range sütunlarını çeksem çok işimi görür ama nasıl yapabilirim, acaba table olduğu için mi çekemiyorum? yoksa dosya mı hatalı bilmiyorum
işte aynı mantık bu iki kütüphane ile yapıcaksın. drive a yüklediğin kod okunmamak için bir çaba sarf ettiğinden dolayı açıp geri kapattım requests ve bs4 kütüphanelerini öğrenirsen çok basit bi şekilde çekebilirsin.
tablo dan çekmesi daha kolay. çünkü sıralı yazıldığı için yani grid gibi. 1 tane for ile bütün veriyi çekersin. google da bununla ilgili milyör tane video var 1 2 tanesine bakarsan yaparsın diye düşünüyorum kolay gelsin.
Çalıştırabildiniz mi? Bir de belki işinize daha çok yarar diye bs4 ile de yazdım kodu:
from bs4 import BeautifulSoup
with open("python/deneme/c/deneme.htm") as fp:
soup = BeautifulSoup(fp, "html.parser")
table = soup.find_all('table')[5]
degerler = [ satir.find_all("td")[1].get_text() for satir in table.find_all("tr") ]
print(degerler)