Merhabalar,
Kendimi geliştirmek ve BeautifulSoup ile requests modüllerini kavramak için yaptığım bir uygulamada hatalar alıyorum ve sonuca ulaşamıyorum. Çok kez denedim fakat çözüme ulaşamadım. Uygulamanın amacı yazbel forumunda açılan son konuları çekmek. Fakat kodumda “find()” ve “.text” komutlarına hata alıyorum. Yardımcı olabilecek arkadaşlar varsa çok sevinirim, saygılarımla.
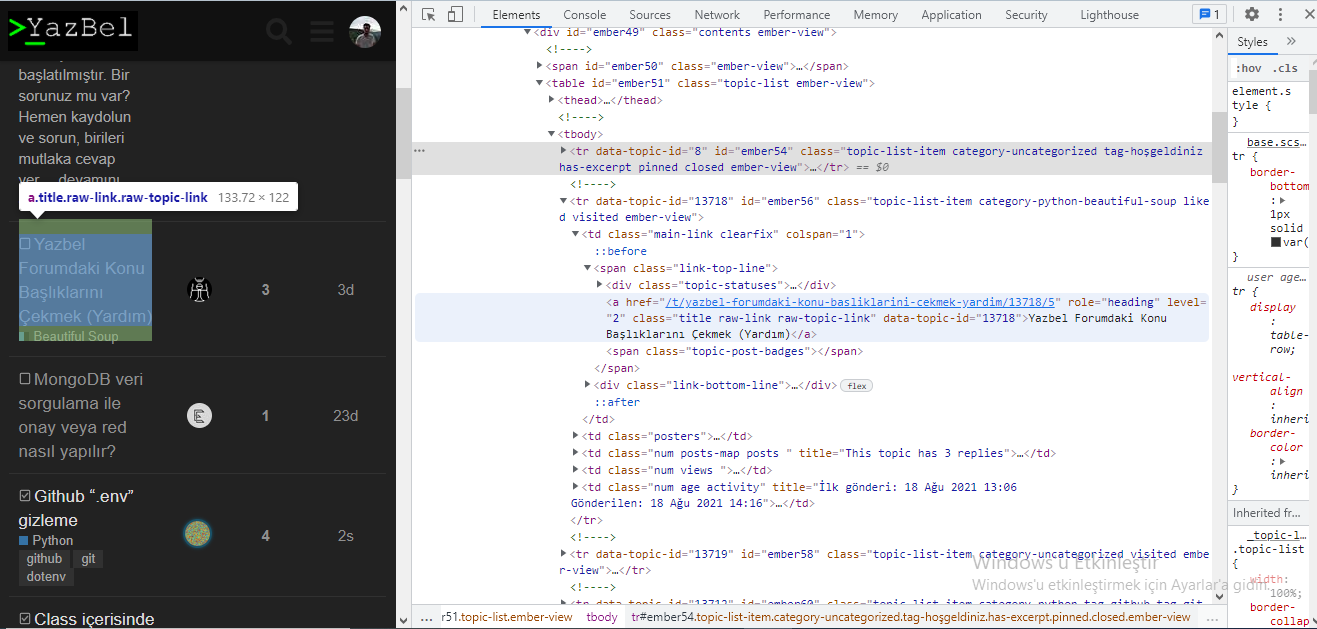
Evet, birincisi none değeri döndürdüğü için ikincisi hata veriyor. Bir konunun başlığını çekmeye çalıştım fakat çekemedim. Koddaki tablo yerine div veya spanları seçsem de “Yazbel forumuna hoşgeldiniz” ifadesini biçimlendirilmemiş bir şekilde çekmekten öteye gidemedim. Amacım herhangi bir konunun başlığını çekmek idi. Benim kodumu bir kenara bırakarak nasıl çekebiliriz onu da öğrensem yeterli, cevap için teşekkürler.
Belirttiğiniz meta taglerini bulamadım, yanlış yolda mıyım? Ekran görüntüsündeki yoldan gitmeyi denemiştim fakat başarısız oldum. Nasıl bir yol izlemem lazım?
Bu şekilde yaptığımda çalışıyor ve find() kullandığımdan ilk bulduğu sonucu alıyor, text e çeviriyor. Fakat find_all() yaptığımda kod çalışmıyor ve hata veriyor;
Traceback (most recent call last):
File "C:\Users\onur_\OneDrive\Masaüstü\web-scrap.py", line 10, in <module>
soup1 = soup.find_all("td",{"class":"main-link"}).a.text
File "C:\Users\onur_\AppData\Local\Programs\Python\Python39\lib\site-packages\bs4\element.py", line 2173, in __getattr__
raise AttributeError(
AttributeError: ResultSet object has no attribute 'a'. You're probably treating a list of elements like a single element. Did you call find_all() when you meant to call find()?
Çalışıyor fakat “.a.text” eklemeden çalışıyor. Onları eklemeden çalıştırdığımda ise 602 satır çıktı alıyorum. Bunu ayıklamak için “a.text” eklediğimde ise hata alıyorum.
Cevaplarınız için teşekkür ediyorum, liste şeklinde döngü içerisinde çekince hata çözüldü.
from bs4 import BeautifulSoup as bs
import requests
import re
url = "https://forum.yazbel.com"
html_content = requests.get(url).text
soup = bs(html_content,"html.parser")
soup1 = soup.find_all("td",{"class":"main-link"})
liste = [1,2,3,4,5,6,7,8,9,10]
for i in liste:
print(soup1[i].a.text)
Şuan son 10 konuyu çekmeyi başardım, yardımcı olan herkese teşekkür ederim.