Merhaba. Forumda yaklaşık 2 haftadır aktifim. Aktif olduğum süre boyunca genellikle Web Scraping ile alakalı sorulara yanıt verdim. Konu hakkında da pek çok soru sorulduğunu gördüm. Mevcut işim dolayısıyla Web Scraping ile çok uğraşıyorum ve bu konuda belirli bir seviyeye geldim diyebilirim. Boş vaktim bulunduğundan foruma geniş bir Web Scraping konusu kazandırmak istedim. Konu biraz uzun olacak, dolayısıyla tek seferde bildiğim her şeyi yazmayacağım -ki neyi bildiğimi hatırlayamam da zaten- bu yüzden şimdilik aklımda olanları yazacağım. Ayrıca ilerleyen zamanlarda aklıma yeni konular gelirse direkt olarak bu konuya yazacağım.
Ayrıca bu konu python, bs4, selenium ya da başka bir teknoloji öğretmeyi amaçlamayacak. Genel olarak web scraping inceliklerini (bildiğim kadarıyla) sizlere anlatacağım.
API Scraping
Benim kişisel olarak en sevdiğim scraping metodudur. Websitesi bir API ile haberleşiyorsa bu haberleşme tarayıcımızdaki Developer Tools’a düşer. Daha önce yine forumdaki bir arkadaş için hazırladığım bir scraper üzerinden konuyu anlatacağım.
Websitemiz bkmkitap.com olacak. Normalde muhtemelen pek çoğunuzun yapacağı gibi Selenium ile siteye gideriz. sayfa kaynağını bs4 ile parse edip verileri alırız ancak çok daha kolay bir yolu var. Öncelikle siteye gidiyoruz ve developer tools’u açıyoruz (CTRL+Shift+I ya da F12).
Daha sonra üst sekmeden Network (Ağ) sekmesine geliyoruz. Seçeneklerde Preserve Log ve Disable Cache’i işaretliyoruz. Türkçelerini bilmiyorum maalesef. SS’ten bakıp yapabilirsiniz.

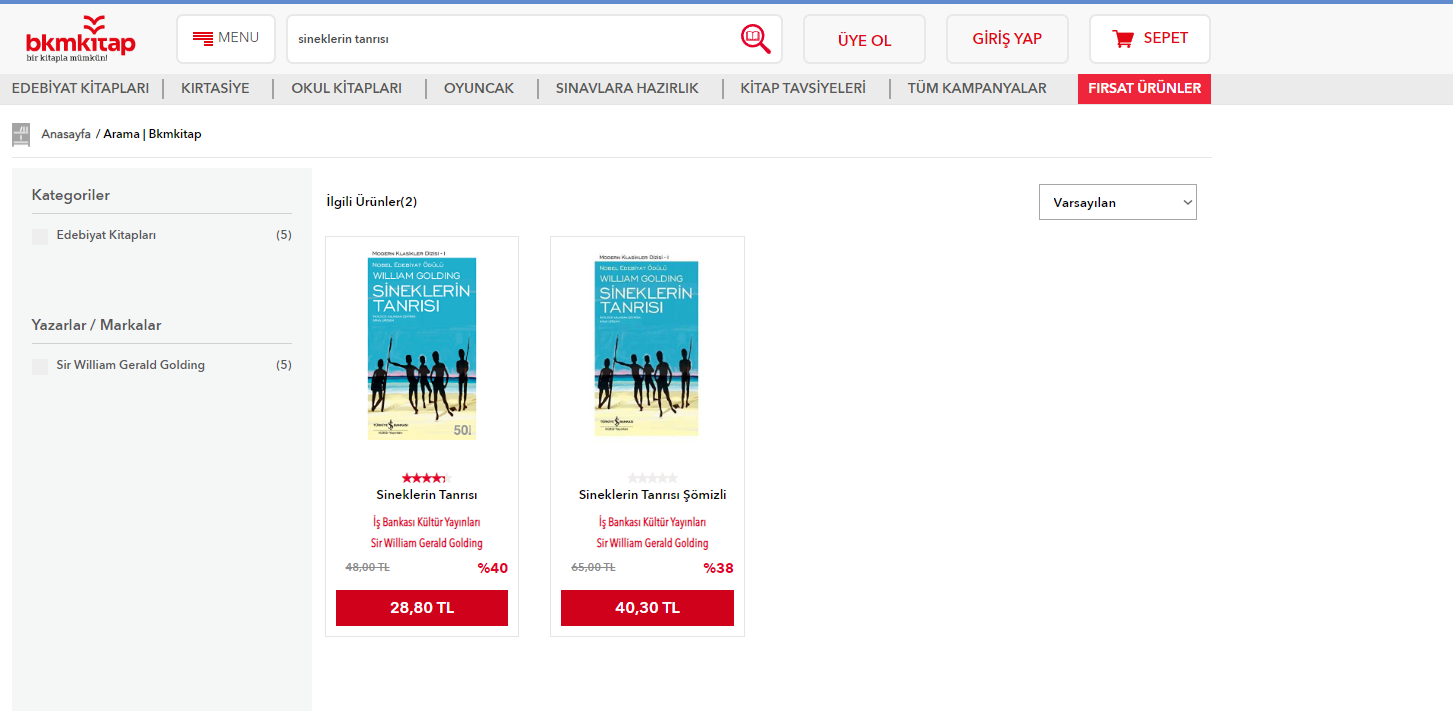
Sitede basit bir arama yapıyoruz. Aramamız örnek olması için Sineklerin Tanrısı olacak. Aramayı yapınca developer tools’a bir şeylerin dolduğunu göreceksiniz.
Ayrıca arama metnini yazdıktan sonra (Sineklerin Tanrısı) arama butonuna tıklamadan önce
 sol alttaki kırmızı butonun yanındaki butona tıklayarak mevcut listeyi temizleyin. Aramanız kolaylaşacaktır.
sol alttaki kırmızı butonun yanındaki butona tıklayarak mevcut listeyi temizleyin. Aramanız kolaylaşacaktır.
Ayrıca bende seçili olan Fetch/XHR’ı seçmeniz yararınıza olacaktır. API haberleşmelerini bu butonla filtreleyeceğiz ve karmaşıklık yaratan gereksiz şeyleri görmeyeceğiz.
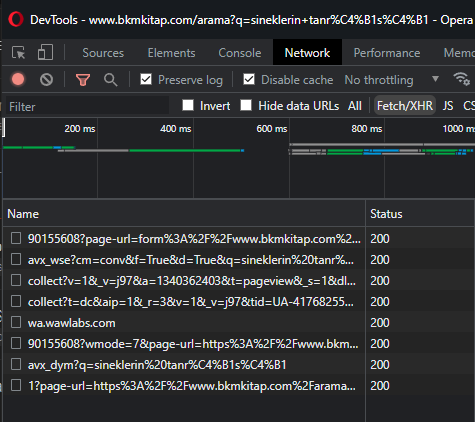
Buraya dolanları tek tek kontrol ediyoruz. örneğin en baştakine tıklayıp içeriğine bakalım.
Tıkladıktan sonra ilk başta direkt olarak Preview ya da Response kısmına tıklayıp içeriğine bakmamız yeterli olacak.
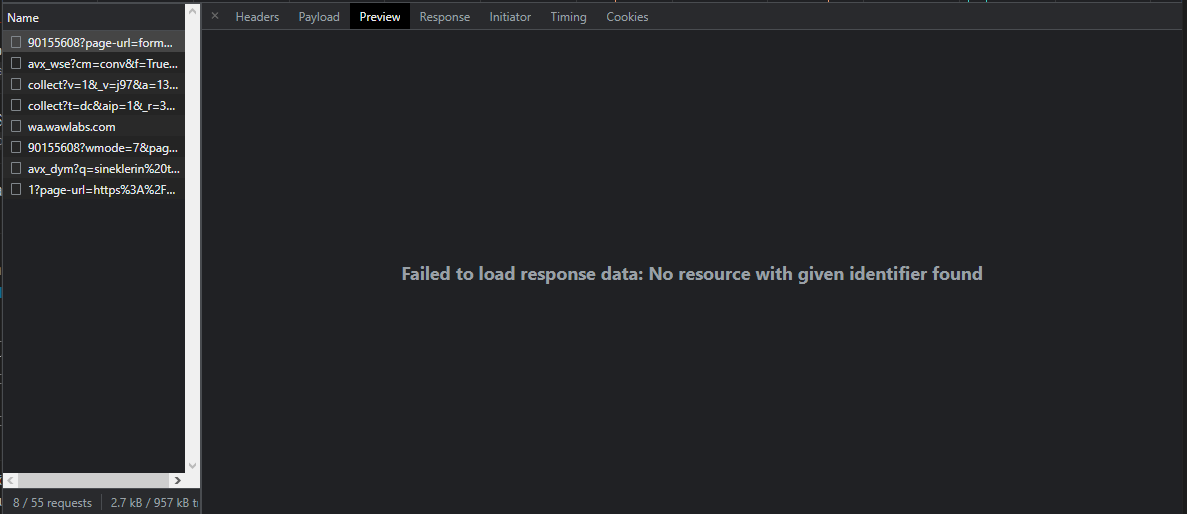
İçerisinde hiçbir şey yok. Dolayısıyla işimize yarayacak bir bilgi de yok.
Listedeki ikinci url’e tıklıyorum.
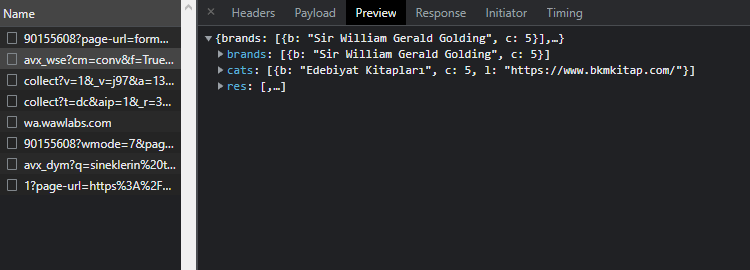
görüldüğü üzere işimize yarayacak şeyler var gibi görünüyor.
Brands’e tıkladığımda yazarın geldiğini görüyorum. Cats’de kategoriler var. res’in içine bakalım.
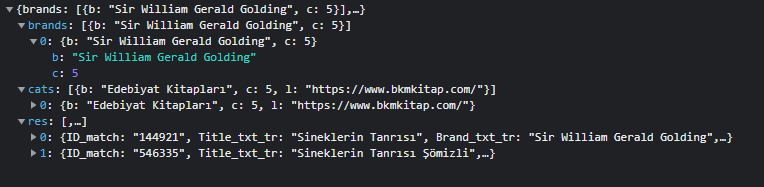
sanırım aradığımız şey res içerisinde. yani API scraping’e müsait bir websitesi var elimizde. Bunu anladığımıza göre API’a istek atmak için gerekli olan verilere bir bakalım.
Preview seçtiğimiz sekmede Headers’a geliyoruz.
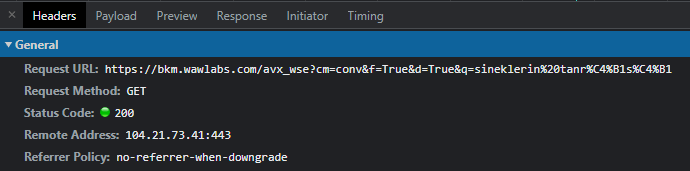
görüldüğü üzere request methodumuz GET yani payload tanımlamamıza gerek yok. Genelde payload yoksa üst sekmede gözükmez fakat query string parameter varsa payload sekmesi görünebilir. Query String Parameters istek atılan urlden de verilebildiği için payload sekmesine aslında ihtiyacımız yok ama okuma kolaylığı açısından oradan yapacağız.
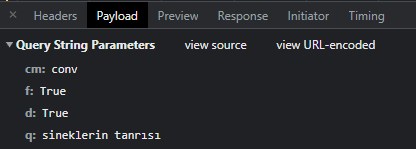
cm: conv, f: True, d:True. bu parametrelerin ne işe yaradığını bilmiyoruz. pek bizimle alakalı da görünmüyor ama yine de burada olduğu gibi kullanacağız. bizim için önemli olan q parametresi. kitap sorgumuz burada yazıyor ve biz de kodumuzda buraya istek atacağız. Konuya başlarken de dediğim gibi bu konu bir teknoloji öğretmeyi amaçlamayacak. Sadece incelikleri ve alternatifleri öğreneceğiz.
Daha önce yine forumda yazdığım kodu direkt olarak buraya yapıştıracağım
import requests
import json
class BkmKitap:
def __init__(self, book_title):
self.book_title = book_title
def get_books(self):
data = {
"cm":"conv",
"f":True,
"d":True,
"q":self.book_title
}
r = requests.get("https://bkm.wawlabs.com/avx_wse", params=data)
return r.text
def parse_books(self):
books = self.get_books()
jsonify = json.loads(books)
results = []
for book in jsonify["res"]:
result = {}
result["book_title"] = book["Title_txt_tr"]
result["book_author"] = book["Brand_txt_tr"]
result["book_price"] = book["Price_txt_tr"]
result["book_sale_price"] = book["Sale_Price_txt_tr"]
result["book_publisher"] = book["Publisher"]
result["book_rating"] = book["Rating"]
results.append(result)
return results
if __name__ == "__main__":
book_input = input("Kitap adı giriniz: ")
data = BkmKitap(book_input).parse_books()
print("--SORGU SONUCU GELEN KİTAP BİLGİLERİ--")
for i in data:
print(f"Kitap Adı: {i['book_title']}\nKitap Yazarı: {i['book_author']}\nKitap Fiyatı: {i['book_price']}\nKitap İndirimli Fiyatı: {i['book_sale_price']}")
print(f"Yayımcı: {i['book_publisher']}\nKitap Puanı: {i['book_rating']}\n")
Basit API scraping bu şekilde yapılabilir. Daha zorları ve komplikeleri karşınıza gelebilir ancak hangi durumlarla karşılaşacaksınız bilemediğimden tüm bu durumları yazmak zor.
API scraping Captcha sorgusunu aşmak, daha hızlı veri getirmek, kaynak kullanımını azaltmak gibi konularda bize avantaj sağlıyor.
Selenium’u olabildiğince az kullanmaya özen göstermeliyiz.
Bunun sebebi Selenium’un bir tarayıcı olması. Web sitesinde sizin işinize yaramayacak bir sürü kaynağı indiriyor. Siz içerisinden 10 tane kitap ismi ve yazarı alacağım diyorsunuz fakat o kitap fotoğrafları, diğer önerilen kitaplar, bir çok javascript dosyası, CSS dosyaları ve fontlar gibi işinize yaramayacak bir sürü şey indiriyor. Bu sebeple 10 saniyede scrape edeceğiniz siteyi dakikalarca scrape etmekle uğraşıyorsunuz. buradaki süreyi hazır yazılmış kodun çalışma süresi olarak yazdım. kod yazma kısmı api scraping’de bazen daha uzun sürebiliyor. Bizzat şahit olduğumdan biliyorum.
(Kısa not: Selenium ile image, css, js dosyalarını indirmeyi engelleyebiliyoruz fakat yine de selenium bir tarayıcı çalıştıracağından kaynak kullanımı yüksek olacaktır.)
Her neyse konumuz dönersek. Selenium’u olabildiğince az kullanacağız dedik. Sebebini anlattık fakat hangi durumlarda selenium’u kullanacağız hangi durumlarda kullanmayacağız bundan bahsetmedik.
Buna karar verebilmek için yine sitemize gidip Developer Tools’u açıyoruz. Benim gittiğim link: https://www.bkmkitap.com/arama?q=sineklerin+tanrısı bu link olacak. siz de farklı farklı sitelerde deneyebilirsiniz.
Developer Tools’u açtık. Şimdi CTRL+SHIFT+P yapıyoruz ve çıkan input box’a javascript yazıyoruz.
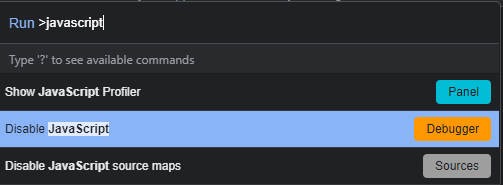
Disable JavaScript’e tıkladıktan sonra sayfayı yeniliyoruz. (Disabled olup olmadığını tekrar CTRL+SHIFT+P yapıp yine javascript yazıp anlayabilirsiniz. Eğer Enable JavaScript yazıyorsa Disabled olmuş demektir)
görüldüğü üzere sayfa içeriği JavaScript’i kapatmamıza rağmen doldu. Yani aslında Scraping için Selenium’a ihtiyacımız yokmuş.
Şimdi tam tersi bir durumu deneyelim.
Gideceğim link https://getir.com/en/category/beverages-j5085pzlJo/ olacak. Siteye gittim, developer tools’u açtım yine disable javascript yaptım ve sayfayı yeniledim.

görüldüğü üzere sayfa yüklenmiyor çünkü içeriği javascript ile dolduruluyor.
NOT: Getir API ile haberleşiyor. Eğer scraper yapmak istiyorsanız direkt olarak api scraping yapabilirsiniz. sizin için de güzel bir antrenman olur. Hatta getir scraper’ı için güzel bir trick var. Belki bir fark eden çıkar ![]()
Kısaca bizim için adımlar şu şekilde olmalı:
- Site API ile haberleşiyor mu? Eğer haberleşiyor ise API Scraping yap. Haberleşmiyorsa 2. adıma geç
- Site içeriği javascript ile mi doluyor? Eğer javascript ile dolmuyorsa python requests kütüphanesi ile sitenin HTML kaynağını al. bs4 ile parse edip verileri çek. Eğer javascript ile doluyorsa 3. adıma geç.
- Selenium ile siteye git. HTML kaynağını bs4 ile parse edip verileri çek.
Site API ile haberleşiyor ama Post isteği atıyor.
Aslında en çok bu durumla karşılaşıyoruz. Yani genelde method post oluyor.
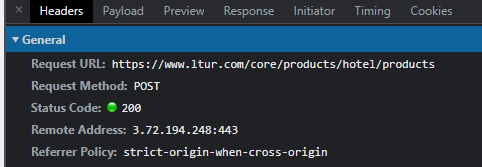
Bunun için örnek olarak ltur.com a gideceğim.
Örneğin buradan bazı özel durumlara göre otel listesi almak istiyoruz ama methodumuz post. Yine developer tools’u açıyoruz ve basit bir arama yapıyoruz. Ben rastgele bir tarihte 2 kişilik tatil için Türkiye otelleri aramasını yaptım.

Suchen (Search) butonuna basmadan önce dev tools açık olduğundan emin oluyorum ve butona tıklıyorum.
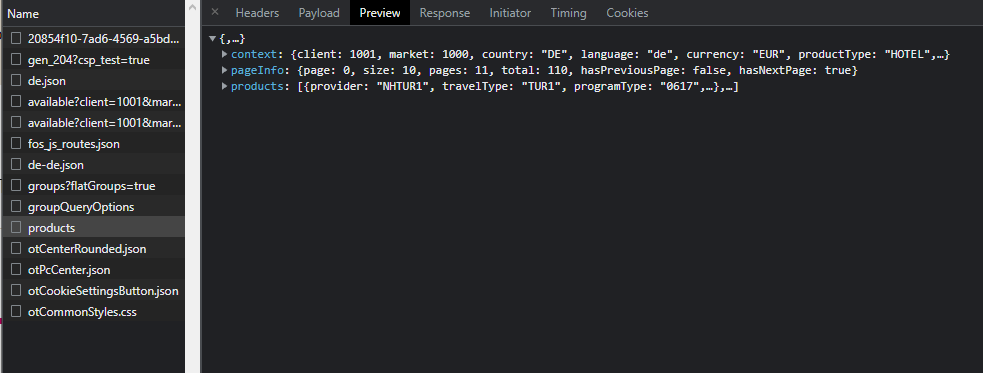
listedeki products’a tıkladığımda işime yarayacak gibi duran bir şeyler olduğunu görüyorum ve araştırmaya başlıyorum. products içerisindeki products’a ve onun içindeki 0’a giriyorum. Listede hotel diye bir şeyin olduğunu gördüm. buna da tıklıyorum çünkü işime yarayacak veri bu mu emin olmam gerekiyor.
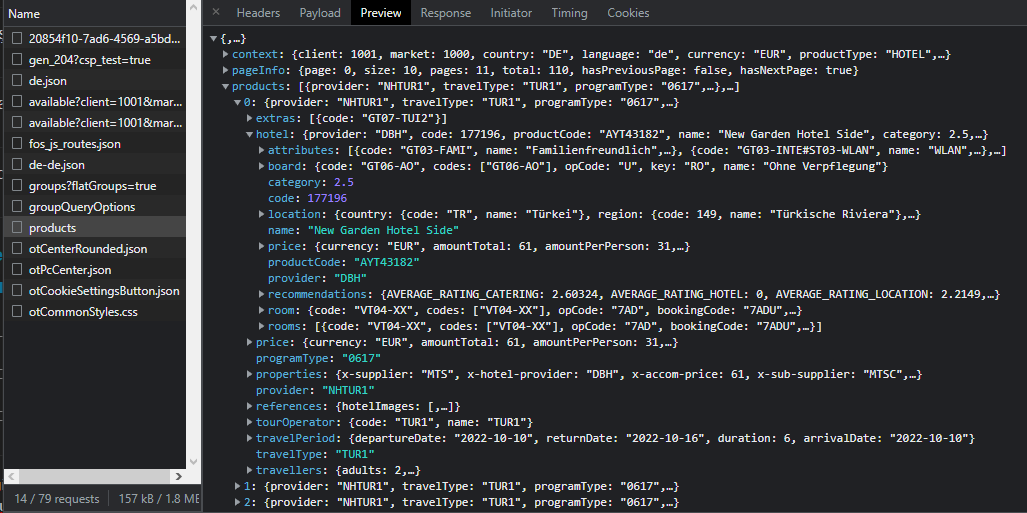
name kısmında New Garden Hotel Side yazıyor.Site ile karşılaştırıyorum. Acaba gerçekten sıfırıncı indexteki yani 1. sıradaki otel gerçekten bu mu ona bakacağım.
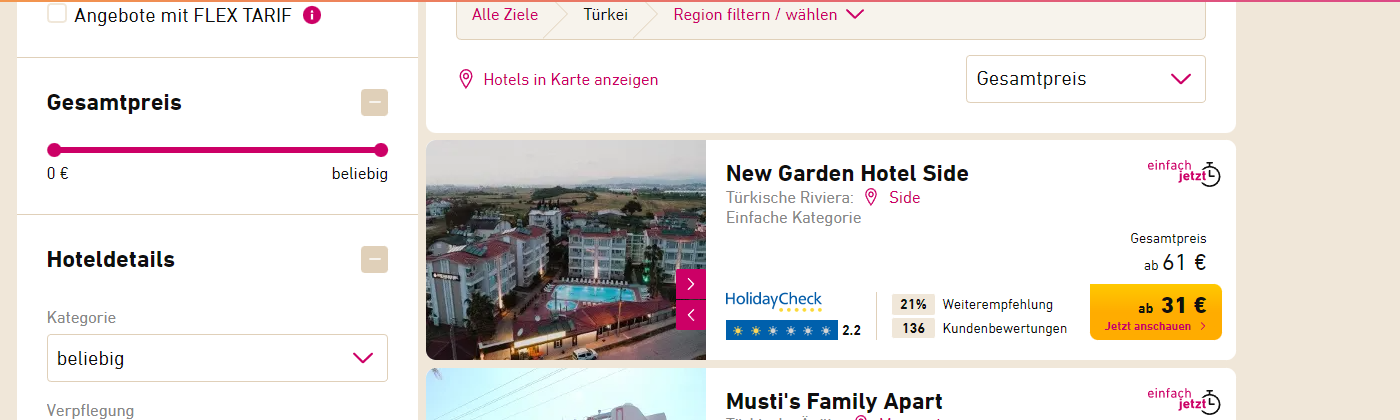
Verilerin uyuştuğunu gördüm. Demek ki doğru yerdeyim. Ancak bu sefer payloadda farklı şeyler var ve anlıyorum ki aslında aramayı bu payload’a göre yapmış. 2 adult yani 2 kişilik olduğu bilgisi burada, gidiş geliş tarihi burada hatta pagination bilgisi bile burada. Yani payload’ı manipule ederek farklı aramalar da yapabilirim anlamına geliyor.
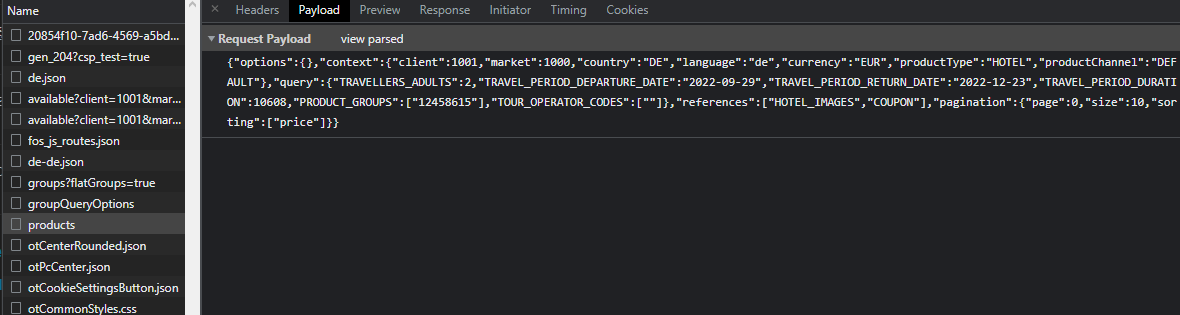
Request URL’e payload tanımlamadan post atarsanız hata verecektir. Çünkü sizin hangi verileri istediğinizi bilmiyor olacak.
Şimdi basitçe bunun kodunu yazalım. Payload’ı hiç değiştirmeyeceğim.
import requests
data = {"options":{},"context":{"client":1001,"market":1000,"country":"DE","language":"de","currency":"EUR","productType":"HOTEL","productChannel":"DEFAULT"},"query":{"TRAVELLERS_ADULTS":2,"TRAVEL_PERIOD_DEPARTURE_DATE":"2022-09-29","TRAVEL_PERIOD_RETURN_DATE":"2022-12-23","TRAVEL_PERIOD_DURATION":10608,"PRODUCT_GROUPS":["12458615"],"TOUR_OPERATOR_CODES":[""]},"references":["HOTEL_IMAGES","COUPON"],"pagination":{"page":0,"size":10,"sorting":["price"]}}
r = requests.post("https://www.ltur.com/core/products/hotel/products", json=data)
print(r.json())
kodumu yazıp çalıştırdım ama hata aldım. Hata şu şekilde:
{
"metaData" : {
"responseId" : "9763e43d-78c3-44aa-8d8a-1c6286897d50",
"items" : [ {
"message" : "Content type 'application/x-www-form-urlencoded' not supported",
"severity" : "ERROR",
"errorDetail" : "Exception Message: Content type 'application/x-www-form-urlencoded' not supported",
"errorType" : "org.springframework.web.HttpMediaTypeNotSupportedException"
} ]
}
}
sebebi ise gerekli header’ları vermemem. bunun için hemen birkaç gerekli olabilecek header’ı yazıyorum. Tabii ki developer tools’daki headers sekmesine bakarak. Burada dikkat etmeniz gereken request headers’a bakmanız. response header değil yani.
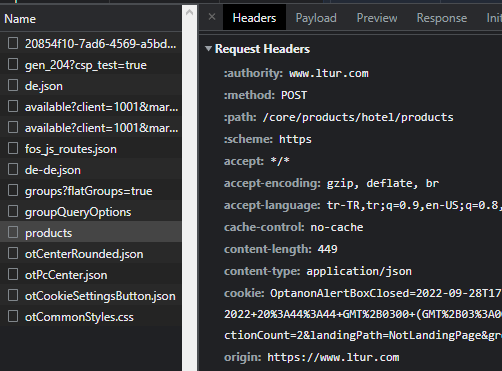
en üstte request headers yazdığını görebilirsiniz.
Şansımıza site bize hangi header’ın eksik olduğunu söyledi ama söylemeyebilirdi de. Böyle bir durumla karşılaşırsanız gerekli olan headerları kendiniz bulmanız gerekebilir. Bu durumda gerekli header content-type headerı. content-type’a application/json vermem gerekiyor. hemen onu da yazıyorum ve çalıştırıyorum. burada ne olur ne olmaz diye user-agent da verdim.
import requests
site_headers = {"content-type":"application/json","user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 OPR/90.0.4480.84"}
data = {"options":{},"context":{"client":1001,"market":1000,"country":"DE","language":"de","currency":"EUR","productType":"HOTEL","productChannel":"DEFAULT"},"query":{"TRAVELLERS_ADULTS":2,"TRAVEL_PERIOD_DEPARTURE_DATE":"2022-09-29","TRAVEL_PERIOD_RETURN_DATE":"2022-12-23","TRAVEL_PERIOD_DURATION":10608,"PRODUCT_GROUPS":["12458615"],"TOUR_OPERATOR_CODES":[""]},"references":["HOTEL_IMAGES","COUPON"],"pagination":{"page":0,"size":10,"sorting":["price"]}}
r = requests.post("https://www.ltur.com/core/products/hotel/products", json=data, headers=site_headers)
print(r.json())
kodun çıktısı tam olarak dev tools, preview’da gördüğümüz ile aynı.
şimdi bu çıktı üzerinden python kodlarımı yazarak istediğim verileri alabilirim. hatta belki bir yerde bu otellerin ID’leri vardır. bu IDleri bir yere kaydederim ve istediğim otel için istediğim tarihte satın alabileceğim oda var mı onun sorgusunu bu idye göre atarım ve istediğim verileri alabilirim. (Aslında “belki” değil, böyle bir şey mümkün. Biraz kurcalayarak o yöntemi bulabilirsiniz ![]() )
)
Kodu buraya yazmayacağım. istek atmayı öğrendik. ilk paylaştığım bkmkitap kodunda da gelen sonucu parse etmeyi öğrendik. bu yüzden kod kısmı artık size kaldı.
Şimdilik burada bırakıyorum. Bu kadar yorucu olacağını düşünmemiştim. Vaktim oldukça konuyu düzenleyip yeni yöntemler eklemeye çalışacağım. Herkese kolay gelsin.